CNN attention based networks
현재 딥러닝을 주도하고 있는 분야는 자연어 처리 분야 및 컴퓨터 비전 분야입니다. 보통 자연어 처리는 RNN, LSTM 등을 기반으로 모델이 형성되고, 컴퓨터 비전은 CNN 기반으로 모델이 형성이 됩니다. 하지만 최근 들어 Attention, Transformer 등 자연어 처리에서만 사용되던 메커니즘이 컴퓨터 비전 분야에서도 활용이 되면서 더 이상 컴퓨터 비전 분야에서 CNN을 사용하지 않는 추세로 변화하고 있습니다.
오늘 살펴볼 Attention 기법도 NLP 분야에서 먼저 사용되었던 기법이지만, 이를 CNN에 접목시켜 SE-NET 등 다양한 Attention 기반 CNN 모델들이 탄생하게 되었습니다.
Attention 메커니즘이란
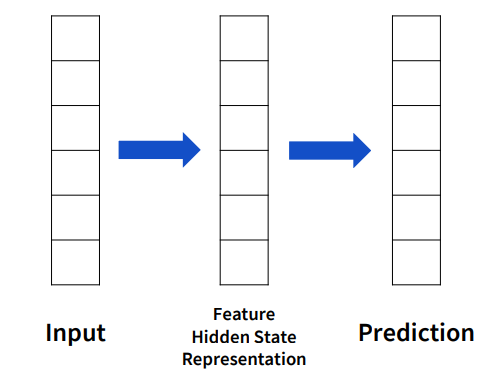
Attention 메커니즘을 이해하기 전에 지금까지 우리가 사용해왔던 네트워크의 특징부터 살펴봅시다.
우선 위 이미지는 기본적인 뉴런 네트워크의 architecture입니다. 화면과 같이 input을 feature로 만들어 prediction을 진행합니다.

FCNN은 파란색 부분에 해당하는 feature를 만들기 위해 input 전체와 weighted sum을 통해 구합니다.
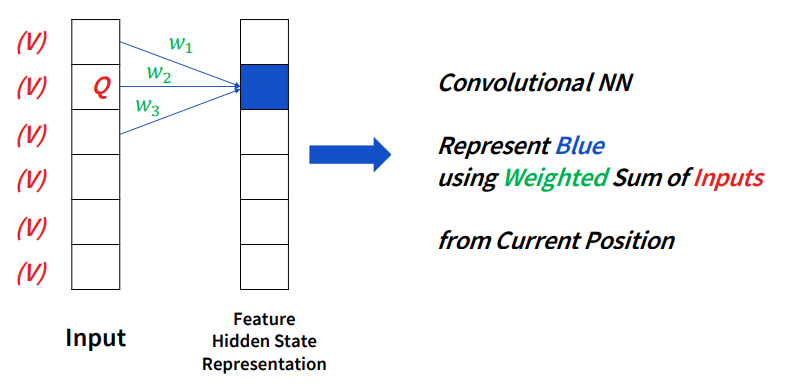
CNN의 특징은 FCNN와는 다르게 모든 input을 고려하지 않고, 현재의 position과 가까운 input과 weighted sum을 통해 feature를 결정하게 됩니다.
이를 통해 feature가 input의 position에 대해 작용한다고 말할 수 있습니다. 대신 input을 가지고 weight를 뽑는다고 하기보다는 그 position을 통해 weight가 학습된다고 생각하면 됩니다.
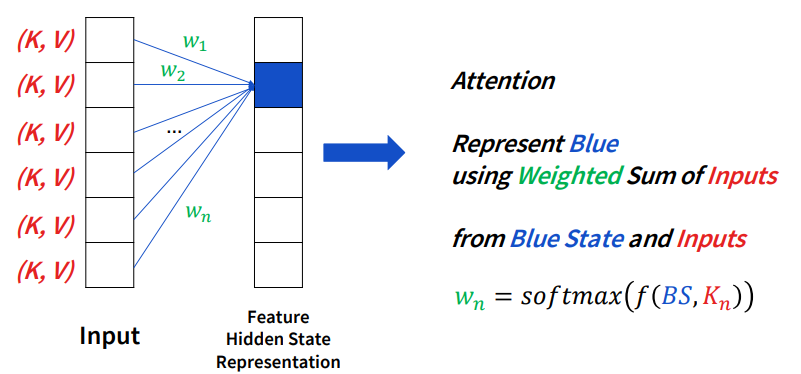
다음은 오늘 살펴볼 attention입니다. attention 같은 경우에는 정확히 표현하면 weight가 현재의 state와 함수로 정의가 되어야 합니다.
