
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- DeepLearning
- Computer Vision
- pytorch
- Object Detection
- cnn 역사
- support vector machine 리뷰
- fast r-cnn
- TCP
- yolov3
- EfficientNet
- Faster R-CNN
- CS231n
- pytorch project
- self-supervision
- darknet
- CNN
- SVM margin
- pytorch c++
- RCNN
- Deep Learning
- yolo
- 데이터 전처리
- 논문분석
- libtorch
- cs231n lecture5
- SVM hard margin
- svdd
- SVM 이란
- computervision
- 서포트벡터머신이란
- Today
- Total
아롱이 탐험대
Implementing the ResNet in pytorch using CIFAR10 dataset 본문
이 글은 convolution neural network에 대한 지식이 있으신 분, ResNet 논문을 이해하신 분, 논문을 이해하였지만 pytorch code로 구현해보고 싶으신 분들께 추천드립니다.
전체 코드는 https://github.com/yunseokddi/pytorch_dev/tree/master/ResNet_pytorch를 참고해주세요.
1. Overview
그동안 기초적인 논문을 읽고 리뷰와 분석을 하였습니다. 논문을 계속 읽을수록 논문의 대한 이해도는 높아졌으나 git hub에 올라온 코드들을 분석해보았을 뿐, 직접 구현을 해본 경험이 없어 이 참에 ResNet을 공부해보면서 pytorch code로 구현을 해보았습니다.
또한 논문만 읽는 것도 재미가 없어졌고, pytorch에 대한 이해도를 높이고 싶었던 이유도 있습니다.
ResNet은 2015년 ILSVRC 대회에서 우승을 한 모델이고, 이후 다양한 논문에서 backbone network로 활약한 네트워크입니다.
기존 vgg net과 google net (inception net)에서는 층을 쌓을 수록 정확도가 높아졌지만 일정 개수 이상 쌓게 되면 degration 문제가 발생하여 정확도가 하락하였습니다.
ResNet에서는 이러한 문제를 Residual learning의 skip connection을 통해 해결하였습니다.
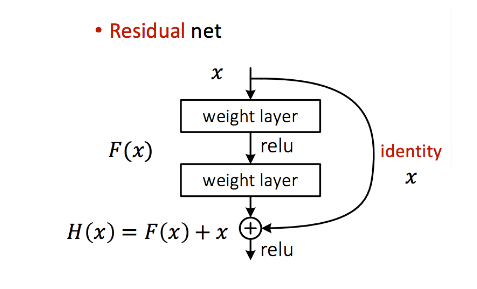
기존의 layer와 달리 shortcut connection은 위 그림처럼 layer 2개를 건너뜁니다. 따라서 layer에 들어온 x가 identity가 되어 일반적인 weight layer (convolution layer)의 출력 값과 element-wise addition을 합니다.
이를 통해 기존 H(x) 학습에서 F(x) 학습으로 바꾸었습니다.
identity를 학습하고자 한다면 간단히 F(x)를 0으로 바꾸면 됩니다. 또한 학습을 한 후 relu activation function을 사용하는데 그 이유는 relu를 통과하면 양수의 값만 남기 때문에 residual의 의미가 제대로 유지되지 않기 때문입니다. batch normalization은 덧셈 전에 사용합니다.
이를 residual block이라고 부릅니다.
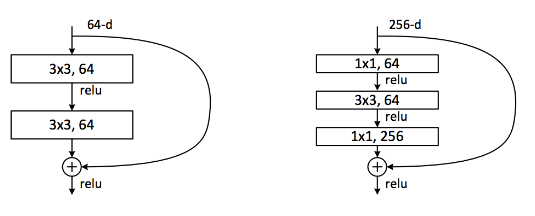
또한 ResNet은 점점 깊어질 수록 parameter의 개수가 늘어나 50층 이후부터는 bottle neck을 도입한 오른쪽과 같은 구조를 사용합니다. 이를 bottleneck block이라고 부릅니다.
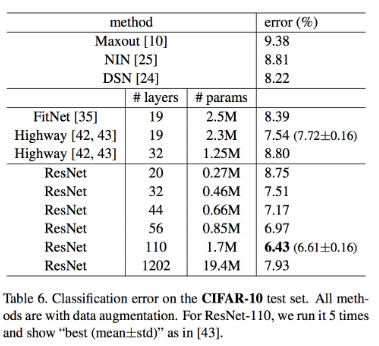
결과를 보게 되면 110 layer가 가장 error가 줄었지만, 1202 layer에서는 여전히 degration 문제가 발생하는 것을 볼 수 있습니다.
