
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- cs231n lecture5
- support vector machine 리뷰
- Computer Vision
- EfficientNet
- yolov3
- 논문분석
- svdd
- SVM 이란
- SVM margin
- SVM hard margin
- DeepLearning
- Faster R-CNN
- yolo
- darknet
- self-supervision
- libtorch
- Object Detection
- RCNN
- pytorch c++
- CNN
- pytorch project
- 데이터 전처리
- fast r-cnn
- 서포트벡터머신이란
- CS231n
- pytorch
- TCP
- Deep Learning
- cnn 역사
- computervision
- Today
- Total
아롱이 탐험대
EfficientDet: Scalable and Efficient Object Detection 분석 본문
EfficientDet: Scalable and Efficient Object Detection 분석
ys_cs17 2020. 9. 14. 14:09EfficientNet과 매우 연관성이 큰 논문임으로 https://ys-cs17.tistory.com/30에 이어서 봐주길 바란다.
EfficientDet은 2019년 11월 논문이 발표되었으며, EfficientNet과 같은 저자의 논문이고 이 저자들의 소속은 구글 브레인 팀이다.
EfficientDet은 sota를 기록한 object detection 네트워크이다. 동급의 네트워크 예를 들어 amebaNet-based Nas-FPN과 같은 높은 ACC를 기록한 네트워크와 비교하자면 파라미터 크기의 있어 매우 효율적인 네트워크이다.
실 세계에서는 로봇, 모바일과 같이 효율적인 파라미터 값들을 갖는 네트워크가 필요하다.
지금까지 나온 효율적인 object detection network들도 많지만 이 네트워크들은 모바일과 로봇 같은 곳에 적용하지 쉽지 않은 네트워크들이다.
저자들이 해결하고자 하는 문제는 효율성과 정확성을 동시에 챙기면서, 모바일과 로봇 등의 큰 폭의 스펙트럼에서 적용시킬 수 있는 네트워크를 구상하고 싶었다.
이를 만족하기 위한 2가지 challenge가 있다.
1. Efficient multi-scale feature fusion
기존 논문들은 multi-scale- feature fusion을 많이 사용하고 있다.
이 방법은 다양한 level의 특징을 섞어서 operation을 추가하여 detection을 추가하는 방법이다.
이 방식을 사용한 논문들은 width, height만 맞춘다음에 sum을 진행했는데, 이 방법을 사용하면 다양한 detection의 결과가 나오고, 이들은 다양한 resolution을 갖고 있기 때문에 이를 단순하게 sum을 하는 방식은 부족하다고 생각한다.
2. model scaling
처음에 작은 모델에서 시작해서 큰모델로 점차 증진시키는 방법으로 model scaling을 진행할 예정인데 efficientnet에서 시도하였던 것처럼 compound method를 사용하여 더욱 효율적인 model을 구상할 것이다.
종합적으로 efficientnet의 backbone과 BIFPN, compound scaling을 사용하여 efficientDet을 구상하였다.
Feature pyramid인 BIFPN, compound method를 사용하여 one-stage로 network를 구상하였다.
BIFPN을 살펴보자

feature pyramid에서 사용할 feature map을 벡터 Pin이라고 하고, feature level에 따라서 Pinl1, Pinl2라고 정의한다. 이런 set이 있을때
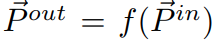
우리는 transform을 해주면서 최적의 pout을 output으로 가지는 f를 찾는 것이 우리의 목표이다.

기존 fpn을 살펴보면 level 3~7의 input feature들을 뽑아서 연산을 진행한다.

Pin의 아래 있는 숫자들은 1/2^i로 연산을 진행한다.
예를 들어 640*640 input이 들어왔을 때 level 3에 해당하는 resolution은 640/2^3으로 80*80이 된다.
Level 7은 5*5가 된다.
이렇게 연산을 진행한 후 다시 top down 방식을 통해 오른쪽 레이어처럼 진행한다.
그리고 서로 같은 level에 있는 feature들끼리 fusion을 진행하여 bound box와 class를 예측한 결과가 나오게 된다.

논문에서는 FPN에 대한 구조를 위 그래프로 표현하였다.

연산은 위 수식처럼 맨 위에 해당하는 값은 그냥 conv를 진행하고, 그 아래 값부터는 resize를 하여 단순히 더함으로 p out을 구한다.
그다음으로 나온 논문은 PANet에서는 top-down 방식뿐만이 아니라 bottom-up 방식도 도입하였다.

그 다음 nas를 사용한 fpn방식은 점선의 부분을 사람이 직접 구상하지 말고 이 또한 neuron network를 도입하여 진행하였다.

하지만 NAS-FPN의 같은 경우에는 최적점을 찾기에 시간이 오래 걸리고, 구조가 복잡하다는 단점이 있다.
PANet 구조에 대해 더 자세히 살펴보자

down top 방식에서 작은 object를 detect 할 때 작은 level에서는 성숙도가 낮기 때문에 잘 찾지 못한다.
하지만 top down을 통해 이를 보충할 수 있다.
하지만 논문의 저자는 넓은 부분의 feature map에서는 위치 정보가 더 많이 존재해 한번 더 down-top을 해야 할 필요하 있다고 판단하였다.
보통 파란색 layer는 100개 정도 되는데 주황색 down top layer는 short cut을 활용한 10개 정도의 layer를 도입하여 성능을 더욱 향상했다.
NAS-FPN에 대해 자세히 살펴보자

아까 설명한 것과 마찬가지로 down top을 진행한 후 이를 feature pyramid network를 사용하여 neuron net을 통해 최적의 값을 찾는다.