현재의 state가 아직 무엇인지는 모르지만, 현재의 state와 input을 통해 어떠한 함수를 거쳐 softmax를 통과하여 weight를 구하는 방식입니다.
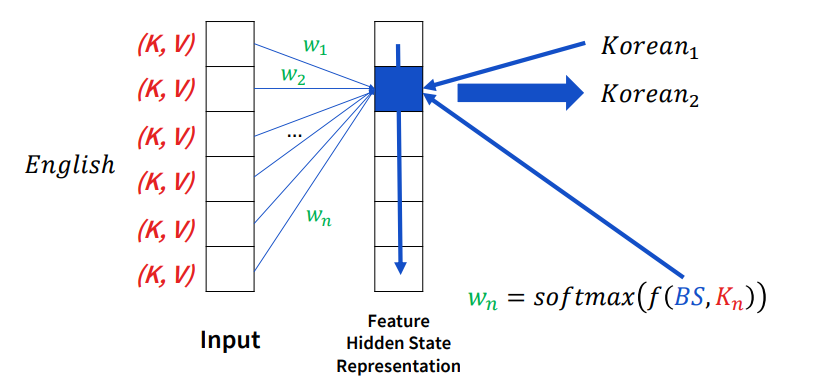
처음 attention machanism이 나온 건 machine translation입니다. 여기서 task는 NLP에서의 번역입니다.
번역 같은 경우에는 sequential하게 동작하는데, 위 그림을 예시로 설명하자면 만약 korean1이라는 feature를 만들었으면 다음 korean2라는 feature를 만들 때는 현재의 state와 input을 통해 weight를 결정하게 됩니다.
이것이 바로 NLP에서의 attention입니다.
attention은 NLP 분야뿐만아니라 imager captioning에서도 자주 사용되었습니다.
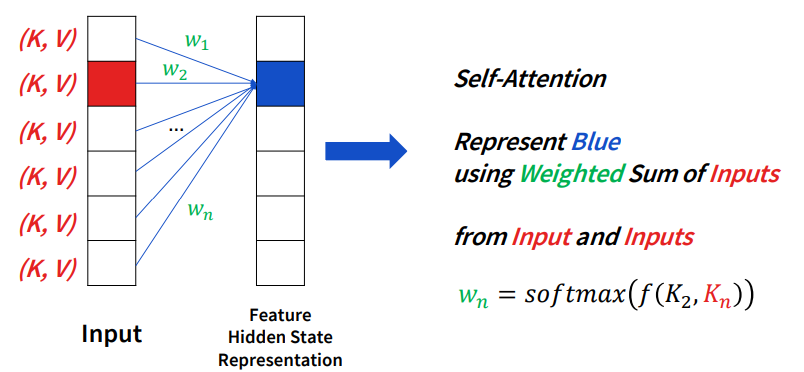
오늘 알아볼 attention은 바로 self-attention입니다. 이것이 CNN에서 가장 많이 사용되는 attention 기법 중 하나입니다.
만약 feature의 현 상태를 모른다고 가정해봅시다. 그러면 우리는 weight를 결정하기 위해 input들의 relation을 통해서 weight를 표현할 수 있다는 생각을 할 수 있습니다.
위 그림과 같이 feature pixel을 결정하기 위해서는 input에 해당하는 pixel들의 관계를 통해 weighted sum을 하여 결정하는 것입니다.
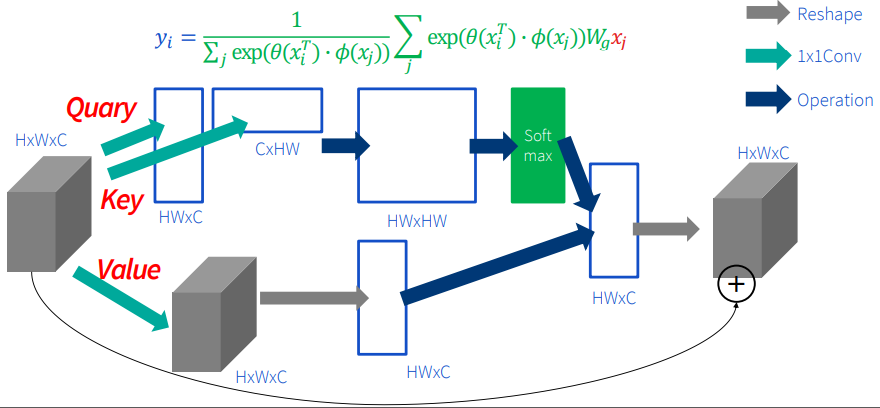
Self-attention을 CNN에 적용시킨 논문이 바로 Non-local NN입니다. 위 그림과 같이 input 이미지를 transpose와 matrix 연산을 통해 모든 pixel 간의 관계를 (HW*HW 부분) 정의한 후 이를 모델링하여 softmax를 거쳐 weight를 만듭니다. 그러고 나서 weighted sum을 통해 다음 feature로 표현하는 방식입니다.
