
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- EfficientNet
- pytorch project
- SVM margin
- RCNN
- TCP
- Computer Vision
- Faster R-CNN
- svdd
- CNN
- 논문분석
- computervision
- fast r-cnn
- darknet
- libtorch
- yolo
- Object Detection
- cnn 역사
- CS231n
- SVM hard margin
- self-supervision
- pytorch
- 서포트벡터머신이란
- yolov3
- SVM 이란
- cs231n lecture5
- 데이터 전처리
- pytorch c++
- Deep Learning
- DeepLearning
- support vector machine 리뷰
- Today
- Total
아롱이 탐험대
YOLO9000: Better, Faster, Stronger (YOLOv2) 본문
YOLO9000: Better, Faster, Stronger
Joseph Redmon∗†, Ali Farhadi∗† University of Washington∗ , Allen Institute for AI†
1. Introduction
저번에 리뷰하였던 YOLO 즉 YOLOv1에 이어 성능과 속도 측면에서 모두 향상시킨 YOLO9000 (YOLOv2)에 대해 알아보자.
우선 기존 YOLO, faster r-cnn 그리고 SSD는 모두 real time에 적용가능한 network이다. 하지만 여전히 정확도 (mAP) 측면에서는 부족한 감이 존재한다. YOLOv2에서는 정확도와 속도를 향상시킴으로써 이를 보완한다. 이름에서 보셨다싶이 YOLOv2는 YOLOv1을 계승한 모델이고, 9000이라는 숫자가 붙는 이유는 YOLOv2를 사용하여 9000개의 object를 구별했기 때문이다. 그럼 이제 본격적으로 YOLOv1과의 차이점을 중심으로 어떻게 YOLOv2가 좋아졌는지 살펴보자.
아직 YOLOv1에 대해 공부하지 않았다면 먼저 공부하고 오는 것을 반드시 추천한다.
(https://ys-cs17.tistory.com/8?category=764333)
2. Network
간략히 소개하자면 YOLOv2는 v1에서 10가지 요소를 추가한 네트워크이다. 시간이 지나면서 새로운 network나 region proposal 방법 등 다양한 기법들이 등장하였다. 추가된 10가지 요소를 확인하고 하나하나 차근차근 자세히 살펴보자
1. Batch Normalization
2. High Resolution Classifier
3. Convolutional
4. Anchor Boxes
5. new network
6. Dimension Clusters
7. Location prediction
8. passthrough
9. Multi-Scale Training
10. Fine-Grained Features
1. Batch Normalization
YOLOv2에서는 batch normalization을 진행하였다. 그 결과 mAP 기준 2%가 더 상승하였다고 한다.
batch normalization은 이전에 공부하였던 cs231n (https://ys-cs17.tistory.com/15?category=764395) 65p부터 보면 된다.
2. High Resolution Classifier
기존 YOLOv1에서는 google net을 사용했던 반면 YOLOv2에서는 darknet-19를 사용하였다. darknet-19는 우선 10가지 바뀐점을 모두 설명하고 자세히 설명하겠다.
무튼 다시 원점으로 돌아와서 CNN의 학습 과정은 크게 2가지로 나눈다.
첫번째 단계는 고해상도 dataset인 ImageNet data를 사용하여 Darknet-19를 epoch을 10으로 448*448 size image를 input으로 받게 설정하여 classification network로 학습시킨다.
두번째 단계는 darknet-19에서는 마지막 layer가 fully connected layer가 아닌 convolution layer의 출력이 1000개인데 이 부분과 Avg pooling, Softmax 부분을 제거하고 object detection layer 4개를 추가한다. 이를 통해 object detection network를 학습시킨다.
두 단계로 나누어서 학습을 진행하는 이유는 처음부터 bounding box와 classification을 같이 train하는 과정이 힘들기 때문이다. 따라서 첫번째 단계가 끝난 parameter를 가지고 fine tuning을 시켜 두번째 단계를 진행하면 정확도와 효율성이 증가하게 된다. 본 논문에서는 약 4% 성능이 향상되었다고 한다.
3. Convolutional
위에서 말했던것 처럼 YOLOv2는 v1과 달리 마지막 2개의 fc layer 대신 convolution layer를 사용하였다. fc layer를 사용하지 않고 convolution layer를 사용하기때문에 가운데 존재하던 cell들의 receptive field는 이미지 전체를 커버하지 못한다.
또한 네트워크의 input size를 448에서 416으로 줄였는데 그 이유는 result feature map을 홀수로 만들기위해서다.
이를 통해 receptive 속도도 빨라지고, 최종적인 grid cell의 receptive field가 더 커진다고 한다. 또한 홀수일때 grid cell이 feature map의 중앙 부분에 위치하게 되는데 이는 보통의 물체들이 대부분 중앙 부분에 위치하는 경우가 많아 더욱 효율성이 높아지는 이유 중 하나다. 예를 들어 최종적으로 나온 feature map의 크기가 2*2인 경우 가운데 grid cell을 정의할 수 없지만 논문에서와 같이 최종적으로 추출되는 layer의 크기가 13*13인 경우에는 가운데에 위치한 grid cell를 추론할 수 있다.
4. Anchor Boxes
YOLOv2에서 사용된 RPN (Region proposal network)은 Faster R-CNN에서 사용된 Anchor box를 사용했다.
이를 사용하면서 공간에 존재하는 위치로부터 class 예측을 분리하였다. 전체의 Anchor box를 이용하여 그 곳에 물체가 존재하는지, 존재한다면 어떤 object의 속하게 되는지를 확률로 예측하고 클래스를 분리시킨다.
Anchor box를 사용함으로써 mAP 성능은 조금 떨어졌으나 recall은 81%에서 88%로 크게 상승하였다.
Anchor box가 무엇인지 모르면 아래 faster r-cnn 논문 리뷰에서 Achor box부분을 참고하길 바란다.
https://ys-cs17.tistory.com/7?category=764333
5. new network

