
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- SVM hard margin
- RCNN
- cnn 역사
- support vector machine 리뷰
- pytorch c++
- DeepLearning
- 서포트벡터머신이란
- cs231n lecture5
- SVM margin
- Computer Vision
- pytorch
- CNN
- darknet
- Deep Learning
- SVM 이란
- self-supervision
- fast r-cnn
- Faster R-CNN
- computervision
- 논문분석
- 데이터 전처리
- EfficientNet
- yolov3
- pytorch project
- TCP
- yolo
- libtorch
- Object Detection
- svdd
- CS231n
- Today
- Total
아롱이 탐험대
Transmission Control Protocol (TCP) (5) 본문
앞서 살펴본 window size는 RWND와 CWND의 minimum 값을 사용해서 정한다. 오늘은 cwnd에 대해 중점적으로 알아보자.
window size는 byte 단위이다. 혼잡 제어에서는 단순하게 설명하기 위해 packet 단위로 설정했다. 실제 구현은 byte 단위로 진행된다. 아래 그림은 packet으로 대체한 것이다.

CWND는 sender가 관리한다. 최초에는 CWND를 1로 설정한다. receiving 공간은 충분히 넓고, RWND는 고려하지 않는다고 가정하자.
CWND를 처음에는 1로 보내고 순차적으로 2, 4, 8로 증가시킨다. 이를 자세히 알아보기 위해 아래 그림을 통해 살펴보자.

i = 4라는 것은 packet을 4개 보낸다는 의미이다. 혼잡 제어에서 ACK을 줄이는 것은 무시하고 그림을 보자.
지금은 혼잡 제어 상황이다. packet 1개당 1개의 ACK이 나간다고 생각하자. 4개의 ACK이 돌아왔다는 내가 보낸 4개의 packet이 혼잡을 유도하지 않고, 현재 상황도 혼잡하지도 않다는 의미이다. 그러면 조금 더 보낼 수 있다고 생각하고 순차적으로 5개의 packet을 보낸다. 여기서 또 ACK이 5개가 오면 6, 7,... 순으로 packet을 증가시켜서 보낸다.
혼잡 제어에서는 상대가 받을 수 있는 만큼 보내는 것이 가장 좋다. 내가 보내는 packet이 너무 적을 수도 있는데, sender 입장에서는 이게보내는 양이 어느 정도가 적당한지 모른다. 또한 어느 구간이 혼잡한지도 모른다. 그래서 스스로 CWND를 통해 size를 늘린다.
혼잡이 발생하기 시작하면 CWND를 반으로 줄여서 다시 보내기 시작한다. sender가 window size를 늘렸다가 줄였다가 하면서 window size를 결정한다.
서로 가는 경로 및 목적지가 달라서 혼잡이 발생하는 구간을 정확하게 알 수 없다. 따라서 혼잡이 본인 때문에 일어났다고 가정하고 size를 줄인다. 이 상황에서는 해당 sender 만 줄이는 것이 아니라 다른 sender들도 window size를 줄인다.
1개씩 점점 늘리는 것을 additive increase라고 부르고, 혼잡한 상황에서 줄이는 것을 congestion avoidance라고 부른다.
이렇게 additive increase를 하는 것은 좋긴 하지만 window size를 늘리기에 속도가 너무 느리다. 따라서 아래와 같은 개념이 나왔다.
Exponential increase는 window size를 2배 씩 늘린다. 이에 대해 늘리는 과정은 slow start라고 부른다. 2배씩 늘리는데 이름이 slow start인 이유는 flow control 보다 느리기 때문이다.
flow control에서는 혼잡이 생겨도 control이 되지 않고 대량의 packet들이 계속 들어온다. 이로 인해 control이 되지 않아 느려진다.
그래서 혼잡 제어에서는 2배씩 보내는 것이다. 근데 무작정 2배 씩 늘려서 보내는 것이 아니라 정해둔 threshold가 있다. threshold size를 넘어가면 additive increasing으로 전환하여 보낸다. 마찬가지로 혼잡해지면 size는 절반으로 줄어든다.