이 방식은 NLP의 self-attention을 그대로 쓰는 방식인데 단점이 있다면 모든 pixel에 대한 관계를 정의해야되기 때문에 space cost가 매우 많아집니다.
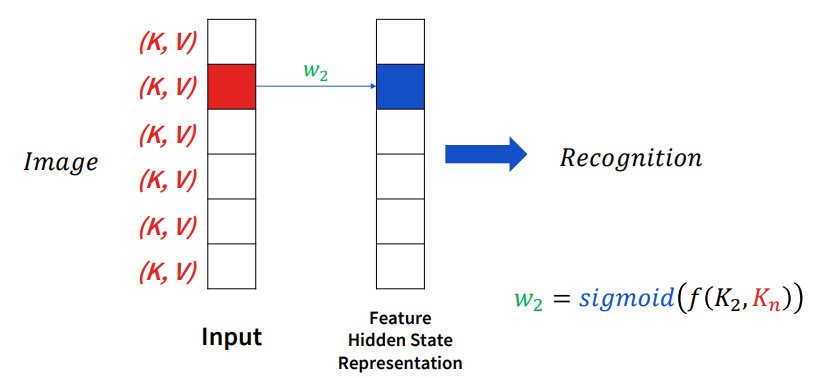
따라서 recalibration이라는 개념이 나오게 됩니다. 이는 모든 pixel을 보기는 하지만 sigmoid 연산을 통해 중요한 pixel을 더 큰 가중치를 두고, 중요하지 않은 pixel에 대해서는 더 작은 가중치를 두어 연산을 더욱 효율적으로 만듭니다.
Image-net 마지막 대회에서 우승한 SE-NET에서도 recalibration을 사용하였습니다. 이 논문에서는 픽셀에 대해서 적용시키지 않고, channel에 대해서 적용시켰습니다.
Attention을 적용시킨 CNN
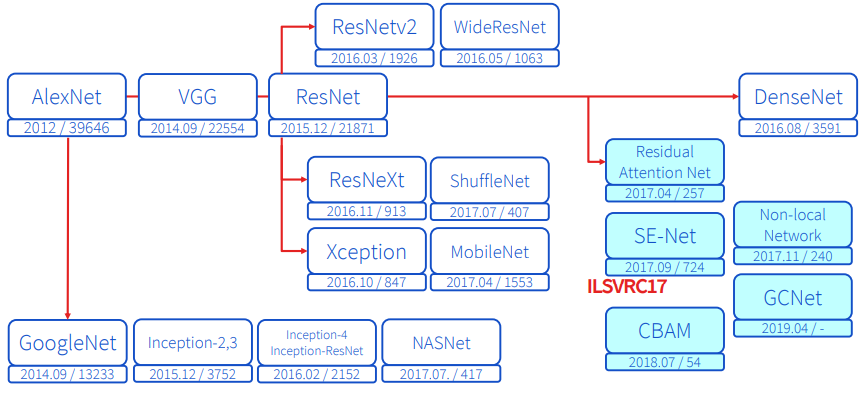
지금까지 나온 주요한 CNN 모델들 입니다. 이 중에서 오른쪽 파란색 부분이 Attention을 적용시킨 CNN입니다. 몇 가지 네트워크에 대해 간략히 알아봅시다.
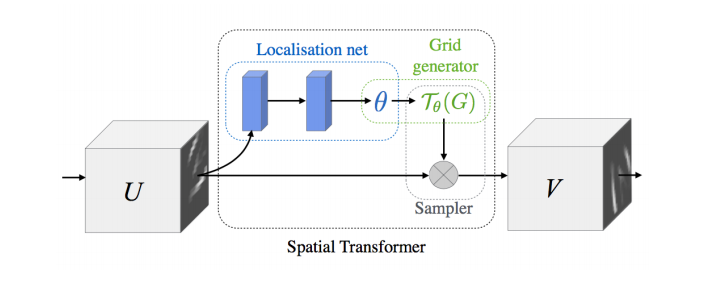
Spatial Transformer Network라는 mnist dataset으로 쉽게 설명을 하면 구석에 있는 숫자들을 가운데 정렬을 해주는 네트워크입니다. 위 그림과 같이 localisation net을 따로 두어 학습을 시킵니다. 이 방법 역시 attention에 포함됩니다. 하지만 모든 input에 대해 weighted sum을 해주는 것이 아닌 그냥 단순히 spatial만 조절해주는 방법입니다.
