
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- yolov3
- SVM hard margin
- libtorch
- DeepLearning
- support vector machine 리뷰
- pytorch project
- SVM 이란
- Object Detection
- CS231n
- Deep Learning
- pytorch
- 데이터 전처리
- 논문분석
- CNN
- pytorch c++
- fast r-cnn
- darknet
- SVM margin
- self-supervision
- Faster R-CNN
- cnn 역사
- Computer Vision
- cs231n lecture5
- 서포트벡터머신이란
- computervision
- svdd
- EfficientNet
- yolo
- RCNN
- TCP
- Today
- Total
아롱이 탐험대
[Dimensionality Reduction] Overview 본문
본 포스트는 고려대학교 산업경영공학부 강필성 교수님의 Business Analytics 강의를 정리한 내용입니다.
Dimensionality Reduction이란
original data의 차원을 줄이면서 prediction model의 성능을 최대한으로 유지하는 기법이다.
차원 축소를 하는 이유는 무엇일까? 현실 세계에 존재하는 데이터는 대부분 고차원으로 형성이 되어있다.
예를 들어 넷플릭스 추천 시스템을 생각해보자. 각 유저에 마다 즐겨 찾는 카테고리, 최근 시청 기록, 선호하는 미디어, etc 등 수많은 차원으로 구성되어 있다. 궁극적으로 추천 시스템을 만드는 데 있어 모든 변수를 고려할 필요는 없다. 다양한 변수 중 중요한 변수도 있고, 필요 없는 변수들도 있다. 따라서 우리는 효율적인 변수만 채택해 모델링을 해야 한다.
또한 Occam's Razor에서 더 적은 수의 논리로 설명이 가능하면, 많은 수의 논리를 세우지 말자라는 단순성의 원리가 존재하는데 이를 차원 축소로 빗대어 표현하면 변수의 개수가 늘어날 때 동일한 설명력을 갖기 위해서 필요한 instance의 수는 지수적으로 늘어난다.

점과 점 사이의 거리가 1 임을 설명하려면 1차원에서는 위 이미지 맨 왼쪽과 같이 점 2개로 설명이 가능하다. 하지만 2차원에서는 점이 4개 필요하고, 3차원에서는 8개가 필요하게 된다.
이를 수식으로 일반화하면 d차원에서는 $2^d$ 만큼의 점이 있어야 한다.
결론적으로는 만약 어떤 현상에 대한 설명할 수 있는 방법들이 있다면 가장 단순한 것이 좋다. 이를 인공 지능에서는 똑같이 예측할 수 있는 모델에서는 더 심플한 것이 좋다는 의미이다.
때때로 instance에 본질적인 정보를 저장하는 내재적 차원의 수는 실제 차원보다는 적을 수도 있다. 예를 들어 mnist와 숫자 필기체 데이터를 구분한다 할 때 256차원의 데이터를 PCA와 같은 차원 축소 알고리즘을 통해 2차원으로 줄일 수 있다.

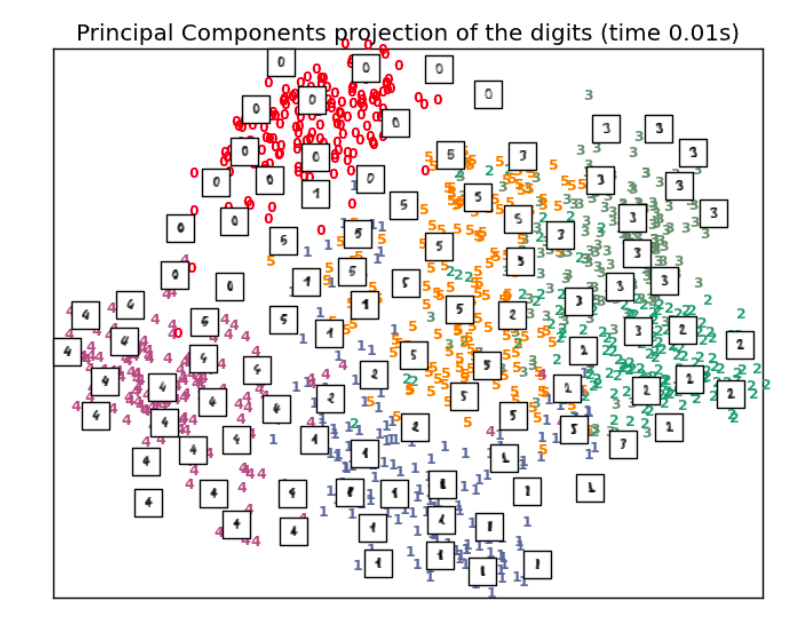
High dimension이 일으킬 수 있는 문제들은 다양하다. 우선 data에 noise가 발생할 수 있다. 이는 필요 없는 data 및 변수가 존재한다는 의미이고, 이는 모델 예측에 있어 성능을 낮춘다. 또한 연산량도 자연스럽게 증가하고, 해당 instance를 설명하는 변수가 증가하게 된다.
