
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Object Detection
- cs231n lecture5
- 데이터 전처리
- Deep Learning
- self-supervision
- yolov3
- svdd
- computervision
- yolo
- Computer Vision
- SVM hard margin
- CNN
- support vector machine 리뷰
- fast r-cnn
- DeepLearning
- TCP
- EfficientNet
- cnn 역사
- pytorch c++
- libtorch
- RCNN
- SVM margin
- pytorch project
- 서포트벡터머신이란
- Faster R-CNN
- darknet
- 논문분석
- CS231n
- pytorch
- SVM 이란
- Today
- Total
아롱이 탐험대
YOLOv3 custom data 학습시키기 (custom data 처리) 본문
현재 진행 중인 AR 기반 스마트 팽이 애플리케이션 (국가 과제)를 개발하면서 작성한 문서이다.
객체는 스마트 팽이를 기반으로 설정하겠다. (다른 객체를 적용해도 상관없다.)
아래 yolov3 pytorch version을 기반으로 데이터 처리를 하였다.
https://github.com/eriklindernoren/PyTorch-YOLOv3
eriklindernoren/PyTorch-YOLOv3
Minimal PyTorch implementation of YOLOv3. Contribute to eriklindernoren/PyTorch-YOLOv3 development by creating an account on GitHub.
github.com
우리의 신경망 모델의 목표는 팽이를 인식하여 gpu 서버를 통해 어플리케이션에 스마트 팽이에 해당하는 객체의 좌표 값을 전송해주는 것이다.
데이터가 너무 많아도 라벨링 단계에서 시간이 많이 소요됨으로 적절한 학습 데이터의 양과 테스트 데이터의 양이 필요하다.
우리의 신경망 모델은 처음부터 끝까지 스마트 팽이의 데이터로 학습하는 것이 아니라 다른 누군가가 학습한 가중치를 가지고 transfer learning 또는 fine tuning 기법을 사용하여 학습시킨다.
Transfer learning과 fine tuning 기법은 다른 글(CS231N 강의)에서 살펴본 바가 있다.
다양한 배경의 스마트 팽이 이미지가 많으면 좋지만, 한정된 공간에서 다양한 데이터를 창출하기 위해서는 다른 방법을 사용할 수 있다.
Pytorch 딥러닝 프레임워크에서는 무작위 crop, 무작위 resize, 무작위 horizon 등 하나의 이미지에 대해 다양한 데이터를 창출할 수 있게 도와주는 함수들이 정의되어 있다.
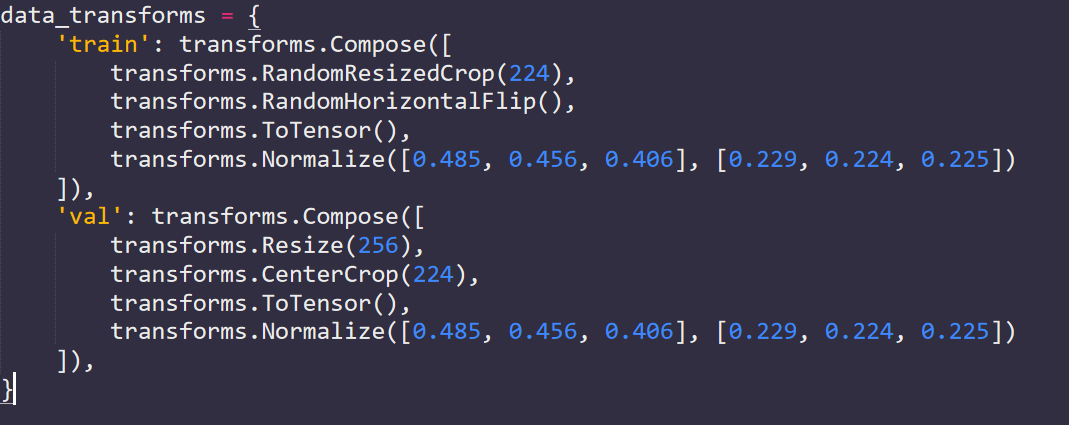
위에서 해당되는 코드는 transforms.RandomResizeCrop(), transforms.RandomHorizontalFlip()이다.
이제부터 본격적으로 스마트 팽이 데이터를 생성해보자.
수많은 이미지들을 직접 촬영하는 것보다 동영상을 촬영하여 프레임만큼 비디오를 나누고 이를 jpg로 저장하는 것이 훨씬 효율적이다.