위에서 언급한바와 같이 YOLOv2에서는 google net이 아닌 darknet-19를 사용하였다. 이 논문이 나올 당시 대부분의 사람들은 VGG net을 사용하였다. dark net을 사용한 이유는 1*1 filter 연산과 같이 bottleneck이 사용되었기 때문이다. bottleneck을 사용하면 연산에 사용되는 파라미터의 수가 줄어드는것과 동시에 계산의 효율성이 매우 좋아진다. 이것은 또한 the power of small filter 법칙과 연관이 되는데 이는 필터가 작을 수록 연산 효율이 더 좋아지는 이론이다. bottle neck과 the power of small filter에 대해 처음들어보았거나 원리에 대해 더 자세히 알고 싶으면 https://ys-cs17.tistory.com/20를 40p부터 참고하기바란다. classification 정확도 측면에서는 top-5 error를 93.3%를 기록하였다.
6. Dimension Clusters

기존 YOLOv1에서는 anchor box를 사용하여 object detection의 영역을 결정하고 이를 통해 IOU를 도출하였다. 하지만 YOLOv2에서는 VOC data, COCO data에 존재하는 object의 bounding box를 clustering을 하여 scale과 ratio를 결정한다. 이때 cluestering 과정에서 만약 Euclidean distance를 사용하게 되면 물론 k-means error는 줄어들겠지만 IOU를 높히는데는 효과가 크지않다. 따라서 IOU를 더욱 높이고자 YOLOv2에서는 아래의 식을 통하여 distance를 구한다.


또한 K의 값은 위 그래프와 같이 가장 적절한 5를 선택을 하였다. 그 이유는 K 가 많아지면 Avg IOU는 높아지겠지만 그만큼 연산량과 모델 복잡도가 늘어나기 때문이다.

이는 각 Cluster의 평균 IOU의 값들이다. Anchor Box보다 Cluster IOU가 더 좋은 것을 확인할 수 있다.
7. Location prediction
YOLOv1에서 anchor box를 사용하면 초기 box의 좌표가 random하게 설정되어 초기 학습에 어려움이 있다. region proposal network에서는 아래식과 같이 tx, ty를 예측한다. 여기서 x와 y는 bounding box의 중심점이다.
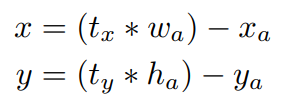
만약 tx가 1이면 prediction box는 anchor box의 가로만큼 오른쪽으로 이동, -1이면 왼쪽으로 이동한다. 하지만 이를 사용해도 초기값에 대한 문제는 해결이 되지않는다. YOLOv1에서는 (x,y)의 위치를 grid cell 안쪽에 두고, object가 있을때는 1, 없을때는 0으로 판단하였다. 하지만 YOLOv2에서는 logistic activation을 사용하여 0과 1사이의 값으로 표현시킨다. region proposal network가 예측한 5개의 bounding box에는 5개 씩의 정보가 담겨있다. 바로 tx, ty, tw, th, to이다. 아래 식에서 cx, cy는 각 grid cell의 좌측 상단 끝의 offset이다. pw, ph는 bounding box prior의 width와 height이다.