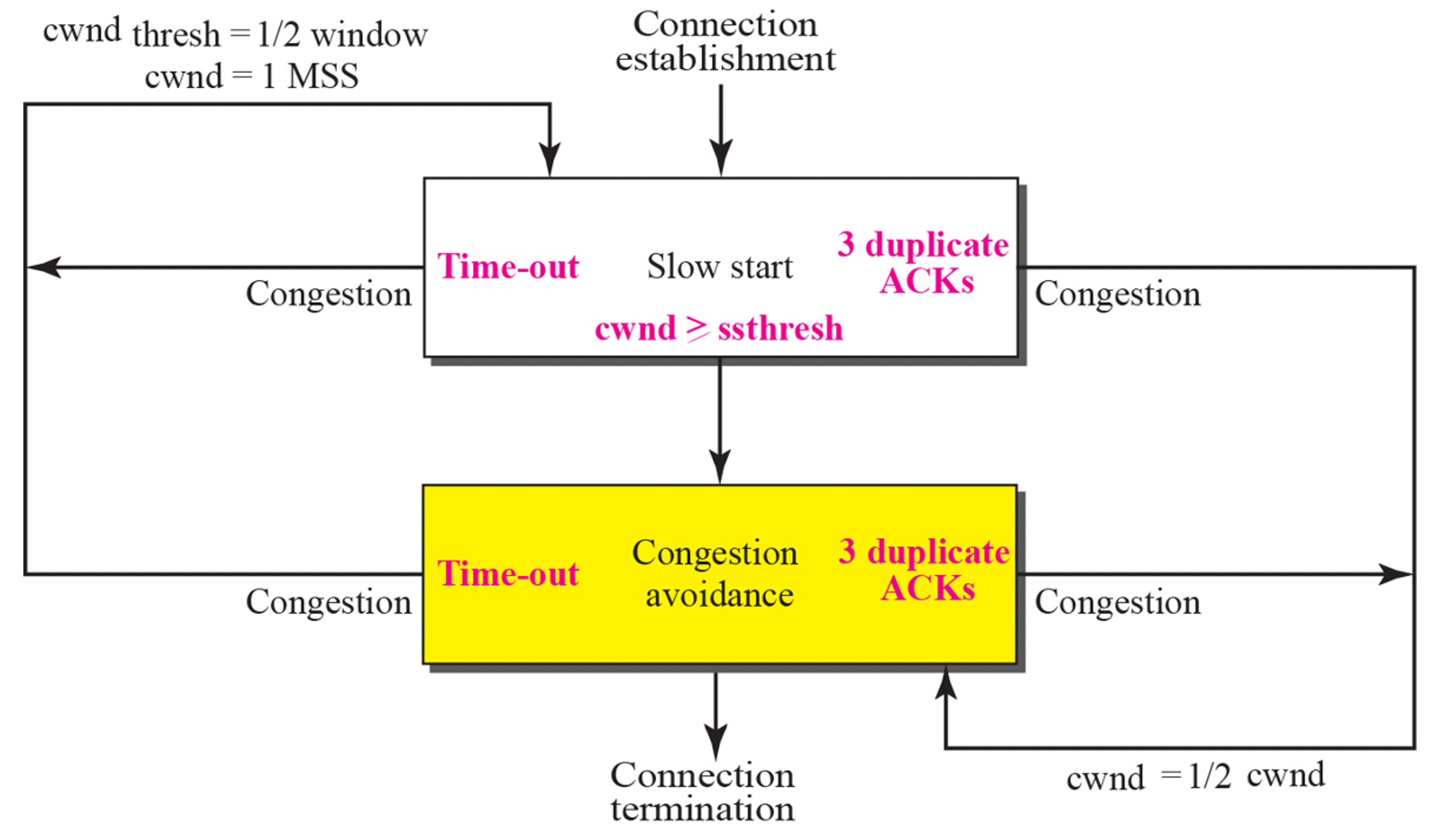
위에서 살펴본 바와 같이 연결이 성립되면 slow start를 통해 2배씩 window size를 증가시키고, sshtresh를 만나게 되면 멈춘다. 이때 딱 정해진 window size에서 멈춘다. 그 후 Congestion avoidance 과정이 되는데, 여기서는 additive increase를 한다. 여기서 혼잡이 발생하게 되면 window size를 절반으로 줄인다. 이게 일반적인 상황이다.
만약 이전 시간에 살펴본 3 duplicate ACK이 되면 혼잡한 상태로 간주하는데, 그 이유는 98%의 packet들은 혼잡 때문에 router가 모두 버리기 때문이다. 그래서 3 duplicate ACK을 혼잡 상태로 간주한다.

해당 그래프를 살펴보자. x축은 시간, y축은 cwnd이다. 그림에서는 RTTs를 1초로 가정한다. window size는 packet에 대한 ACK을 받고 증가시킨다.
