
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- fast r-cnn
- libtorch
- cs231n lecture5
- 데이터 전처리
- Object Detection
- support vector machine 리뷰
- RCNN
- svdd
- computervision
- 서포트벡터머신이란
- yolov3
- cnn 역사
- yolo
- SVM 이란
- Faster R-CNN
- Deep Learning
- CNN
- 논문분석
- pytorch c++
- DeepLearning
- CS231n
- EfficientNet
- pytorch project
- pytorch
- TCP
- SVM margin
- SVM hard margin
- self-supervision
- darknet
- Computer Vision
- Today
- Total
아롱이 탐험대
SSD: Single Shot Multibox Detector 본문
SSD: Single Shot Multibox Detector
-Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg-
1. Introduction

이전 분석하였던 YOLO는 real time에 적용할 수 있는 object detector model이다. 하지만 YOLO는 input을 7*7 grid로 나눈 후 각 grid 별로 bounding box prediction을 진행하기 때문에 grid보다 작은 물체를 detecting하기에 힘든 점이 있다. 또한 맨 마지막 output은 convolution과 pooling 과정을 거친 후 마지막에 남은 feature만을 보고 판단하기 때문에 정확도가 낮아질 수밖에 없다. 따라서 같은 시기에 나온 Faster R-CNN보다는 정확도가 떨어진다는 단점이 존재한다. 이 점을 보완하고자 YOLO와 Faster R-CNN (이 두 모델은 2015년 5월에 나온 논문이다.)의 장점들만 합쳐 만들어진 SSD (Single Shot Multibox Detector)에 대해 소개하겠다.
SSD를 한마디로 표현하면 output을 만드는 공간을 나누고, 각 feature map에서 다른 비율과 스케일로 default box를 생성하고 network를 통해 계산된 좌표와 class 값에 default box를 활용하여 최종적인 bounding box를 생성한다.
2. Network

우선 SSD의 input으로 300*300*3 size의 image가 들어온다고 가정하자. 위 이미지에서는 vgg 5_3까지 통과한 후 또 다른 convolution layer를 거쳤지만 우리는 vgg 4_3 convolution layer까지 거쳤다고 가정하자.

VGG 4_3를 거친 후 각 layer의 해당하는 feature map은 Extra network를 통해 또 다른 network로 들어가게 된다. 한마디로 1개의 feature map은 다음 convolution layer로 들어가게 되고, 또다른 feature map은 extra network로 들어가 해당 feature map에 해당하는 feature를 추출하는 network로 들어가게 된다.
각 layer를 설명하면 VGG 4_3를 거치고 나온 38*38*512에 해당하는 feature map은 또 다른 convolution layer를 거치고 나와 3*3*(4*(classes+4))가 되고, 또 다른 feature map은 다음 convolution layer로 들어가게 된다. 그 다음 feature map은 19*19*1024로 다른 convolution layer를 거쳐 3*3*(6*(classes+4))가 되고 위 그림과 같이 또 다른 feature map은 다음 convolution으로 거치게 된다. 여기서 나오는 각 layer의 conv filter size는 3*3*(num of bounding box)*(class score+offset))이고, stride =1, padding = 1이라고 추정된다. 또한 6개의 feature map에서 예측된 bounding box의 총합은 8732개이다.

Bounding box가 8732개가 나온다고 해서 모든 bounding box를 고려하지 않는다. 각 feature map당 다른 scale를 적용해서 default box간 IOU를 계산한 후 미리 정의해둔 threshold 값 이상이 되는 bounding box만 고려 후 나머지는 다 0으로 만들어 버린다.
위에서 보이는 그림이 thresholding 후 남은 bounding box이다.
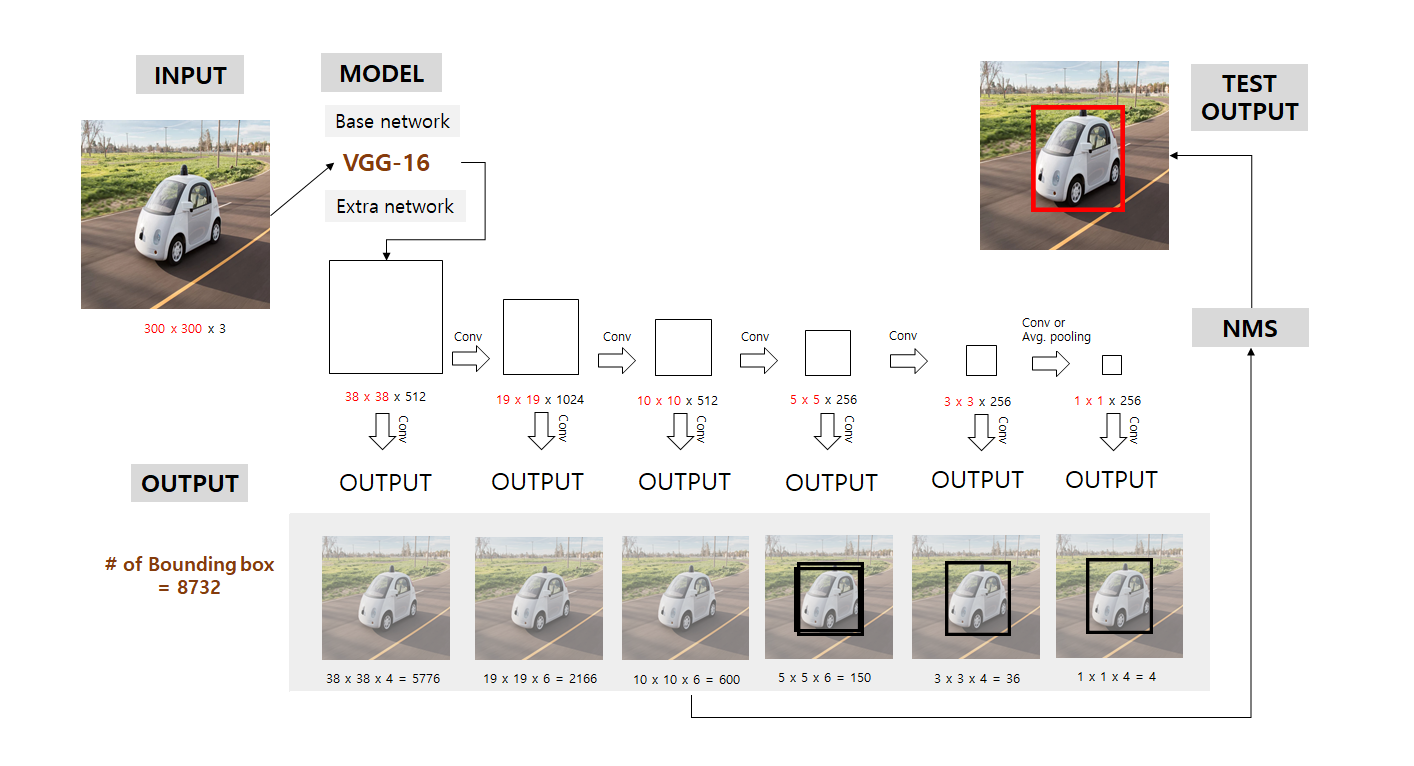
최종적으로 bounding box들은 NMS를 통해 1개의 detect box로 결과값을 도출한다.
다시 한번 이 구조에 대해 설명을 하면 우선 Faster R-CNN과 같이 각 ratio와 size가 다른 default box를 먼저 설정을 한다. 그리고 각 layer에서 나온 image들을 default box에 투영하여 bounding box regression을 적용하고 confidence level을 적용한다. 이 과정에서 큰 feature map에서는 작은 물체를 탐지하고, 작은 feature map에서는 큰 물체를 감지한다. 다음으로 feature map에 3*3 filter를 적용시켜 bounding box regression을 적용하고, 마지막으로 각각의 default box마다 class에 대해 classification을 적용하여 최종적인 feature map을 얻게 된다.
앞에서 나왔던 default box는 Faster R-CNN의 anchor와는 다른 방법으로 생성된다.

