[Anomaly detection] Overview
본 포스트는 고려대학교 산업경영공학부 강필성 교수님의 Business Analytics 강의를 정리한 내용입니다.
OVERVIEW
Anomaly detection의 목표는 비슷하게 생긴 객체들 사이에서 다른 객체를 탐지하는 것이다.
고전 적인 machine learning의 개념에서 기계가 학습이 가능하다고 말하는 것은 어떠한 task T에 대해 얼마나 학습을 잘하는지를 측정하는 performance measure P가 있을 때, 충분한 경험, 즉 데이터 E를 제공해주면 P가 상승된다는 것이다.
Unsupervised learning에서 우리는 주어지는 데이터에 대한 distribution을 추정하거나, 데이터 간 cluster를 찾거나, 데이터 간 association을 분석하는 것들을 각각의 node에 대해 network를 구성해서 파악한다.
Supervised learning에서는 데이터와 이에 대한 설명을 해주는 label 값 사이의 관계인 model f를 찾는 것이 목적이다.
Anomaly detection이란 분야에 따라 비슷하게 쓰이는 단어가 많다. 예전 자료들을 보게 된다면 noverity detection, outlier detection이라는 단어가 쓰였다.
Anomaly data에 대해 크게 2가지 관점이 존재한다.
1. Mechanism of data generation에 대한 관점
: 일반적인 데이터와 다른 mechanism에 의해 발생한 데이터들이다. 꼭 동일한 mechanism에서 데이터가 만들어 질 필요는 없다. 이들은 발생 빈도만 낮을 뿐이다!
2. Data density에 대한 관점
: Anomaly data들은 굉장히 낮은 밀도에서 만들어진 데이터들이다. 즉 발생 확률이 적은 데이터들이다!
Outlier vs Noise
기계 학습 또는 데이터 분석을 하다보면 noise라는 단어를 매우 많이 듣게 되는데, noise와 outlier는 구분해서 살펴야 한다.
noise는 각 변수들을 수집하는 과정에서 자연적으로 들어가는 변수 간 변동성이다. noise가 반드시 제거되어야 하는 것은 아니다. noise는 항상 데이터에 내재되어 있다.
Outlier는 반드시 찾아야하는 insteresting variable이다. 일반적인 데이터를 생성하는 mechanism을 위배함으로써 만들어진 변수들이다. 이를 찾는 것이 굉장히 큰 domain이 되는 경우가 많다.
Anomaly detection vs Classification
Anomaly detection의 목적 자체는 supervised learning과 같다. 그 이유는 해당 데이터가 outlier인지 아닌지 판단을 해야 되기 때문이다. (전체적인 목적만 보면 $p(y\mid x, \theta)$를 구해야 되기 때문이다. $y = \left\{0 , 1\right\}$)
하지만 실질적인 행동은 unsupervised learning을 한다. 이를 자세히 알아보자.

왼쪽에 해당하는 Binary classification은 2가지의 종류에 대한 데이터의 boundary를 찾는 문제로 정의된다. 하지만 오른쪽 Anomaly detection은 일반적인 classification 문제와는 다르게 outlier data의 수가 적기 때문에 outlier data들이 outlier를 대표할 수는 없다. 따라서 anomaly detection은 normal data를 통해 boundary를 결정하게 된다.
위 그림에서 새로운 데이터인 $A, B$에 대해 classification은 주어진 label 값 중 무조건 1가지에 포함이 되어야하지만, anomaly detection에서는 boundary를 정해두고 이외의 밖에 속하는 값들을 normal이 아니다고 판단한다.
이를 쉬운 예시로 설명하면 애기한테 사과와 바나나를 구분하는 문제로 생각할 수 있다.
Classification
: 애기한테 사과와 바나나에 대한 이미지를 많이 보여주고 판단시킨다.
Anomaly detection
: 애기한테 사과 이미지만 보여주고 어느 범위까지가 사과인지 판단시키는 문제. 사과를 동그랗다고 정의하면 수박도 사과가 될 수도 있고, 빨간색이 사과라고 하면 청사과는 outlier라고 판단할 수 있다. 따라서 데이터에 대한 이해가 더욱 필요하다.