최초의 window size는 1이다. 그 이후로 0으로는 절대 안떨어진다. 이는 CWND의 minimun은 1이라는 것을 의미한다. (0이면 packet을 보내지 못하는 상황이라 무시한다.)
처음에는 slow start를 한다. 1, 2, 4, 8, 16으로 보냈는데 threshold가 16으로 되어 있어 여기서부터는 additive increase로 바뀐다. 16, 17,... ,20으로 window size가 바뀐다.
SS는 조금 있다가 살펴보고 다음 AI (Additive Increase)를 보자 10, 11, 12까지 증가 시킨 후에 packet loss가 생긴 상황이다. 이때 CWND를 절반으로 줄인 후 다시 AI를 한다. 이렇게 하는 것을 AIMD라고 줄여서 말한다. 늘리는 것은 천천히, 줄이는 것은 절반으로의 의미를 갖는다.
다음 상황은 Time-out을 살펴보자. Time-out에 의해 packet loss가 되면 심각한 혼잡 상황으로 간주한다. 이럴 경우에는 반으로 줄이는 것 가지고는 해결하기 힘들것 같다고 생각해서 winodw size를 1로 줄이고 다시 출발시킨다. 그 후 Threshold를 CWND의 절 받으러 잡는다.
Sender는 Time-out 상황에서 굉장히 많은 packet들이 사라진 후 time-out이 되야지 탐지를 할 수 있다. 그래서 이를 굉장히 심각한 상황으로 본다. 그래서 반으로 줄이지 않고 1로 바꾼다. 하지만 additive increase를 하면 시간이 오래 걸리니깐 이때는 slow start로 진행하여 2배씩 증가시킨다.

위 그림과 같이 컴퓨터 2개들끼리 혼잡 관계라고 가정하자. connection 2개는 1개를 통해 전달된다고 하자. 해당 link에 물리적인 네트워크 성능은 R이라고 하자.

위 그래프에서 $y=x$ 선을 equal bandwidth share라고 한다. input과 output이 같다는 의미이다.
감소하는 직선은 $y = -x +R$이다. $x$와 $y$의 합이 $R$이라고 생각하면 된다. 예를 들어 $R = 100$이면 $(80, 20) \text{ or } (70,30)$ 등등이다.
$y=x$ 그래프 아래 속하는 지점은 connection 1이 더 많이 가져간 상태이다. 예를 들어 $(45, 10)$ 일 때 둘의 합은 55이다. 이때 2개에 대한 throughput이 어떻게 증가하는지 보자.
우리는 AIMD라고 가정하고, CWND = CWND + 1이라고 하자. $x$가 증가한 만큼 $y$도 증가시킨다. 그 이유는 조건에서 2개의 RTT가 같기 때문이다. 이는 RTT가 1이면 1초에 1개씩 늘어난다는 것이다. CWND + 1 이기 때문이다. 45도의 기울기로 증가한다. 증가하다가 R이 넘어가면 어떤 상황이 발생할까? R을 넘었다는 것은 혼잡이 발생하기 시작한 상황이라고 생각하면 된다. 이때 connection 1과 2가 둘 다 같이 혼잡을 경험하고 3 duplicate ACK으로 packet lose를 감지했다고 가정하자. 이때는 window size를 반으로 줄인다. 그리고 여기서 다시 +1 씩 증가시킨다. 여전히 x와 y의 증가량은 같다.
문제는 똑같은 조건으로 위 그래프와 같이 왔다 갔다 하다가 수렴한다. connection 1, 2의 RTT가 같은 경우에는 결국 가운데로 수렴하기 때문에 fair 한 경우라고 한다.
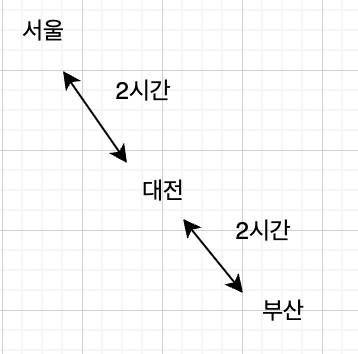
throughput은 RTT에 반비례한다. 예를 들어 2개의 팀이 있는데 1팀은 서울-부산, 다른 팀은 서울-대전이라고 가정하자. 2 시간 후에 두 팀은 대전에 도착한다. 4시간이 지나면 대전팀은 서울로 다시 돌아온다. AIMD라고 가정할 때 대전팀은 서울로 돌아와 +1 더 보내려고 한다. 같은 시간 부산팀은 부산에 도착한다. 6시간 후에 대전팀은 대전에 2개를 쌓아두고 부산팀은 돌아오는 길 대전이다. 8시간 후에는 대전팀은 서울에서 3개를 보내려고 하고, 부산팀은 서울에서 2개를 보내려고 한다.