우리는 32개의 layer를 가지는 ResNet을 구현할 것 입니다.
2. Development environment
OS: Ubuntu 18.04 LTS
Language: python 3.6.8
Interpreter: pip3
GPU: RTX2070 SUPER
CUDA: 10.2
Library
pytorch: 1.5.0
torchvision: 0.6.0
tensorboardX: 2.0
Dataset: CIFAR10 X
3. Codes
A. model.py
코드 리뷰에 앞서 ResNet class에 대해 한번 눈으로 봐주시기 바랍니다. (코드 전체를 이해할 필요는 없습니다.)
class ResNet(nn.Module):
def __init__(self, num_layers, block, num_classes=10):
super(ResNet, self).__init__()
self.num_layers = num_layers
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)
# feature map size = 32x32x16
self.layers_2n = self.get_layers(block, 16, 16, stride=1)
# feature map size = 16x16x32
self.layers_4n = self.get_layers(block, 16, 32, stride=2)
# feature map size = 8x8x64
self.layers_6n = self.get_layers(block, 32, 64, stride=2)
# output layers
self.avg_pool = nn.AvgPool2d(8, stride=1)
self.fc_out = nn.Linear(64, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out',
nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def get_layers(self, block, in_channels, out_channels, stride):
if stride == 2:
down_sample = True
else:
down_sample = False
layers_list = nn.ModuleList(
[block(in_channels, out_channels, stride, down_sample)])
for _ in range(self.num_layers - 1):
layers_list.append(block(out_channels, out_channels))
return nn.Sequential(*layers_list)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.layers_2n(x)
x = self.layers_4n(x)
x = self.layers_6n(x)
x = self.avg_pool(x)
x = x.view(x.size(0), -1)
x = self.fc_out(x)
return x
자 그럼 ResNet class의 forward부터 살펴보겠습니다.
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.layers_2n(x)
x = self.layers_4n(x)
x = self.layers_6n(x)
x = self.avg_pool(x)
x = x.view(x.size(0), -1)
x = self.fc_out(x)
return xResnet은 layer의 개수에 따라 ResNet-20, ResNet-32, ResNet-44, ResNet-56, ResNet-110으로 나뉘게 됩니다. 이에 따라 n에 해당하는 값도 3, 5, 7, 9, 18에 매칭이 됩니다.
우리가 구현할 ResNet은 ResNet-32이고 이에 매칭 되는 n값은 5입니다.
input x가 들어오게 되면 n값과 상관없이 모든 ResNet들은 conv (3*3) + batch normalize + relu과정을 거치면서 시작합니다.
우리의 input data인 CIFAR10은 RGB로 구성이 되어 있어 3 channel -> 16 channel로 변합니다.
그러고 나서 2n을 통해 16 -> 16 유지, 4n을 통해 16 -> 32, 6n을 통해 32 -> 64로 변하게 되고, global avg pooling과 fc를 거쳐 output이 나오게 됩니다. 만약 in channel과 out channel가 다르면 feature map의 size는 반으로 줄고, channel은 2배가 됩니다. 그 이유는 잠시후에 설명해드리겠습니다.
def __init__(self, num_layers, block, num_classes=10):
super(ResNet, self).__init__()
self.num_layers = num_layers
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)
self.layers_2n = self.get_layers(block, 16, 16, stride=1)
self.layers_4n = self.get_layers(block, 16, 32, stride=2)
self.layers_6n = self.get_layers(block, 32, 64, stride=2)위는 ResNet class의 생성자 함수입니다. 우선 ResNet의 인자는 num_layer: layer의 개수, block: residual block,
num_classes: CIFAR10 data의 class 개수 입니다.
conv1은 위에서 말씀드렸던처럼 RGB 3 channel에서 16 channel로 변환을 해줍니다. 그리고 나서 batch normalization, relu 과정을 거칩니다.