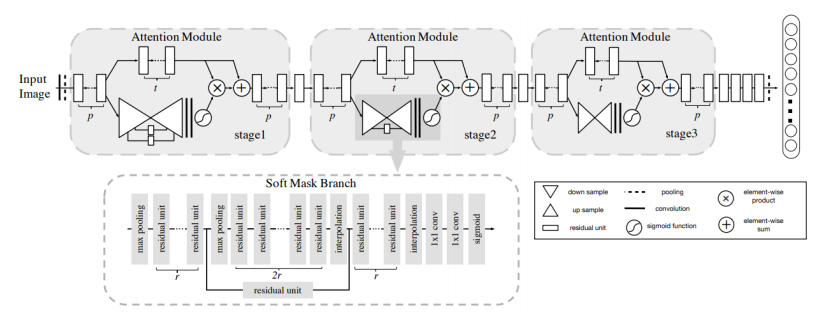
다음은 residual attention network입니다. 이는 resnet에서 attention 기법을 추가한 방법입니다. 하지만 이 논문에서 사용된 resnet은 우리가 알고 있는 resnet과 차이가 있습니다. 보통 resnet이라고 하면 input에서 바로 skip layer로 연결이 되어야 하는데, 위 그림과 같이 해당 논문은 conv를 한번 거친 후 skip layer로 연결이 됩니다.
여기서 사용되는 attention은 input을 통해 mask gerneration network를 통해 만듭니다.

이를 통해 attention을 시각화 할 수 있습니다. 위 결과를 보면 앞 layer부터 뒤로 갈수록 object에 더 집중하는 모습을 볼 수 있습니다. 이를 통해 attention이 제대로 동작하고 있는 모습을 알 수 있습니다. 하지만 아쉽게도 성능은 그다지 좋지 않습니다.
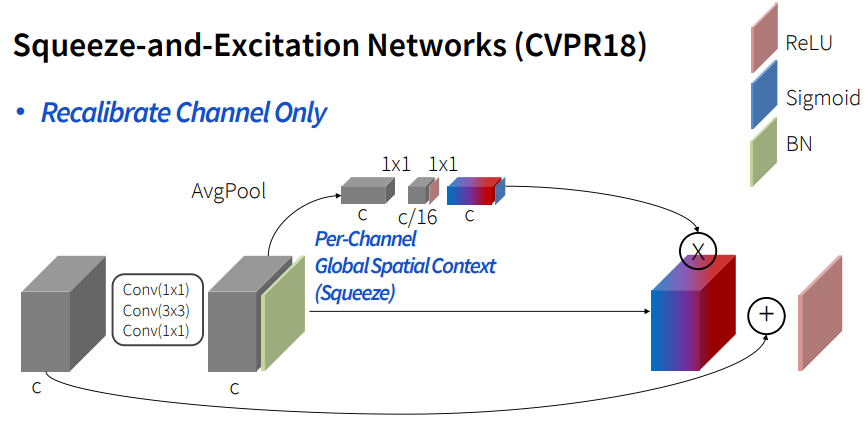
오늘 살펴볼 마지막 논문은 SE-NET입니다. 이전까지 살펴본 네트워크들은 attention을 하기 위해 다른 복잡한 network를 만들어야 한다는 점과 값들이 모두 tensor로 구성되어 있어 무겁다는 단점이 있습니다. 하지만 SE-NET은 channel만 recalibrate 연산을 적용시켜 이 단점들을 보완하였습니다.
attention 값을 구하기 위해 spatial 값은 필요가 없으니 avrage pooling을 통해 구합니다. 이것이 squeeze입니다. 하지만 이 과정 중 옆 channel들과의 영향을 받아야 되기 때문에 이를 FC를 사용하여 구합니다. 이것이 excitation입니다.
SE-NET의 성능은 Image-net에서 우승한 모델인 만큼 좋고, 무엇보다 resnet과 비슷한 구조를 가진 network에 모두 적용시킬 수 있습니다.
Reference
www.youtube.com/watch?v=Dvi5_YC8Yts&t=1465s