[Kernel-based Learning] Theoretical foundation
본 포스트는 고려대학교 산업경영공학부 강필성 교수님의 Business Analytics 강의를 정리한 내용입니다.
Kernel-based learning의 기본적인 개념에 대해 알아보자.
Shatter
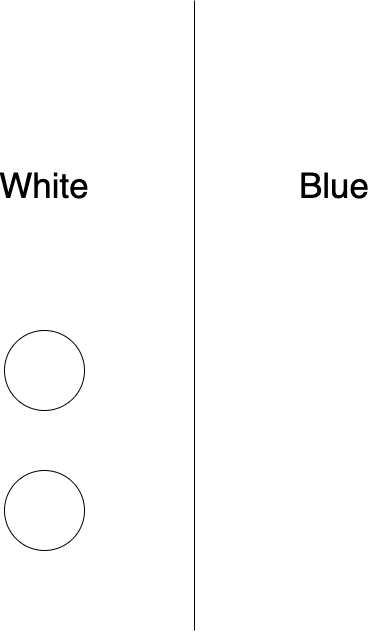
만약 2차원 평면에 점이 1개가 있다고 하자.
기준선을 기준으로 왼쪽이면 흰색, 오른쪽이면 파란색이라고 하면 점 1개는 아래와 같이 총 2가지 경우의 수를 갖는다.


만약 점이 2개라고 하면 다음과 같은 경우의 수를 갖는다.


모두 파란색, 흰색 또는 각 흰색, 파란색 총 4개의 가짓수를 갖는다. (모든 점은 독립)
점이 3개면 다음과 같이 8개의 경우로 나눌 수 있다.
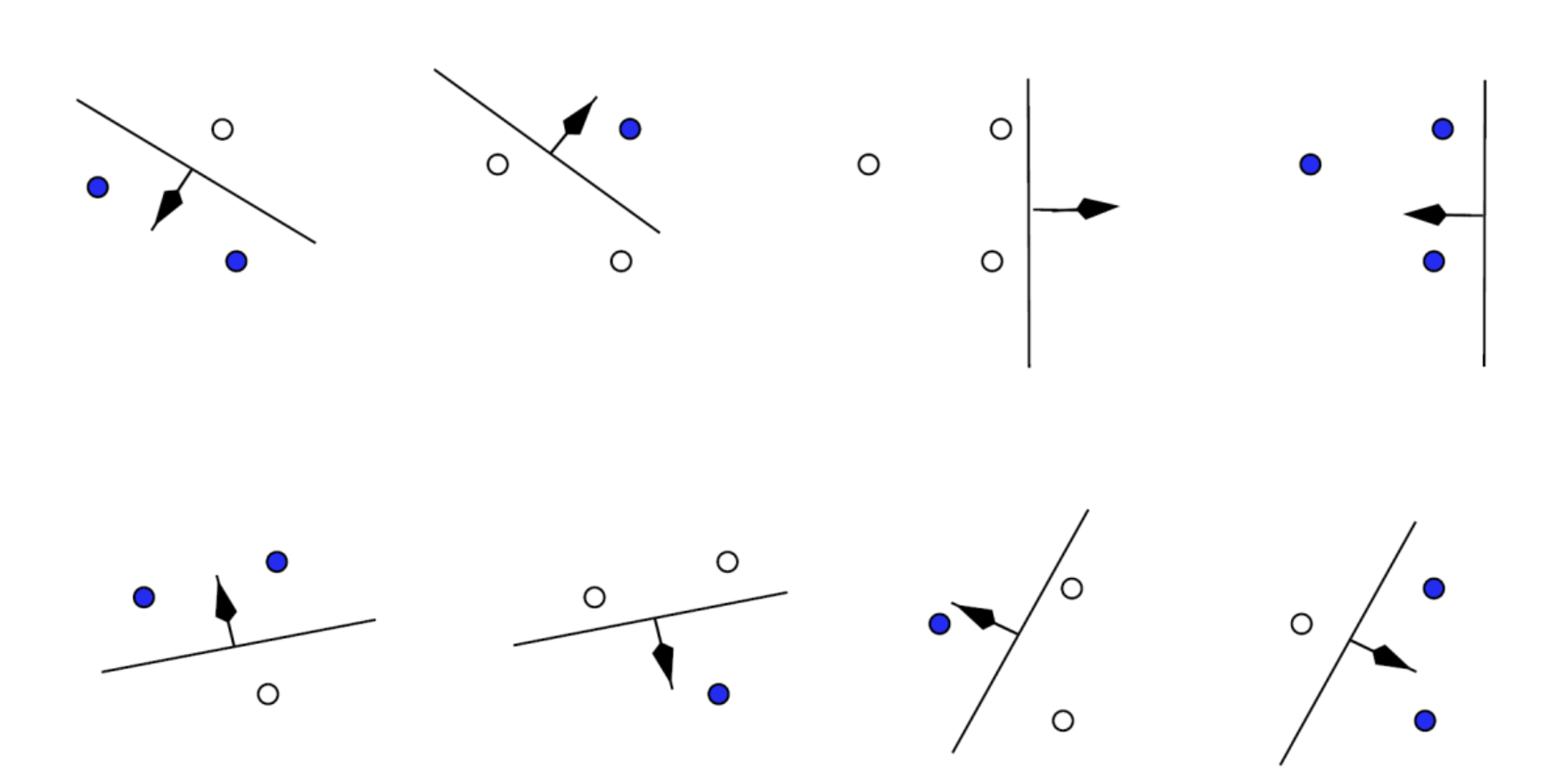
만약 점 4개면 어떻게 될까? 점이 4개인 경우에는 xor problem으로 인해 직선 1개로는 분류를 할 수 없다.