그리고 2n, 4n, 6n을 거치게 됩니다. 여기서 2번째, 3번째 인자인 channel은 residual block에 존재하는 2개의 convolution layer에서 첫 번째 in channel, out channel입니다. 여기서 변수를 2n으로 구분한 이유는 2n개의 layer마다 feature map의 사이즈가 반이 되고, channel수는 2배가 되기 때문입니다.
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, down_sample=False):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.stride = stride
if down_sample:
self.down_sample = IdentityPadding(in_channels, out_channels, stride)
else:
self.down_sample = None
def forward(self, x):
shortcut = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.down_sample is not None:
shortcut = self.down_sample(x)
out += shortcut
out = self.relu(out)
return outResidual block class에서는 layer에서 만약 channel이 다르면 이전 코드 함수 호출처럼 stride parameter를 2로 설정합니다. 그 이유는 shortcut connection으로 전달되는 input x와 2번째 batch normalization을 거친 feature map과의 size가 다르기 때문입니다. 사이즈가 다르기 때문에 down sampling으로 크기를 맞춰줍니다. 이때 CIFAR10 data인 경우 zero sampling을 이용합니다.
그리고 나서 얻은 output과 shortcut x와 + 연산 후에 최종적인 결과값을 return합니다.
class IdentityPadding(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(IdentityPadding, self).__init__()
self.pooling = nn.MaxPool2d(1, stride=stride)
self.add_channels = out_channels - in_channels
def forward(self, x):
out = F.pad(x, (0, 0, 0, 0, 0, self.add_channels))
out = self.pooling(out)
return outIdentityPadding에서는 zero padding을 수행합니다. F.pad는 padding 값을 주는 함수이고 이는 feature map의 마지막 축에 대해 (0, 0)으로 padding, 마지막에서 두 번째 축에 대해서 (0, 0), 세 번째 축에 대해 (0, self.add_channel)만큼 padding을 하라는 의미입니다.
이를 통해 channel 축에 대해 한 방향으로 self.add_channels 만큼 padding이 되어 size가 같아지게 됩니다.
def get_layers(self, block, in_channels, out_channels, stride):
if stride == 2:
down_sample = True
else:
down_sample = False
layers_list = nn.ModuleList(
[block(in_channels, out_channels, stride, down_sample)])
for _ in range(self.num_layers - 1):
layers_list.append(block(out_channels, out_channels))
return nn.Sequential(*layers_list)다시 돌아와서 get_layers 함수에 대해 살펴봅시다.
stride가 2가 되는 4n, 6n layer에서 down sampling이 적용되고, 이를 첫 번째 residual block에서 적용합니다. 나머지 residual block은 일반적인 residual block 구조를 가지게 됩니다.
그리고나서 아래 layers_list를 통해 block들을 sequential하게 리스트화 시킵니다.
def resnet():
block = ResidualBlock
model = ResNet(5, block)
return modelreset을 생성하는 함수입니다. 우리는 ResNet 32-layer를 만들기 때문에 n값을 5로 설정합니다.
model = resnet().to('cuda')
summary(model, (3,32,32))torchsummary를 사용해 우리가 사용하는 data인 CIFAR10과 size를 같게 해줍니다.