따라서 아래 코드 이용하여 mp4 file을 프레임으로 나누어 jpg file을 생성하였다.
import cv2
import time
cap = cv2.VideoCapture('./video/example.mp4')
FPS = 35
prev_time = 0
count = 0
while True:
ret, image = cap.read()
if not ret:
break
current_time = time.time() - prev_time
if (ret is True) and (current_time > 1. / FPS):
prev_time = time.time()
cv2.imwrite('./image/' + str(count) + '.jpg', image)
count += 1Opencv의 VideoCapture 함수를 통해 비디오를 호출하고, 이를 fps 즉 나누고자 하는 프레임을 설정한 후에 count 변수를 사용하여 각 이미지들을 count 순으로 저장하였다.
Count 변수는 본인의 이미지가 시작하는 index 순으로 설정하면 된다. 또한 fps도 본인이 원하는 데이터의 수량에 따라 설정하면 된다.
총 8개의 다른 장소에서 촬영한 비디오를 1200장의 이미지로 나누었다.

1200장의 스마트 팽이의 이미지들을 라벨링을 진행해야 한다.
라벨링은 말그대로 우리가 학습시키고 싶은 객체에 직접 x, y, w, h 등의 좌표를 통해 사각형 영역을 표시하는 과정이다.
대표적인 라벨링 포맷
- COCO format
- YOLO format
- PASCAL VOC format
위 3개가 가장 유명한 라벨링 포맷이고, 라벨링 포맷은 여러가지 존재한다. 하지만 사용할 모델에 따라, 데이터 구조, 처리에 대한 편이에 따라 선정하는 라벨링 포맷이 달라지기도 한다.
또한 라벨링 포맷에 따라 annotation 즉 객체의 좌표 표현법과 object의 label의 대한 형식이 달라지고, 이를 저장한 파일 형식자도 달라진다.
PASCAL VOC format 이 가장 대중적으로 사용되고, 라벨링의 편이를 위한 gui 프로그램들이 제공되어서 PASCAL VOC format으로 라벨링을 진행하기로 결정하였다.
PASCAL VOC의 폴더 구조는 아래와 같은 형식으로 구성되어 있다.
(참고: https://deepbaksuvision.github.io/Modu_ObjectDetection/posts/02_02_Convert2Yolo.html)
VOC20 XX
├── Annotations
├── ImageSets
├── JPEGImages
├── SegmentationClass
└── SegmentationObject
Annotations: JPEGImages 폴더 속 원본 이미지와 같은 이름들의 xml파일들이 존재한다. Object Detection을 위한 정답 데이터가 된다
ImageSets : 어떤 이미지 그룹을 test, train, trainval, val로 사용할 것인지, 특정 클래스가 어떤 이미지에 있는지 등에 대한 정보들을 포함하고 있는 폴더이다.
JPEGImages : *. jpg확장자를 가진 이미지 파일들이 모여있는 폴더이다. Object Detection에서 입력 데이터가 된다.
SegmentationClass : Semantic segmentation을 학습하기 위한 label 이미지이다..
SegmentationObject : Instance segmentation을 학습하기 위한 label 이미지이다.
Object Detection을 할 때는 주로 Annotations, JPEGImages폴더가 사용된다.
모델에 입력으로 넣는 입력 데이터인 경우 그냥 load 해서 사용하면 되나, 지도 학습에 핵심이 되는 정답 데이터의 경우는 parsing이 필요한 경우가 있으므로 Annotations의 *.xml 구조는 잘 알아두는 것이 중요하다.
Xml 파일의 구조
<size> : xml파일과 대응되는 이미지의 width, height, channels 정보에 대한 tag이다.
<width> : xml파일에 대응되는 이미지의 width값이다.
<height> : xml파일에 대응되는 이미지의 height값이다.
<depth> : xml파일에 대응되는 이미지의 channels값이다.
<object> : xml파일과 대응되는 이미지 속에 object의 정보에 대한 tag이다.
<name> : 클래스 이름을 의미한다.
<bndbox> : 해당 object의 바운딩 상자의 정보에 대한 tag이다.
xmin : object 바운딩 상자의 왼쪽상단의 x축 좌표값이다.
ymin : object 바운딩상자의 왼쪽상단의 y축 좌표값이다.
xmax : object 바운딩 상자의 우측 하단의 x축 좌표값이다.
ymax : object 바운딩상자의 우측하단의 y축 좌표값이다.
라벨링을 진행한 툴은 labelImg를 사용하였다. (https://github.com/tzutalin/labelImg)
사용법은 github의 README.md를 참고하면 된다.
labelImg는 VOC format과 YOLO format을 지원하고, github에서 clone을 진행한 뒤 python으로 실행하면 되는 간단명료한 오픈 소스 툴이다.
우리는 이전에 설명했던 바와 같이 VOC format으로 라벨링을 진행할 것이다.

