Neural Turing Machines 분석
Neural Turing Machine에 대해 알아보기 전 Turing Machine에 대해 먼저 알아야 된다.

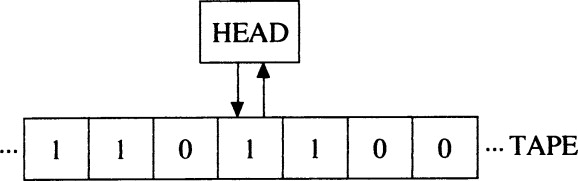
Turing machine의 실제 모습은 위 이미지와 같고 이를 간단하게 구조화시키면 아래 이미지와 같다.
Turing machine는 read, write에 집중하는 구조이고, 명령어를 통해 head를 좌우로 이동하면서 부호를 쓰거나 지울 수 있다. 하지만 discrete 한 점에서 backpropagation 즉 미분이 불가능하다.
NTM (Neural Turing Machine)은 무엇일까? 간단하게 요약하자면 training을 할 수 있는 machine이다. 따라서 Differentable turing machine이라고도 부른다. 즉 미분이 가능한 computer이고, back propagation의 원리 또한 미분을 사용한다.
우리가 사용하는 컴퓨터는 0과 1로 이루어져있고, 미분을 하게 되면 정확한 값을 도출하지 않고, 수치 미분을 사용하여 추정치를 구하기 때문에 완벽한 미분이 불가능하다. 하지만 여기서 중요한 사실은 말한 바와 같이 NTM은 미분이 가능해 back propagation이 가능하다.
NTM은 CPU와 RAM이 구별되어 있는 구조로 구성된다. CPU는 NN(Neural Network)에 해당하고, RAM은 external memory에 해당한다. NTM은 학습 과정을 통해 input과 output이 주어지면 알고리즘을 예측할 수 있다. 해당 논문에서는 sort, copy 등에 대한 실험 결과를 보여준다.

NTM의 대략적인 구조를 보면 controller가 NN에 해당한다. read 장치는 memory에 데이터를 저장하고 이를 controller에 전달해주는 역할을 한다. Turing machine과 NTM의 다른 점은 Head heads와 Write head가 여러 개 존재할 수 있다는 점이다. head가 여러 개 존재하면 더욱 효율적으로 machine이 작동할 수 있다.
memory에 존재하는 값은 0과 1로 이루어진 값들이 아닌 실제 값들로 이루어진 matrix로 구성되어 있다.
RNN과 LSTM도 존재하는데 왜 NTM 개념이 나왔을까? 그 이유는 이 2개의 개념은 activation과 memory가 함께 있는 구조이기 때문이다. 이는 activation이 증가하면 memory도 함께 증가해 연산량이 늘어나게 되고, 이는 비효율성을 증가시킨다. 그리고 RNN에서는 계속 학습 내용이 갱신되면서 이전 내용을 사용할 수 없는데, 이를 LSTM에서 해결해준다. 하지만 NTM은 이에 한 발짝 더 나아가 LSTM을 보완하였다.
RNN이나 LSTM을 막 쌓는 것보다는 model을 더욱 효율적으로 사용하기 위해 NTM을 사용한다고 생각하면 된다.
NTM은 특정 메모리 구조에 효율적으로 접근하여 read, write와 같은 상호작용을 한다.

model에 대해 더 detail하게 접근해보자. 우선 NTM은 NN이 memory를 읽고, 쓰는 특정 memory 부분에 집중한다.
위 모델에서 addressing은 말그대로 주소를 찾는 것이고 addressing은 크게 3가지 방법으로 분류한다.
1. content: 찾고 싶은 위치를 대략적으로 찾는다.
2. location: 모든 값들을 근사 값으로는 표현할 수 없기 때문에 location을 사용한다.
3. content + location
예를 들어 3*5 = 15 와 같이 구체적인 값이 나올 때는 location을 사용하여 addressing 한다.

addressing을 구체적으로 modeling 하면 위와 같은 gate로 구성된다. address를 통해 최종적인 w인 weight를 구한다.
content를 통해 content addressing을 하여 근삿값을 찾는 연산을 한다. 이는 softmax 연산으로 구성된다.


위 식에서 K는 cos 유사도로 측정한다. key strength로 이를 통해 값을 뭉개지게 하거나 sharp 하게 만들 수 있다.
위 예시를 보면 key strength가 클수록 값이 sharp 해지고, 작아질수록 뭉개지는 모습을 볼 수 있다.
다음은 location addressing이다. 위 addressing model에서 interpolation은 content와 location을 어떻게 배분할지를 결정한다.