이 식을 사용하여 location prediction을 더욱 쉽게 학습시킬 수 있고, network도 더욱 안정적이라고 한다. 또한 성능이 5% 정도 상승하였다고한다.
더욱 자세히 설명을 하자면 tx와 ty는 sigmoid를 거쳐 0.5가 되길 원한다. sigmoid를 거쳐 0.5가 된다는 의미는 즉 tx, ty를 0으로 유도하는 것이다. 만약 sigmoid(tx)가 0.5가 된다면 bx는 grid의 중심 좌표가 된다. tw, tx 또한 0인 경우 1이 되며 bw, bh는 prior의 width와 height랑 같아지게 된다. bounding box가 anchor box보다 작을 때에는 tx, th가 0보다 작은 음수여야한다. 아래 이미지를 보면 더욱 이해가 잘될 것이다.

8. passthrough
YOLOv2에서는 13*13 feature map에 skip layer를 사용하여 작은 물체에 대해서도 검출 효과를 향상시킨다.
간단히 설명하자면 26*26 크기의 중간 feature map을 13*13 layer에 붙인다.
26*26을 그냥 붙일수는 없어 26*26*512의 size를 13*13*(512*4)로 변형을 시킨다
26 size의 feature map에는 13 size의 feature map보다 고해상도의 feature가 있기때문에 정확도가 더욱 상승한다.
9. Multi-Scale Training
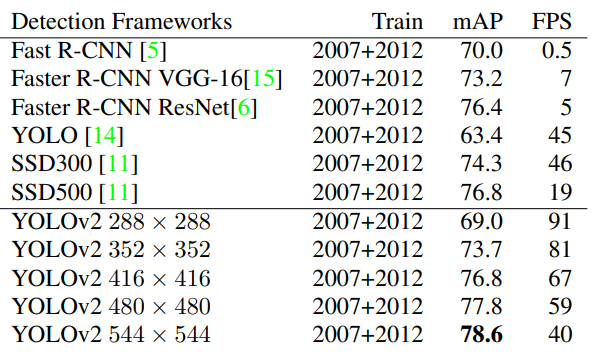
YOLOv2는 다양한 size의 image들이 input으로 들어온다. 가장 작은 size는 320, 가장 큰 size는 608이다. 이렇게 다양한 size의 data를 입력받기 위해 YOLOv2에서는 320,352, ..., 608로 10번의 batch 마다 size가 변경 된다. network는 image를 1/32배 줄이므로 image의 size를 32배 크게 하면 된다. 아래는 size에 따른 mAP와 FPS이다.
10. Fine-Grained Features
마지막 layer의 크기가 7*7에서 13*13로 증가하였다. 또한 기존 7*7 size의 grid cell과 2개의 boundary box를 가지고 있던 반면 YOLOv2에서는 5개의 boundary box를 사용하여 각 box 마다 class 확률을 독립적으로 정의한다.

최종적으로 위 10개를 충족시킨 YOLOv2는 v1에 비해 15%의 성능 향상을 가져온다.
3. result

SSD와 ResNet과 비교를 하였을때 정확도 측면에서는 크게 차이가 나지않거나 오히려 떨어진다. 하지만 YOLOv2의 가장 큰 장점은 속도이다. 무려 2~10배가 더 빠르다.

4. reference
'study > paper reviews' 카테고리의 다른 글
| EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 분석 (0) | 2020.09.11 |
|---|---|
| YOLOv3: An Incremental Improvement (0) | 2020.06.04 |
| SSD: Single Shot Multibox Detector (0) | 2020.03.23 |
| YOLO: You Only Look Once: Unified, Real-Time Object Detection (0) | 2020.03.18 |
| Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (0) | 2020.03.16 |