Shatter를 할 수 있다는 것은 함수 $F$에 의해 $n$개의 point는 임의의 +1 또는 -1을 target value러 하는 분류 경계면의 생성이 가능하다는 말이고, 만약 차원이 $d$라고 하면, 최대 $d+1$개까지 shatter가 가능하다.
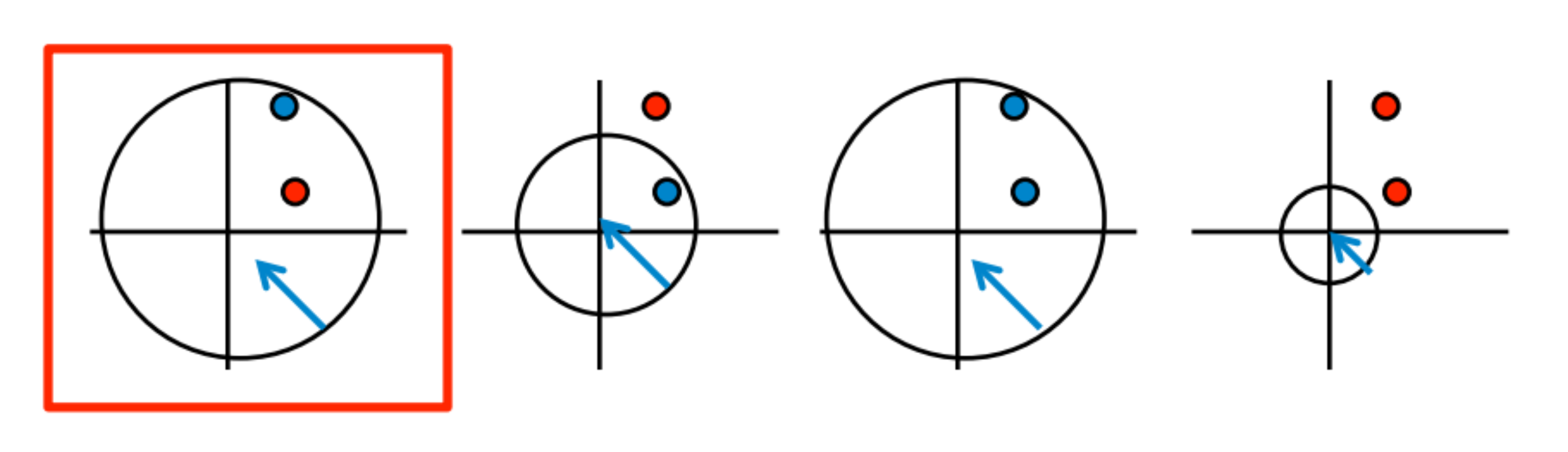
우리는 직선 분류기로 예를 들었지만, 만약 위 그림과 같이 circle 분류기 일 경우에는 2차원에서 2 point를 커버할 수 없다. 무조건 $d+1$개를 커버한다는 말은 아니다.
VC Dimension
VC dimension은 어떤 분류기의 capacity를 측정하는 지표이다. 다른 말로 expressive power, richness 등등으로 불린다.
대부분의 CNN에서 hidden node의 개수가 높을 수록 model의 복잡성이 높아지고, 성능도 높아진다. VC dimension은 최대로 shatter 할 수 있는 point의 수이고, 만약 2차원에서 1, 2, 3개의 점에서 shatter가 가능하다면 3이 VC dimension이다.
VC dimension의 최대 개수 또한 $d+1$이다.
SRM
SRM은 Structural Risk Minimization의 줄임말이고, 2000년 대 중반까지 커널 머신 시대일 때 많이 사용되었다.