위 식에서 gt는 controller인 NN에서 나온 값이다. 값이 1이면 content만 살아남고, 0이면 location만 살아남는다.
다음은 convolution shift이다. 이는 얼마나 많은 지점에 영향을 받는지를 결정한다.

address의 마지막인 sharpening이다. 이는 숫자가 나누어지면 숫자가 뭉개지는 현상을 방지한다. 이 과정을 통해 최종적인 weight를 구한다.

gamma 값이 커질수록 sharp 해지고 작을수록 blur가 된다.

addressing 과정을 각 단계별로 시각화한 이미지이다.
다음은 read, write과정에 대해 살펴보자.
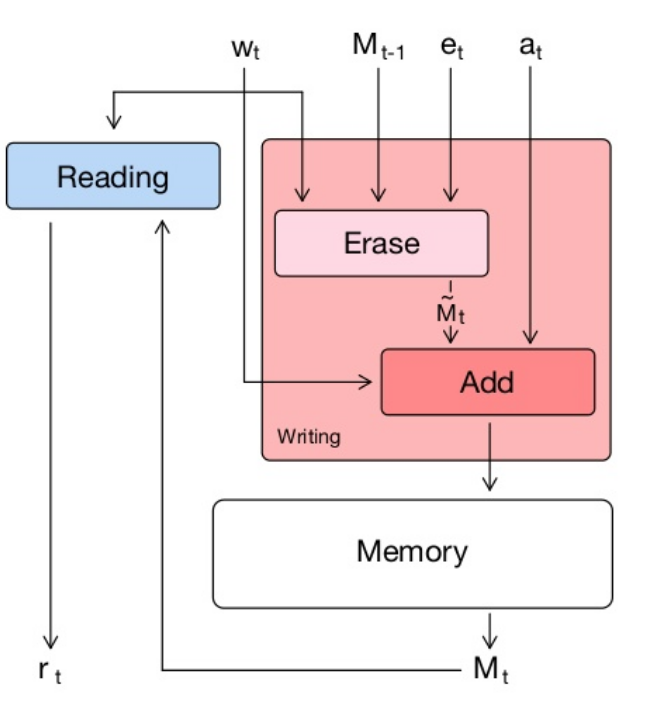
write 과정에 대해 살펴보자. write는 위 model 중 빨간 상자 부분이고, write 전 항상 erase 과정을 거치고, add를 함으로써 write 한다.
더욱 쉽게 이해하기 위해 예시를 통해 알아보자.

다음과 같이 memory가 구성되어있다고 가정하자. n은 memory의 idx이고, m은 vector의 크기이다. i는 memory의 주소이다.

erase operation에서 w는 어디를 지울지, e는 얼마나 지울지를 결정한다. e는 NN에서 오는 값이고, w는 위에서 진행한 addressing 과정에서 오는 값이다.

다음은 add operation이다. 위 식에서 M은 erase 이후의 memory이고, w는 어디를 추가할지를 결정하고 erase와 마찬가지로 addressing으로부터 오는 값이고, a는 NN에서 나오는 값이다. a가 커질수록 memory에 있는 숫자들의 값도 커진다.
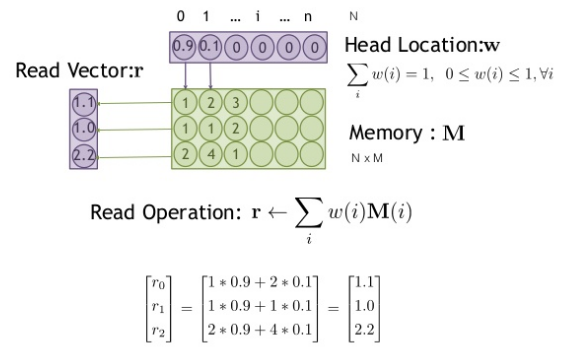
다음은 read operation이다. 위 식에서 w를 통해 memory에 있는 값을 얼마나 읽을지를 결정한다.
다시 NTM의 전체적인 구조로 돌아와서 Reading 과정을 끝내고 나온 r을 통해 loss를 구하게 된다. 그리고 이 r 값을 Controller에 다시 삽입함으로써 loss를 update 한다.
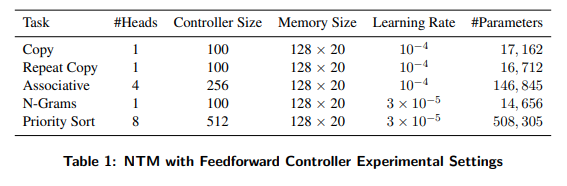


각각의 Task에 따른 실험 결과이다. LSTM을 사용할 때와 NTM을 사용할 때의 parameters의 큰 차이를 볼 수 있다.

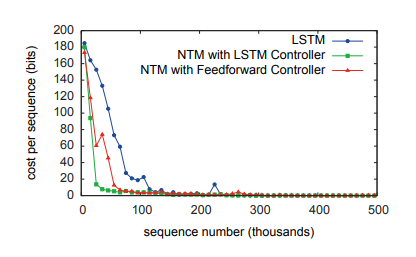




각 task에 따른 LSTM, NTM with LSTM controller, NTM with Feedforwad Control를 사용하였을 때의 그래프이다. 대부분의 task에서 NTM이 cost가 더 적은 모습을 볼 수 있다.
Reference