16시간 후에는 부산팀은 3개를 갖다 놓으려고 하고, 부산에는 3개를 둔 상태이다. (1+2) 대전 팀은 대전에 10개를 (1+2+3+4) 두고 5개씩 두려고 한다.
이를 통해 알 수 있는 사실은 RTT가 다르면 증가 속도가 다르다는 것이다. RTT가 작으면 큰 얘보다 더 많이 가져가게 디자인이 되어 있다. TCP에서 window는 RTT마다 증가한다. RTT가 다르면 증가 속도가 서로 다르다.

다시 돌아와서 Client 1의 RTT가 1, Client 2의 RTT가 2라고 할 때 CWND, 즉 throughput은 Client 1이 2배 더 많이 가져간다. 결국 이를 식으로 표현하면 $y = \frac{1}{2}$ 가 되고, 결국 증가할 때는 위 그림 파란색 선의 기울기만큼 증가할 것이다. 결국 RTT가 다르면 TCP가 fair하지 않다는 의미이다.
다른 경우를 보자. Client 1의 connection이 2개라고 생각하자. Client 1은 socket을 2개 만들고 연결을 한다. 해당 router의 경쟁 구간에는 Client 1의 socket 2개와 Client 2의 socket 1개가 들어온다. router는 누가 보냈는지 고려하지 않는다. 즉 3개의 socket을 공평하게 취급한다. 결국 이 구간을 flow 3개가 나누어 갖는 것이다. Client 1은 1개를 2개로 만드는 것인데 결국 Client 1은 $\frac{2}{3}$ 만큼, Client 2는 $\frac{1}{3}$ 만큼 갖는 것이다.
flow가 많아지는 것도 결국 fair 한 것이 아니다. 따라서 기숙사와 같이 공공장소에서 p2p 사이트를 금지하는 이유가 이거다.
혼잡이 생기면 TCP는 겸손하게 본인의 속도를 줄인다. router 입장에서 보면 갑자기 혼잡이 없어져서 빈 공간이 많이 생기게 된다. 또 이 빈 공간을 sender가 조금씩 늘리다가 반으로 줄이게 된다.
우리가 사용하는 인터넷은 중앙 통제가 없어 속도 저하에 대한 여러 가지 요인이 있다.
1. 서버에 대한 문제
2. router 고장
3. 내 컴퓨터 혹은 브라우저 문제
4. TCP 문제
TCP vs UDP
TCP의 경쟁자는 UDP이다. TCP는 신뢰성 보장을 위해 SEQ와 ACK을 사용하였다. flow control도 사용하여 상대 buffer가 받을 수 있는 만큼 보냈다.
TCP의 핵심은 4개이다.
1. Set up 과정이 있다.
2. 신뢰성을 보장한다.
3. Flow control 가능하다.
4. Congestion control이 가능하다.
UDP는 이 4가지를 하지 않는다. 비유하자면 TCP는 전화, UDP는 우편이다. UDP는 그냥 주소만 써서 보낸다. 또한 중간에 packet이 없어져도 신경 쓰지 않는다. application에서는 신경을 써야 한다.
UDP는 ACK이 없다. 따라서 send to를 사용하여 가지고 오는 데로 나간다. network 관리자 입장에서는 매우 곤란하다.
UDP가 TCP보다 빠르다는 것은 set up 과정이 빠른 것이지 얼마나 보내는지에 따라 다르다. 따라서 빠르다는 것에 대한 기준이 애매하다.
TCP가 더 빠를 수도 있다.
'CS > Computer network' 카테고리의 다른 글
| IPv4 Addresses (1) (0) | 2022.04.27 |
|---|---|
| Transmission Control Protocol (TCP) (6) (0) | 2022.04.27 |
| Transmission Control Protocol (TCP) (4) (0) | 2022.04.10 |
| Transmission Control Protocol (TCP) (3) (0) | 2022.04.02 |
| Transmission Control Protocol (TCP) (2) (0) | 2022.03.27 |