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 16, 32, 32] 432
BatchNorm2d-2 [-1, 16, 32, 32] 32
ReLU-3 [-1, 16, 32, 32] 0
Conv2d-4 [-1, 16, 32, 32] 2,304
BatchNorm2d-5 [-1, 16, 32, 32] 32
ReLU-6 [-1, 16, 32, 32] 0
Conv2d-7 [-1, 16, 32, 32] 2,304
BatchNorm2d-8 [-1, 16, 32, 32] 32
ReLU-9 [-1, 16, 32, 32] 0
ResidualBlock-10 [-1, 16, 32, 32] 0
Conv2d-11 [-1, 16, 32, 32] 2,304
BatchNorm2d-12 [-1, 16, 32, 32] 32
ReLU-13 [-1, 16, 32, 32] 0
Conv2d-14 [-1, 16, 32, 32] 2,304
BatchNorm2d-15 [-1, 16, 32, 32] 32
ReLU-16 [-1, 16, 32, 32] 0
ResidualBlock-17 [-1, 16, 32, 32] 0
Conv2d-18 [-1, 16, 32, 32] 2,304
BatchNorm2d-19 [-1, 16, 32, 32] 32
ReLU-20 [-1, 16, 32, 32] 0
Conv2d-21 [-1, 16, 32, 32] 2,304
BatchNorm2d-22 [-1, 16, 32, 32] 32
ReLU-23 [-1, 16, 32, 32] 0
ResidualBlock-24 [-1, 16, 32, 32] 0
Conv2d-25 [-1, 16, 32, 32] 2,304
BatchNorm2d-26 [-1, 16, 32, 32] 32
ReLU-27 [-1, 16, 32, 32] 0
Conv2d-28 [-1, 16, 32, 32] 2,304
BatchNorm2d-29 [-1, 16, 32, 32] 32
ReLU-30 [-1, 16, 32, 32] 0
ResidualBlock-31 [-1, 16, 32, 32] 0
Conv2d-32 [-1, 16, 32, 32] 2,304
BatchNorm2d-33 [-1, 16, 32, 32] 32
ReLU-34 [-1, 16, 32, 32] 0
Conv2d-35 [-1, 16, 32, 32] 2,304
BatchNorm2d-36 [-1, 16, 32, 32] 32
ReLU-37 [-1, 16, 32, 32] 0
ResidualBlock-38 [-1, 16, 32, 32] 0
Conv2d-39 [-1, 32, 16, 16] 4,608
BatchNorm2d-40 [-1, 32, 16, 16] 64
ReLU-41 [-1, 32, 16, 16] 0
Conv2d-42 [-1, 32, 16, 16] 9,216
BatchNorm2d-43 [-1, 32, 16, 16] 64
MaxPool2d-44 [-1, 32, 16, 16] 0
IdentityPadding-45 [-1, 32, 16, 16] 0
ReLU-46 [-1, 32, 16, 16] 0
ResidualBlock-47 [-1, 32, 16, 16] 0
Conv2d-48 [-1, 32, 16, 16] 9,216
BatchNorm2d-49 [-1, 32, 16, 16] 64
ReLU-50 [-1, 32, 16, 16] 0
Conv2d-51 [-1, 32, 16, 16] 9,216
BatchNorm2d-52 [-1, 32, 16, 16] 64
ReLU-53 [-1, 32, 16, 16] 0
ResidualBlock-54 [-1, 32, 16, 16] 0
Conv2d-55 [-1, 32, 16, 16] 9,216
BatchNorm2d-56 [-1, 32, 16, 16] 64
ReLU-57 [-1, 32, 16, 16] 0
Conv2d-58 [-1, 32, 16, 16] 9,216
BatchNorm2d-59 [-1, 32, 16, 16] 64
ReLU-60 [-1, 32, 16, 16] 0
ResidualBlock-61 [-1, 32, 16, 16] 0
Conv2d-62 [-1, 32, 16, 16] 9,216
BatchNorm2d-63 [-1, 32, 16, 16] 64
ReLU-64 [-1, 32, 16, 16] 0
Conv2d-65 [-1, 32, 16, 16] 9,216
BatchNorm2d-66 [-1, 32, 16, 16] 64
ReLU-67 [-1, 32, 16, 16] 0
ResidualBlock-68 [-1, 32, 16, 16] 0
Conv2d-69 [-1, 32, 16, 16] 9,216
BatchNorm2d-70 [-1, 32, 16, 16] 64
ReLU-71 [-1, 32, 16, 16] 0
Conv2d-72 [-1, 32, 16, 16] 9,216
BatchNorm2d-73 [-1, 32, 16, 16] 64
ReLU-74 [-1, 32, 16, 16] 0
ResidualBlock-75 [-1, 32, 16, 16] 0
Conv2d-76 [-1, 64, 8, 8] 18,432
BatchNorm2d-77 [-1, 64, 8, 8] 128
ReLU-78 [-1, 64, 8, 8] 0
Conv2d-79 [-1, 64, 8, 8] 36,864
BatchNorm2d-80 [-1, 64, 8, 8] 128
MaxPool2d-81 [-1, 64, 8, 8] 0
IdentityPadding-82 [-1, 64, 8, 8] 0
ReLU-83 [-1, 64, 8, 8] 0
ResidualBlock-84 [-1, 64, 8, 8] 0
Conv2d-85 [-1, 64, 8, 8] 36,864
BatchNorm2d-86 [-1, 64, 8, 8] 128
ReLU-87 [-1, 64, 8, 8] 0
Conv2d-88 [-1, 64, 8, 8] 36,864
BatchNorm2d-89 [-1, 64, 8, 8] 128
ReLU-90 [-1, 64, 8, 8] 0
ResidualBlock-91 [-1, 64, 8, 8] 0
Conv2d-92 [-1, 64, 8, 8] 36,864
BatchNorm2d-93 [-1, 64, 8, 8] 128
ReLU-94 [-1, 64, 8, 8] 0
Conv2d-95 [-1, 64, 8, 8] 36,864
BatchNorm2d-96 [-1, 64, 8, 8] 128
ReLU-97 [-1, 64, 8, 8] 0
ResidualBlock-98 [-1, 64, 8, 8] 0
Conv2d-99 [-1, 64, 8, 8] 36,864
BatchNorm2d-100 [-1, 64, 8, 8] 128
ReLU-101 [-1, 64, 8, 8] 0
Conv2d-102 [-1, 64, 8, 8] 36,864
BatchNorm2d-103 [-1, 64, 8, 8] 128
ReLU-104 [-1, 64, 8, 8] 0
ResidualBlock-105 [-1, 64, 8, 8] 0
Conv2d-106 [-1, 64, 8, 8] 36,864
BatchNorm2d-107 [-1, 64, 8, 8] 128
ReLU-108 [-1, 64, 8, 8] 0