High dimension에 대한 해결책도 존재한다. 해당 데이터에 대한 전문가를 통해 domain knowledge를 활용하거나 objective function의 regularization 기법 활용 및 차원 축소 알고리즘 활용 등이 있다.
예측 모델에서는 이론상 변수 간 독립일 때 모델의 성능은 향상되지만, 현실에서는 거의 불가능하다. 현실에 있는 대부분의 데이터 및 변수들은 다양한 환경에 적용받고, 이에 대한 상관관계를 맺고 있기 때문이다. 따라서 현실에서는 변수 간 의존성 및 노이즈와 같은 이유로 모델의 성능이 낮아진다.
따라서 우리의 목표는 모델에 적합한 변수의 subset을 찾아야 하고, 이를 통해 변수 간 상관관계를 최대한 없애야 하고, preprocessing 과정을 통해 불필요한 변수 제거를 해야 한다.
차원이 축소되면 추가적으로 데이터를 시각화하여 표현할 수 있다. (ex. 위 mnist 그림 오른쪽)
이제 본격적으로 차원 축소 알고리즘을 살펴보자. 차원 축소 알고리즘은 특정한 학습 알고리즘의 개입 여부에 따라 2가지 분류로 나뉜다.
1. Supervised Dimensionality Reduction

Supervised Dimensionality Reduction은 데이터 마이닝과 같은 머신 러닝 알고리즘이 사용되어 차원 축소를 진행한다. learning algorithm에서 supervised feature selection으로 가는 feed-back loop가 존재한다.
2. Unsupervised Dimensionality Reduction
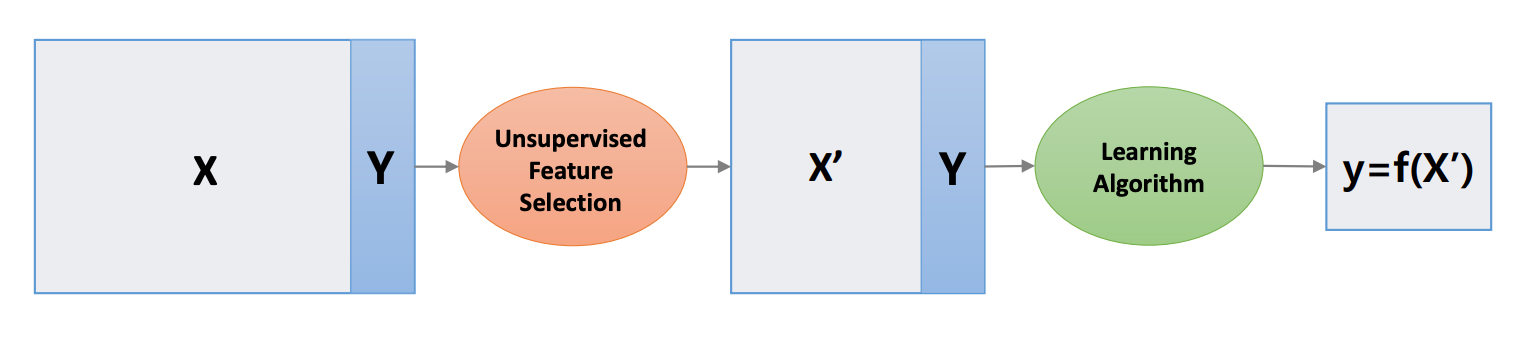
Unsupervised Dimensionality Reduction에서는 더 적은 차원에서 분산, 거리와 같은 정보들을 보존할 수 있는 좌표계 셋을 찾는다.
process 중에는 데이터 마이닝을 사용하지 않고, feed-back loop가 존재하지 않는다.
위 방법 뿐만 아니라 축소된 결과물에 대해서 구별할 수 있다.
