
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 논문분석
- yolo
- cnn 역사
- svdd
- SVM margin
- cs231n lecture5
- computervision
- darknet
- EfficientNet
- Faster R-CNN
- RCNN
- 서포트벡터머신이란
- pytorch
- yolov3
- self-supervision
- Deep Learning
- pytorch c++
- TCP
- CNN
- libtorch
- support vector machine 리뷰
- SVM 이란
- Computer Vision
- CS231n
- pytorch project
- 데이터 전처리
- Object Detection
- SVM hard margin
- DeepLearning
- fast r-cnn
- Today
- Total
아롱이 탐험대
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 본문
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
ys_cs17 2020. 3. 16. 15:47Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
-Shaoqing Ren∗ Kaiming He Ross Girshick Jian Sun-
1. Introduction
지금까지 Faster R-CNN을 이해하기 위해 R-CNN, Fast R-CNN, VGG16에 대해 분석을 했다. 크게 보면 Fast R-CNN과 Faster R-CNN의 구조는 처음 특정 region을 찾는 단계에서 차이가 있다. 기존 Fast R-CNN에서는 Selective search를 사용하여 이 과정에서 약 2초 정도 delay가 생겨 real time에는 적용하기 힘들었다. 하지만 Faster R-CNN에서는 이 과정을 보완하고자 새롭게 등장한 RPN이라는 알고리즘이 사용되어 real-time (1초에 약 18 frame)에는 미치지 못하지만 이미지 한 장당 0.2초 즉 1초당 5 frame정도까지의 결과를 도출할 수 있었다. 그럼 이제부터 Faster R-CNN에 대해 분석해보자
2. Network
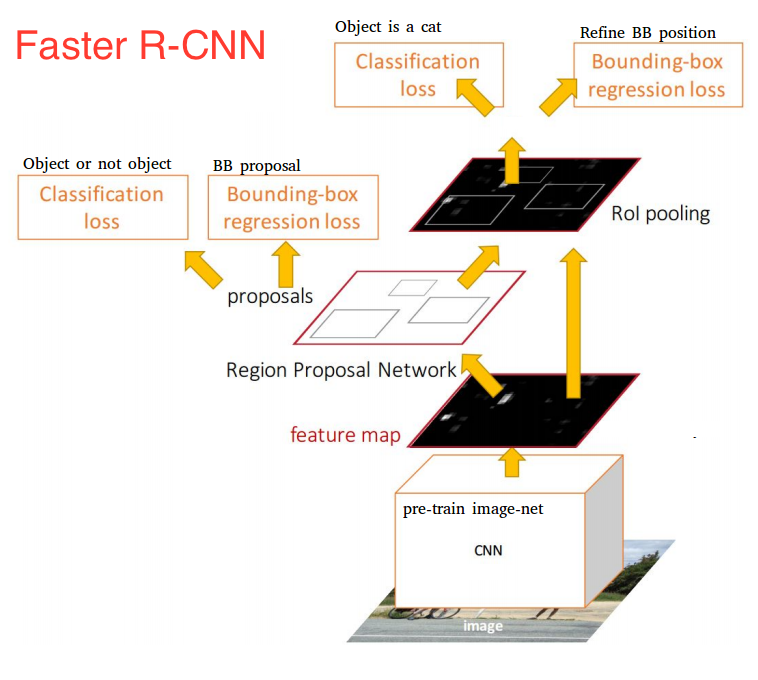
앞서 말한바와 같이 Faster R-CNN과 Fast R-CNN의 차이점은 region proposal 정도이다. 하지만 해당 단계의 알고리즘을 변경한 후 시간에 대한 결과는 크게 차이가 있었다.
그러면 이제 selective search에서 무슨 알고리즘으로 변경이 되었는지 분석해보자

RPN(Region Proposal Network)의 전체적인 구조는 우선 처음 input으로 size가 800*800*3인 image가 학습이 된 base network에 들어가서 feature map을 뽑게 된다. 여기서 사용되는 network의 종류는 다양하지만 해당 논문에서는 VGG16 기준으로 base network를 사용했다. 그 후 base network에서 나온 feature map을 RPN에 input으로 집어넣는다. Input의 size는 VGG 기준으로 50*50*512가 된다. 이 input들을 Sliding window라는 기법을 사용해 size가 3*3인 window로 sliding 시킨다. 이 window가 찍은 지점마다 한 번에 여러 개의 region proposal를 예측하게 되는데 이것의 최고 개수는 k라고 부르며 이것을 Anchor라고 부른다. 여기서 Anchor box는 총 9개의 종류가 있는데 그 이유는 각 scale이 3개 (8,16,32), ratio가 3개 (0.5,1,2)이기 때문에 3*3=9 개가 된다.