m: object detection을 수행할 feature map의 개수
k: feature map의 idx
s_min: 0.2, s_max: 0.9로 설정
m을 6으로 설정하였을 때 나오는 결과는 [0.2, 0.34, 0.48, 0.62, 0.76, 0.9]가 된다. 이 값들의 의미는 default box의 크기를 계산할 때 input의 width, height에 대해 얼마나 큰지 나타내는 값들이다. 예를 들어 첫번째로 나온 값 0.2는 0.2의 비율을 가진 작은 box를 default box로 놓겠다는 의미이다.

이제 각각의 box들의 width와 height를 계산을 해야한다. 다양한 ratio를 가진 default box를 generate하기 위해서는 위와 같은 식이 적용된다.
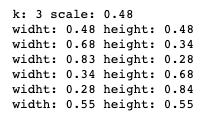
만약 k = 3이면 default box의 각각의 width와 height는 이렇게 나온다. (m이 6이라 결과는 6개)

Default box의 중심점은 위 수식으로 구할 수 있다.

최종적인 default box는 이렇게 나오게 된다.
다음은 loss function에 대해 알아보자


우선 전체적인 loss function의 형태는 YOLO의 loss와 생김새가 비슷하다. 각 클래스 별로 예측 값과 실체 값의 차인 Lconf와 bounding regression과 실제 값 차이인 Lloc를 더한 것으로 구성된다.
우선 Lconf를 살펴보면 기본적으로 cross entropy와 생김새가 비슷하다. 여기서 나오는 xpij는 특정 grid의 i번째 default box가 p class의 j 번째 ground truth box와 match된다는 의미이다.

다음으로 살펴볼 Lloc는 전에 포스팅 했던 Fast R-CNN의 bounding box regression과 동일하다.
그 아래는 예측값과 실제값의 차이를 width와 height로 나누어 0에서 1사이로 정규와 해준 것이다.
3. result
결과적으로 SSD는 FPS 58, Map 72.1을 기록하며 YOLO보다는 정확도가 높게, Faster R-CNN보다는 빠른 성능을 갖고 있는 네트워크다. SSD는 추후에 mobile전용, parameter의 용량이 줄어든 light version등 다양한 버전이 출시되었다. SSD의 속도가 향상된 이유에는 우선 output layer와 fully connect layer를 사용하지 않았다. 이를 통해 weight parameter의 개수들이 감소하였고, 또한 기존 bounding box를 default box의 도입으로 인해 더욱 정확하게 object를 detect할 수 있어졌고, 가장 중요한 점은 각 layer의 feature map을 추출하여 regression하는 과정이 정확도 측면에서 크게 향상시킬 수 있었다. 단점은 딱히 존재하지 않고, SSD는 SOTA를 갱신하였기 때문에 지금도 자주 쓰이는 network model중 하나이다.
4. reference
SSD: Single Shot MultiBox Detector (paper)
'study > paper reviews' 카테고리의 다른 글
| YOLOv3: An Incremental Improvement (0) | 2020.06.04 |
|---|---|
| YOLO9000: Better, Faster, Stronger (YOLOv2) (0) | 2020.05.07 |
| YOLO: You Only Look Once: Unified, Real-Time Object Detection (0) | 2020.03.18 |
| Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (0) | 2020.03.16 |
| VGG NET: Very Deep Convolution Networks For Large-Scale Image Recognition (0) | 2020.03.13 |