1. Variable/feature selection
- 특정한 기준에 의해 원래 있던 변수 중 몇 가지를 남긴다. (subset을 선택)
2. Variable/feature extraction
- 차원은 축소시키면서 의미 있는 새로운 변수를 만든다.
이 두가지 방법의 차이는 결과로 나온 축소된 값들이 subset인지 아니면 새롭게 생성한 variable인지이다.
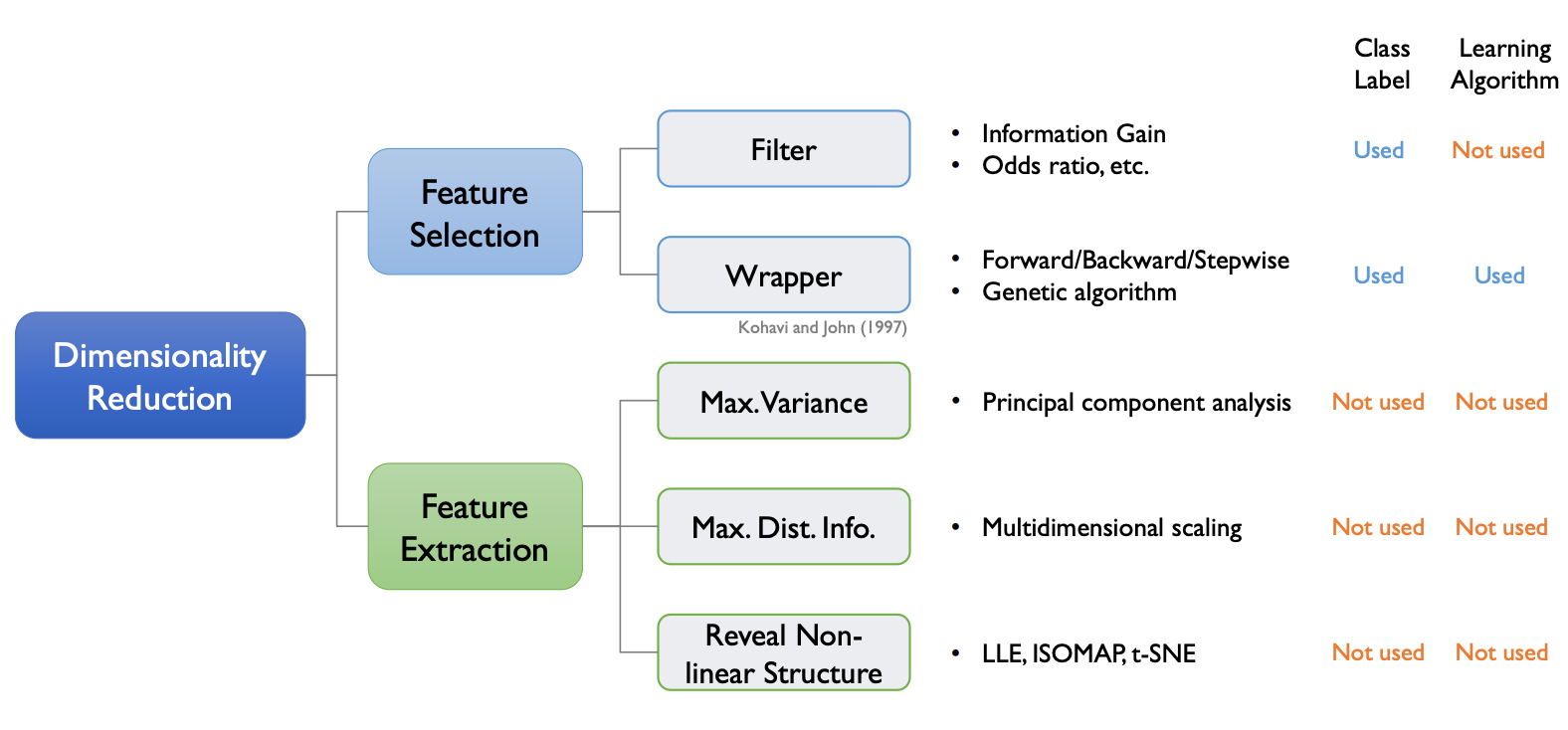
사용되는 테크닉에 따라 위 그래프처럼 나눌 수 있다.