Conv2d-109 [-1, 64, 8, 8] 36,864
BatchNorm2d-110 [-1, 64, 8, 8] 128
ReLU-111 [-1, 64, 8, 8] 0
ResidualBlock-112 [-1, 64, 8, 8] 0
AvgPool2d-113 [-1, 64, 1, 1] 0
Linear-114 [-1, 10] 650
================================================================
Total params: 464,154
Trainable params: 464,154
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 8.22
Params size (MB): 1.77
Estimated Total Size (MB): 10.00
----------------------------------------------------------------총 32개의 layer이고, parameter의 총용량은 10MB로 모바일에서도 적용이 가능한 것처럼 보입니다.
B) train.py
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torch.backends.cudnn as cudnn
import torchvision
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader
from model import resnet
import argparse
from tensorboardX import SummaryWriter
parser = argparse.ArgumentParser(description='cifar10 classification models')
parser.add_argument('--lr', default=0.1, help='')
parser.add_argument('--resume', default=None, help='')
parser.add_argument('--batch_size', default=128, help='')
parser.add_argument('--batch_size_test', default=100, help='')
parser.add_argument('--num_worker', default=4, help='')
parser.add_argument('--logdir', type=str, default='logs', help='')
args = parser.parse_args()
transforms_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transforms_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
dataset_train = CIFAR10(root='../data', train=True,
download=True, transform=transforms_train)
dataset_test = CIFAR10(root='../data', train=False,
download=True, transform=transforms_test)
train_loader = DataLoader(dataset_train, batch_size=args.batch_size,
shuffle=True, num_workers=args.num_worker)
test_loader = DataLoader(dataset_test, batch_size=args.batch_size_test,
shuffle=False, num_workers=args.num_worker)
classes = ('plane', 'car', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck')
net = resnet()
net = net.to('cuda')
num_params = sum(p.numel() for p in net.parameters() if p.requires_grad)
if args.resume is not None:
checkpoint = torch.load('./save_model/' + args.resume)
net.load_state_dict(checkpoint['net'])
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.1,
momentum=0.9, weight_decay=1e-4)
decay_epoch = [32000, 48000]
step_lr_scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=decay_epoch, gamma=0.1)
writer = SummaryWriter(args.logdir)
def train(epoch, global_steps):
net.train()
train_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(train_loader):
global_steps += 1
step_lr_scheduler.step()
inputs = inputs.to('cuda')
targets = targets.to('cuda')
outputs = net(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
acc = 100 * correct / total
print('train epoch : {} [{}/{}]| loss: {:.3f} | acc: {:.3f}'.format(
epoch, batch_idx, len(train_loader), train_loss / (batch_idx + 1), acc))
writer.add_scalar('log/train error', 100 - acc, global_steps)
return global_steps
def test(epoch, best_acc, global_steps):
net.eval()
test_loss = 0
correct = 0
total = 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(test_loader):
inputs = inputs.to('cuda')
targets = targets.to('cuda')
outputs = net(inputs)
loss = criterion(outputs, targets)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
acc = 100 * correct / total
print('test epoch : {} [{}/{}]| loss: {:.3f} | acc: {:.3f}'.format(
epoch, batch_idx, len(test_loader), test_loss / (batch_idx + 1), acc))
writer.add_scalar('log/test error', 100 - acc, global_steps)
if acc > best_acc:
print('==> Saving model..')