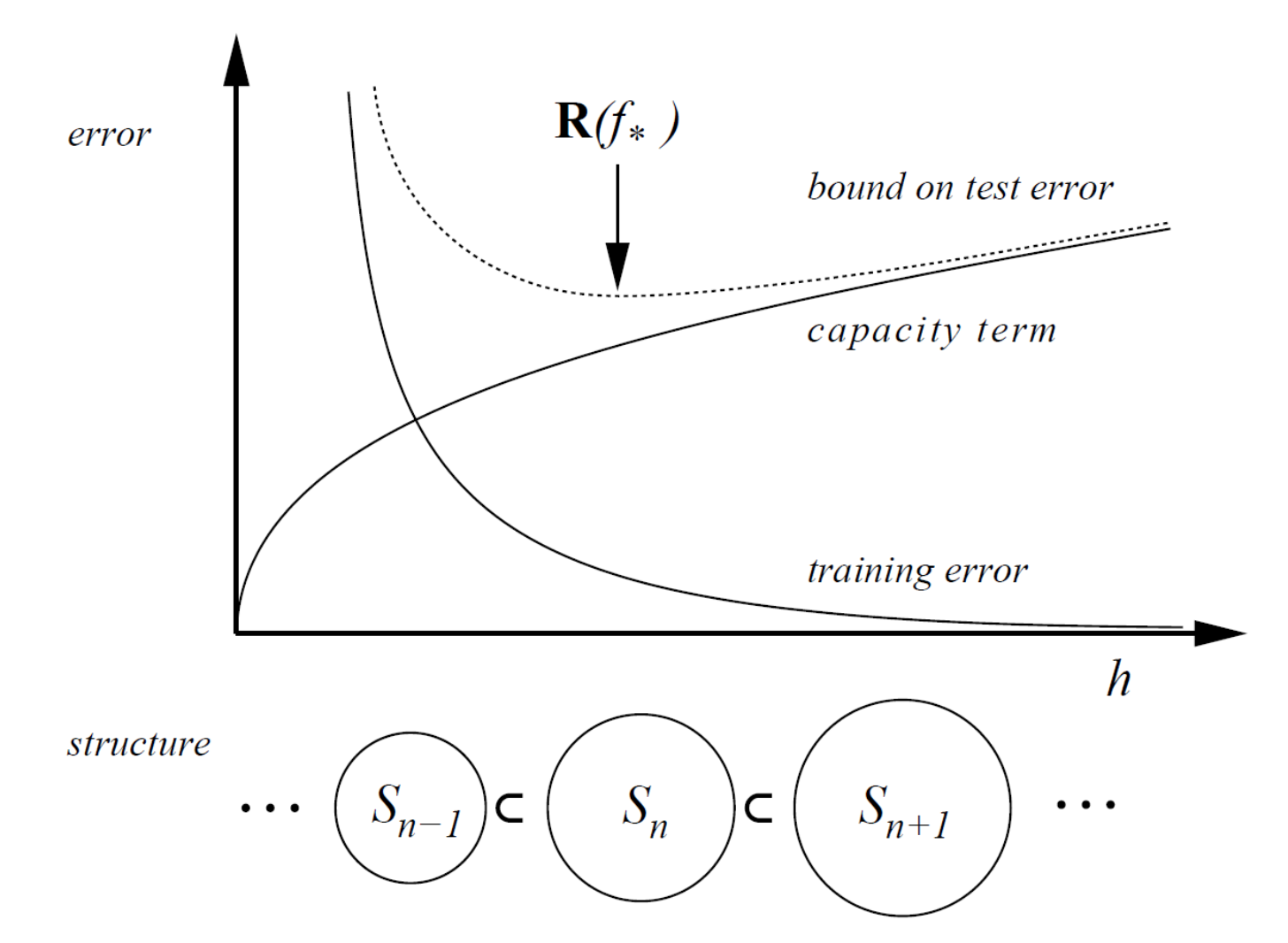
위 그래프에서 $x$축이 모델의 복잡도이고, 복잡도가 커질 수록 capacity는 올라간다. 이에 비해 train error는 줄어든다. SRM은 내가 현재 가지고 있는 학습 데이터를 얼마나 잘 맞추냐에 비례하지만, 여기서 모델 복잡도까지 커버한다.
SRM의 주 목적은 test error의 가장 낮은 점을 나타내는 점을 찾는다. 위 그래프에서는 $R(f_{*})$ 지점을 의미한다.
$h$는 VC dimension으로 정의된다.
따라서 성능과 복잡도를 고려해 적절한 모델을 선택하는 것이 SRM의 주목적이다.
$$ R_{emp}[f]=\frac{1}{n}\sum_{i=1}^{n}L(f(x_{i}), y_{i}) $$
$h$는 위에서 말한 바와 같이 VC dimension이고, $R_{emp}$는 zero-one loss이다. $x$가 입력, $y$가 정답이라고 할 때, 이들을 평균을 낸 것이 $R_{emp}$이다.
$$ R[f] \leq R_{emp}[f]+\sqrt{\frac{h(\ln{\frac{2n}{h}}+1)-\ln{\frac{\delta}{4}}}{n}} $$
SRM은 2가지 term으로 bound 된다.