labelme 프로그램으로 VOC format으로 annotation을 저장한 이유는 가장 대중적인 data format이 VOC이고, VOC format 기준으로 다른 format으로 변환을 도와주는 tool이 많기 때문이다.
정리하여 말하면 내가 사용할 yolo v3로 학습시켜 만약 정확도가 좋지 않다면 다른 object detection 모델에 학습을 시키기 위함이다.
Git hub에 올라온 convert2Yolo를 참고하여 format을 변경할 수 있었다.
(https://github.com/ssaru/convert2Yolo)
voc = VOC()
yolo = YOLO(os.path.abspath(config["cls_list"]))
flag, data = voc.parse(config["label"])
if flag == True:
flag, data = yolo.generate(data)
if flag == True:
flag, data = yolo.save(data, config["output_path"], config["img_path"] ,
config["img_type"], config["manipast_path"])
if flag == False:
print("Saving Result : {}, msg : {}".format(flag, data))
else:
print("YOLO Generating Result : {}, msg : {}".format(flag, data))
else:
print("VOC Parsing Result : {}, msg : {}".format(flag, data))코드를 살펴보면 voc 객체를 생성한 뒤 YOLO 객체를 cls_list 파일 (*.name) 파라미터로 생성한다.
그 후 voc 인스턴스를 이용하여 parsing 작업을 수행한 후 yolo 인스턴스를 이용하여 이를 yolo format으로 변경해준다. 그리고 마지막에 yolo format으로 변경된 데이터를 저장한다.
지금까지 voc annotation format을 yolo의 annotation format으로 변환시켰다.

yolo format의 annotation은 voc보다 비교적 매우 간단하다.
첫 번째 0이 label의 해당하는 index (데이터의 label은 팽이 1개이므로 모든 객체의 index가 0이다), 그다음은 각각 x, y, width, height의 값을 의미한다. 또한 각 개수는 이미지 1장에 존재하는 팽이의 개수를 의미한다.
이렇게 yolo format에 맞게 데이터를 준비하였으면 다음은 train, validation의 비율을 지정해야 한다. 원래는 test data set도 포함시켜야 되지만, 우리의 data set은 양이 적고, test 보다는 validation으로 평가해도 괜찮은 problem이라 제외하였다.
train data set과 validation dataset의 비율은 가장 보편적인 0.8 : 0.2를 적용시켜 각 960, 241장으로 구성하였다.
train set과 validation set을 나눌 때는 순차적인 index로 0.jpg ~ 960.jpg를 train set으로 설정하는 것보다 난수로 정한 960개의 random index에 해당하는 이미지로 설정하는 것이 더 좋다. 우리의 data는 동영상을 이미지로 변환시킨 데이터라 인접한 index의 이미지는 서로 연속적인 이미지이기 때문에 랜덤으로 정한 이미지들이 훨씬 더 효과가 좋다.
난수는 rand 함수를 사용하여 설정을 하였고, 해당 index에 해당하는 파일의 상대 경로는 아래 코드를 이용하여 생성하였다.
f = open('./label/train.txt', 'r')
while True:
data = f.readline()
if not data:
break
print('data/custom/images/'+data.strip('\n')+'.jpg')
f.close()
해당 코드를 실행시키면 결괏값으로 해당 train, val의 텍스트 파일에 해당하는 인덱스의 상대 주소를 추출할 수 있다.
그리고 마지막 데이터 처리인 classes,.names라는 yolo 모델에서 각 index에 맞게 알맞은 class name을 정의해준다.
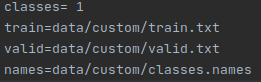
마지막으로./config/custom.data 파일에 class의 개수, train, vlaidation의 해당하는 경로를 저장한 txt 파일, 바로 위에서 정의한 classes.names 파일의 경로를 정의하면 된다.
자 이제 yolov3에서 custom data를 학습할 준비가 완료되었다.
'Project > pytorch' 카테고리의 다른 글
| 얼굴 나이 인식기 개발 - 3 data load check code (Using EfficientNet with Pytorch) (0) | 2020.09.15 |
|---|---|
| 얼굴 나이 인식기 개발 -2 data preprocess (2) (Using EfficientNet with Pytorch) (0) | 2020.09.10 |
| 얼굴 나이 인식기 개발 - 1 data preprocess (1) (Using EfficientNet with Pytorch) (0) | 2020.09.08 |
| Implementing the ResNet in pytorch using CIFAR10 dataset (2) | 2020.06.24 |
| [pytorch+opencv] 졸음 감지 프로그램 (sleepy eyes detector) (20) | 2020.06.17 |