state = {
'net': net.state_dict(),
'acc': acc,
'epoch': epoch,
}
if not os.path.isdir('save_model'):
os.mkdir('save_model')
torch.save(state, './save_model/ckpt.pth')
best_acc = acc
return best_acc
if __name__ == '__main__':
best_acc = 0
epoch = 0
global_steps = 0
if args.resume is not None:
test(epoch=0, best_acc=0)
else:
while True:
epoch += 1
global_steps = train(epoch, global_steps)
best_acc = test(epoch, best_acc, global_steps)
print('best test accuracy is ', best_acc)
if global_steps >= 64000:
break
train 코드는 pytorch를 아시는 분들이라면 쉽게 해석을 하실 수 있을꺼라 생각합니다.
criterion의 경우 SGD를 사용했으나, Adam 등 다른 criterion을 사용해도 무관합니다.
4. Result
Epoch 95 | Train set - Avarage loss: 0.2603
Epoch 95 | Test set - Average loss: 0.2458, Accuracy: 103/120 (86%)
108it [00:00, 385.18it/s]
Epoch 96 | Train set - Avarage loss: 0.2571
Epoch 96 | Test set - Average loss: 0.2452, Accuracy: 106/120 (88%)
108it [00:00, 394.88it/s]
Epoch 97 | Train set - Avarage loss: 0.2583
Epoch 97 | Test set - Average loss: 0.2430, Accuracy: 108/120 (90%)
108it [00:00, 388.35it/s]
Epoch 98 | Train set - Avarage loss: 0.2584
Epoch 98 | Test set - Average loss: 0.2459, Accuracy: 104/120 (87%)
108it [00:00, 392.04it/s]
Epoch 99 | Train set - Avarage loss: 0.2574
Epoch 99 | Test set - Average loss: 0.2454, Accuracy: 106/120 (88%)
108it [00:00, 388.22it/s]
Epoch 100 | Train set - Avarage loss: 0.2567
Epoch 100 | Test set - Average loss: 0.2446, Accuracy: 106/120 (88%)정확도는 90% 정도인 것을 알 수 있습니다.
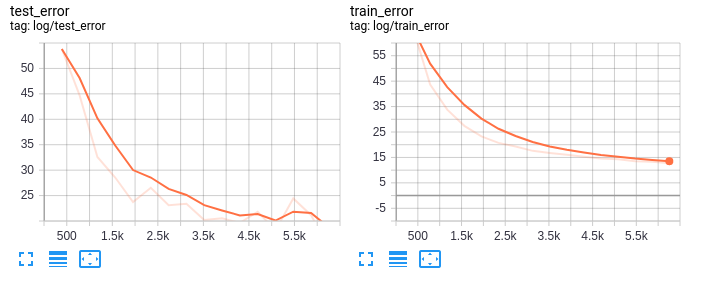
tensorboard 상에서도 degration 문제 없이 학습이 잘 된것으로 보입니다.
5. Reference
ResNet paper: https://arxiv.org/pdf/1512.03385.pdf
코드, 내용 참고: https://dnddnjs.github.io/cifar10/2018/10/09/resnet/
'Project > pytorch' 카테고리의 다른 글
| 얼굴 나이 인식기 개발 - 3 data load check code (Using EfficientNet with Pytorch) (0) | 2020.09.15 |
|---|---|
| 얼굴 나이 인식기 개발 -2 data preprocess (2) (Using EfficientNet with Pytorch) (0) | 2020.09.10 |
| 얼굴 나이 인식기 개발 - 1 data preprocess (1) (Using EfficientNet with Pytorch) (0) | 2020.09.08 |
| YOLOv3 custom data 학습시키기 (custom data 처리) (0) | 2020.08.24 |
| [pytorch+opencv] 졸음 감지 프로그램 (sleepy eyes detector) (21) | 2020.06.17 |