이 결과로 생성된 feature map의 depth는 512에서 256으로 줄게 되고, 이후 output은 1*1 kernel을 같고 있는 2개의 convolution layer로 나누어 들어가게 된다.
또한 여기서 Anchor box는 50*50*9 = 22500개가 만들어 지는데 이 22500개의 Anchor box를 가지고 input으로 들어온 image가 Anchor의 image와 일치하는지 불일치하는지 labeling 해주어야 한다. 여기서 쓰인 labeling 기준은 IoU(Intersection over Union)이라고 한다.
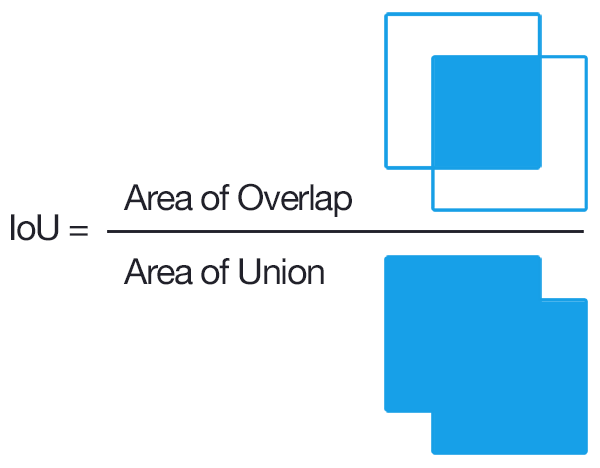
해당 수식은 너무 단순해 설명은 생략한다.

IoU의 결과값으로 해당 기준식을 적용하여 Ground Truth label을 구성한다. 해당 기준점은 사용자 마음대로 변경이 가능하다.
그다음은 아까 convolution layer를 거치고 나온 feature map은 1*1 conv인 bbox Regression layer와 classification layer를 통해 bounding box 위치와 class를 예측한다. 따라서 output은 각각 (22500,4), (22500,2)가 나오게 되고 이 값들과 방금 구한 Ground Truth label을 통해 loss를 구하게 된다. 이와 동시에 예측된 값들은 NMS를 거쳐 특정 개수의 ROI로 sampling 된 후, Fast R-CNN과 똑같은 방식으로 FC과정을 거치게 된다.


Lcls는 log loss를 사용하였고, L1은 fast R-CNN과 같은 L1 loss를 사용한다.
또한 NMS(Non maximum suppression)은 검출된 bound box에서 overlapping 된 다른 bound box들을 제거한다. 알고리즘에 대해 간단하게 설명화면 Roi후 가장 높은 proposal과 다른 proposal에 대해 비교한 후 overlapping 된 bound box가 특정 threshold를 넘어가면 제거하는 방식이다.

3. result
결론적으로 faster R-CNN은 기존 fast R-CNN에 비해 속도와 mAP면에서 월등하다고 말할 수 있다. (2second->0.2second, 66.9%->69.9%) 하지만 앞서 말했던 것처럼 아직 Faster R-CNN은 real time으로 적용시키기는 힘들다. 하지만 real time에 작동되는 object detection이 나오게 되는데 그게 바로 그 유명한 YOLO network이다.
다음에는 YOLO를 분석해보겠다.
4. reference
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (paper)
'study > paper reviews' 카테고리의 다른 글
| SSD: Single Shot Multibox Detector (0) | 2020.03.23 |
|---|---|
| YOLO: You Only Look Once: Unified, Real-Time Object Detection (0) | 2020.03.18 |
| VGG NET: Very Deep Convolution Networks For Large-Scale Image Recognition (0) | 2020.03.13 |
| Fast R-CNN (0) | 2020.03.13 |
| R-CNN: Rich feature hierarchies for accurate object detection and semantic segmentation (0) | 2020.03.12 |