Feature Extraction에서는 original 변수의 정보량을 최대한으로 보존하면서 차원을 축소한다는 성질을 가지고 있다. 여기서 핵심은 데이터가 가지고 있는 본질적인 정보가 어떤 것이냐 이다.
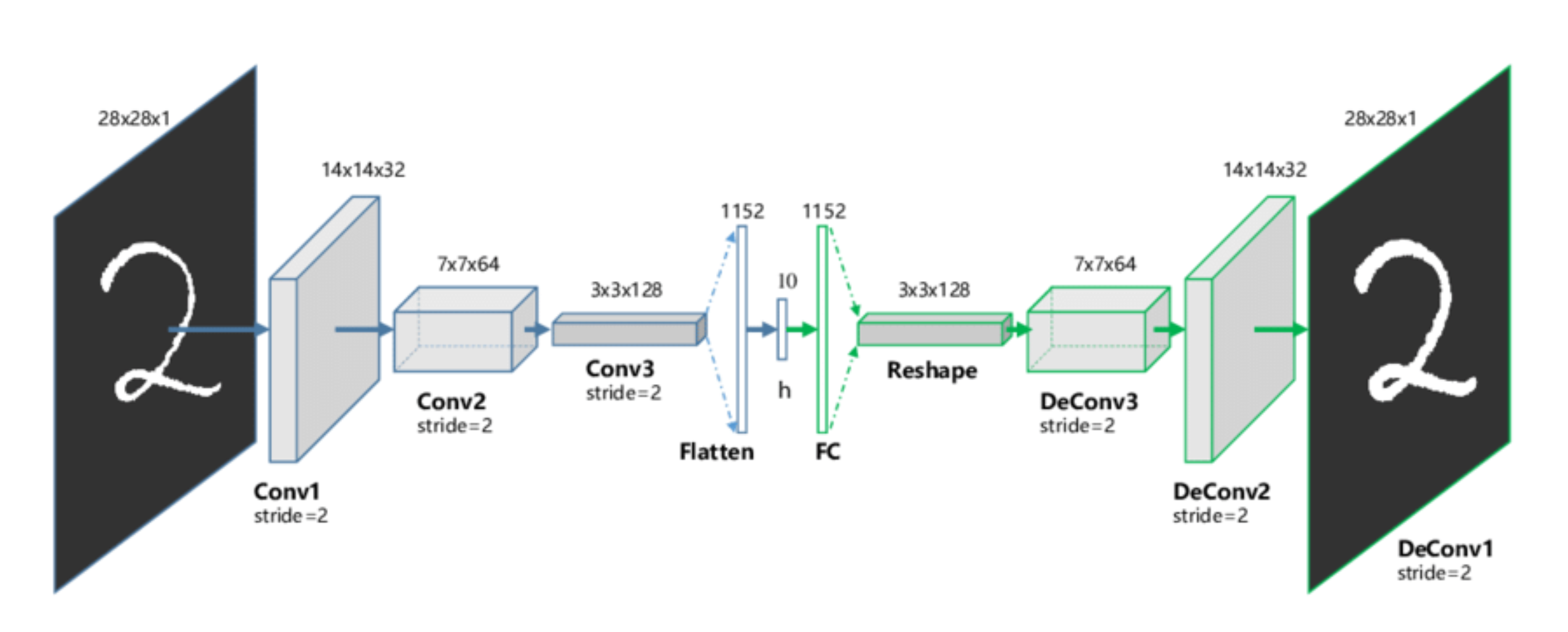
위와 같은 신경망 구조를 AE (Auto Encoder) 구조라고 하는데 이는 원래의 데이터를 차원을 줄이고, 줄여진 latent vector가 원래 데이터의 본질적인 정보를 갖고 있을 것이라고 가정한다.
해당 latent vector는 원래 이미지를 잘 구현하도록 original data에 대한 정보를 더 잘 담게 된다.
'study > IME654' 카테고리의 다른 글
| [Anomaly Detection] Distance, Clustering, PCA-based Methods (0) | 2022.07.11 |
|---|---|
| [Anomaly Detection] Parzen Window Density Estimation (0) | 2022.07.10 |
| [Anomaly Detection] Gaussian Density Estimation & Mixture of Gaussian Density Estimation (0) | 2022.07.08 |
| [Anomaly Detection] Local Outlier Factor (LOF) (0) | 2022.07.07 |
| [Anomaly detection] Overview (0) | 2022.04.29 |