Generalization vs Specialization
Generalization과 specialization은 사이에는 반드시 trade off가 존재한다. 어떤 데이터에 대해 genaeralization이 커지면 실제 range와는 다르게 범주가 매우 커질 수도 있고, 반대로 specialization을 증가시키면 너무 tight 해져서 실제 정상 데이터를 비정상으로 판단할 수도 있다.
따라서 이를 잘 설정해야한다.
When we use the anomaly detection?
실질적으로 어떠한 문제를 해결할 때 anomaly detection을 써야 되냐 classification을 써야 되냐라는 질문이 있을 수 있다. 결론적으로 말하자면 classification이 정확도가 대체적으로 매우 높고 난이도도 쉽다.
이는 주로 2가지 조건을 따지며 결정한다.
1. Data imbalancing: 7:3 정도는 괜찮지만 outlier 특성상 99:1 이렇게 된다면 매우 심각하다. 어느 정도 cover가 가능하면 classification으로 접근하자
2. Abnoramal class에 대한 데이터 수
: 만약 충분하다면 under/over sampling을 통해 classification을 진행하는 것이 훨씬 좋다.
Under sampling: 데이터가 많은 label을 적은 label의 데이터 수와 맞춘다.
Over sampling: 데이터가 적은 label의 data를 복제 또는 GAN 등을 통해 복사 시킴
하지만 abnormal data가 충분하지 않다면 anomaly detection을 쓰는 것이 좋다. 1번과 차이는 양품과 불량품을 분류하는 데 있어 양품이 1000000개 있고, 불량품이 10000개 있으면 그냥 classification으로 접근하는 것이고, 양품이 10000개 있고 불량품이 100개 있으면 anomaly detection으로 접근하는 것이 더 좋다는 것이다.
물론 classification으로 푸는 것이 모든 면에서 좋지만, 현실적인 문제에서는 예측하지 못하는 abnormal data도 매우 많다.
Type of Abnormal Data
1. Global outlier
: 다른 데이터와 태생적으로 완전히 다른 데이터들. 누가 봐도 abnormal이라고 생각하는 데이터
2. Contextual outlier
: 상황과 환경에 따라 정상이 될 수도 있고, 비정상이 될 수도 있는 데이터들. 예를 들어 북극에서 30도와 사막에서 30도는 다르다.
3. Collective outlier
: 집단을 이루는 outlier들을 의미한다. 예를 들어 Dos 공격에서 비정상적 접속을 하는 client들이 된다.
Challenges
- Anomaly detection은 Abnormal data를 충분히 확보한 상황이 아닌, normal data만을 가지고 train을 진행한다. 따라서 normal, abnormal data에 대해 modeling을 하기에 난도가 높다. abnormal data의 크기가 작은 것도 영향이 있지만 그보다 boundary를 정의하기가 힘들다. 구분하기 힘든 영역을 gray area라고 부른다. 데이터들은 연속적이기 때문에 boundary를 반드시 결정해야 한다.
- 우리가 해결하고자 하는 domain에 따라 generalization과 specialization에 대한 trade off를 정의해야 한다. 각 문제에 따라 비율이 다르다. 의료 데이터의 경우에는 평균과 조금만 떨어져도 outlier가 되지만, 마케팅 데이터의 경우에는 조금 더 범위가 넓을 수 있다.
- 결과에 대해 이해가 돼야 한다. 왜 컴퓨터가 이를 이상치로 판단했는지, 어떤 domain이 abnormal에 많이 기여했는지 알아햐 한다.
Performance Measures
기본적으로 train 할 때는 위에서 언급한 바와 같이 normal dataset만 필요로 하고, test시에는 normal, abnormal dataset이 필요하다. 물론 절대적인 수치는 normal이 훨씬 많다.