첫 번째는 $R_{emp}$이고, 두 번째 루트 식에서 $n$은 학습 데이터의 개수, $\delta$는 0부터 1까지의 확률 값을 나타내는 parameter, $h$는 VC dimension이다.
$n$이 증가하면 capacity term은 감소한다. 이 말은 $R[f]$의 SRM도 감소한다. $h$가 증가하면 capacity term이 증가한다. 이에 따라 SRM도 증가한다.
Hidden node의 개수가 5인 것과 10인 것이 있는데 이 중 train error가 둘 다 5%라고 하면 SRM은 10인 것이 더 높다.
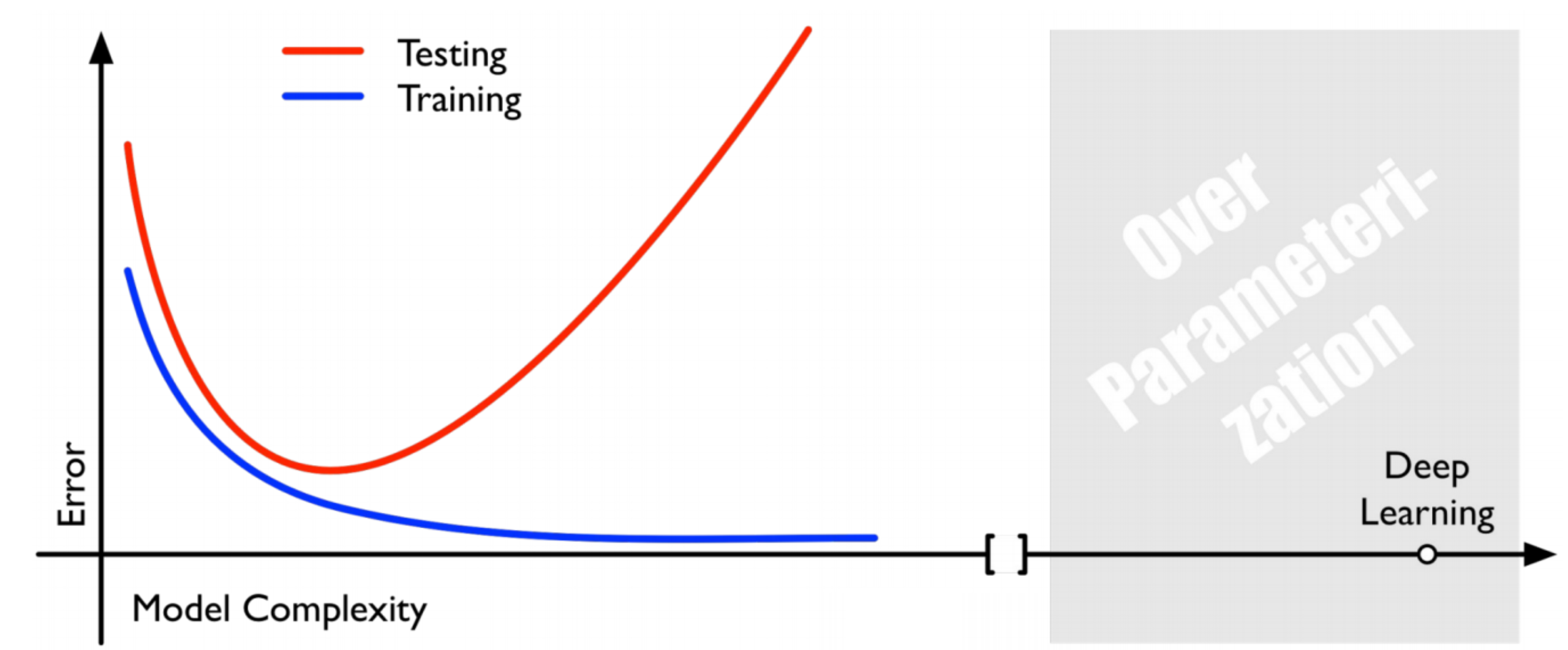
딥 러닝 알고리즘은 SRM 관점에서 model capacity가 매우 높다. parameter가 매우 많기 때문이다. 하지만 overfitting을 잡아줌으로써 딥 러닝 모델은 capacity가 높아도 error가 낮아졌다. 이때부터 딥 러닝의 시대가 시작되었다.
물론 성능이 좋은 딥 러닝 모델도 좋지만, 여전히 전통적 이론이 더 좋은 성능인 분야들이 많이 남아 있다.