Detection rate: 실제 비정상 중 비정상 데이터로 판단한 비율
FRR: 실제로는 정상인데 비정상으로 판단한 비율
FAR: 실제로는 불량인데, 정상으로 예측한 비율
위 지표들은 정상과 비정상에 대한 threshold가 정해졌을 때만 계산이 가능하다. 따라서 우리는 threshold 값을 결정하면서 위 지표 값들을 구해야 한다.
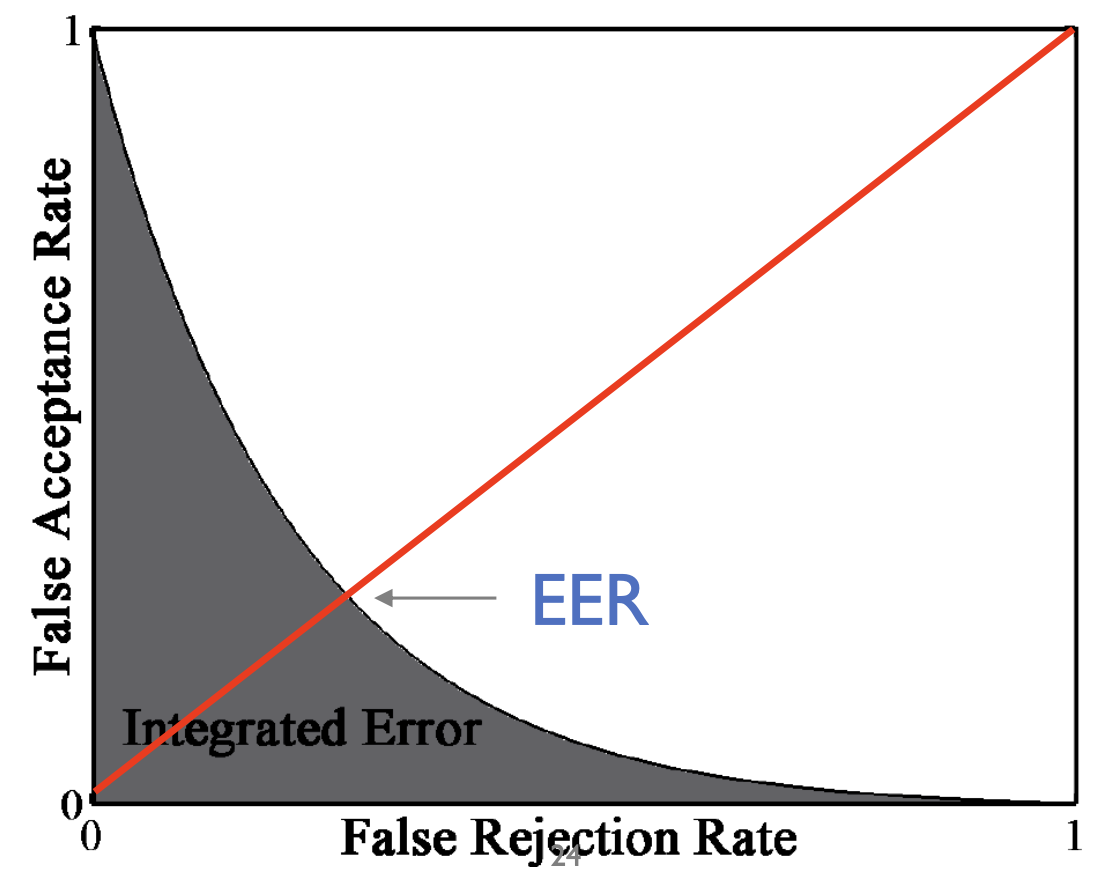
따라서 계속 threshold 값을 변경해가면서 측정을 해야 한다.
x축을 FRR, y축을 FAR로 두고 plot화 하면 위 그림처럼 나오게 된다. FRR과 FAR은 서로 반비례 관계를 갖고 있는 모습을 확인할 수 있다.
IE (Integrated Error)는 auroc 계산과 같이 curve 아래에 대한 넓이이다.
EER (Equal Error Rate)는 FAR과 FRR의 동등한 error 비율에 대한 지점이다.
우리는 최종적으로 IE와 EER을 최소화하는 threshold 값을 결정해야 한다.