아까 살펴보았던 그래프를 쭉 펼친 구조이다. P 중 2개를 선택하여 global pooling을 진행한 후 이를 sum을 해줌으로써 loss를 계산하게 된다.
Efficientdet 저자들이 같은 조건에서 FPN, PaNet, Nas-FPN 중 PaNet이 가장 성능이 좋은 것을 자체 실험을 통해 확인하였으며 이 구조를 가져오면서 이를 더욱 단순화하여 제작하였다.

구조를 이렇게 바꾼 이유는 우선 맨 위에 있는 p는 panet에서는 그냥 conv를 진행하기 때문에 그냥 없애버렸고, 맨 아래 빨간색도 마찬가지인 이유로 날려버려 더욱 구조를 단순화하였다.

또한 최종적으로 원래의 feature들을 또 한 번 fusion을 진행하였다. 구조로 바꾼 이유는 fusion을 많이 할수록 성능이 더 좋아지기 때문이다.
더 많은 cost를 더하지 않음으로 더 많은 fusion을 진행할 수 있다. 또한 이 구조가 끝이 아니고, 이 구조를 계속 repeat 하여 성능을 향상했다.

그리고 기존 fpn의 방법은 위에서 내려온 feature를 2배 up scaling을 진행하여 1*1 conv와 sum을 해주는 구조였다.

하지만 추후 나온 논문인 pyramid attention network에서 나오는 방법을 사용하여 high level에 있는 feature map을 global pooling을 통해 1*1로 만든 후 3*3과 곱한 값과 더하는 구조를 가지고 있다.
이 논문의 저자들은 이에 대해 3가지 fusion 방법을 고려하였다.
1. unbounded fusion

I는 feature map인데 그냥 weight를 곱해서 sum을 진행한다.
굉장히 직관적으로 생각할 수 있는 방법이다. wi는 스칼라, 벡터, multi demensional tensor일 수도 있는데 실험 결과 스칼라 값으로 해도 괜찮았다.
하지만 스칼라 값이 너무 튀는 값이라면 결과가 이상하게 나올 수 있다.
2. Softmax-based fusion

attention 개념으로 softmax를 고려하였다. 각각을 0에서 1로 값을 변환하여 sum을 해주는 방식인데 성능은 괜찮지만 실제로 gpu에서 연산을 시도하면 속도가 많이 떨어뜨리는 요인이 되었다.
3. Fast Normalized Fusion

해당 fusion이 논문 저자들이 채택한 method이다.
위식으로 normalize를 진행하였다.
wi가 양수라고 가정을 해야 되기 때문에, wi는 relu를 통과한 값으로 사용하고, 입실론은 0을 방지하기 위한 값이다.
이것으로 실험을 해보니 softmax와 성능 차이는 크지 않았지만, 속도 측면에서 30% 더 빨랐다고 한다.


실제로 계산은 이렇게 진행한다. Out의 분모는 프라임 넣어야 한다.

실제 구조에서는 efficientnet을 backbone으로 사용하고, p3~p7를 우리가 위에서 보았던 fusion 방식을 사용하여 반복한다. 반복하는 횟수는 정해져 있고, 결국 output에서는 weight를 서로 공유하며, cls predict, b-box predict를 진행한다.
이제는 compound scaling을 어떻게 진행할지에 대해 알아보자

이전에 살펴본 efficientnet의 compound scaling에 따른 각 구조이다.

또한 각 depth, width, resoltuion에 대한 parameter를 어떤 조건으로 넣을 지에 대한 수식이다.
efficientdet에서는 backbone, bifpn, class/box, resolution모두 compound scaling을 도입하여 키울 예정이다.
하지만 이 모두에 대한 scaling 값을 추정하기 힘들어서 어쩔 수 없이 heuristic-based scaling approach를 사용하였다.
Backbone
여기서는 width, depth만 efficientnet의 b0~b6와 같게 설정을 하고, resolution은 따로 뺐다.

Backbone network의 resolution 부분은 level 3~7에서 사용되기 때문에 r input은 2^7승인 128을 사용하였다.
BiFPN

위 수식을 사용하였고, 1.35는 실험을 통해, depth부분은 heuristic 하게 정수가 나올 수 있게 설정하였다.
Box/class prediction


weight는 위와 동일하게 설정하였고, bbox와 d class 마찬가지로 heuristic하게 설정하였다.

각 theta에 따른 input size, backbone, BiFPN, box/cls에 대한 정보이고, d7은 computing power가 따라주지 않아서 다른 방식을 통해 값을 설정하였다고 한다.

결과를 보면 같은 파라미터를 갖는 네트워크랑 비교를 했을 때 매우 좋고, 스피드도 매우 좋다.

그래프로 보았을 때도 비슷한 ACC를 갖는 네트워크들 사이에서 parameter, latency가 훨씬 효율적인 모습을 볼 수 있다.

FPN과 BIFPN을 사용했을 때의 비교이다. BIFPN이 더 좋은 모습을 볼 수 있다.

Softmax로 fusion을 진행했을 때 성능은 조금 더 좋지만 족도 측면에서 더 느리다.

마지막은 compound scaling을 하였을 때 차이점이다. heuristic 하게 진행하였기 때문에 빨간색이 optimal 값은 아니다.
실험의 종합적인 결과는 weighted bidrectional feature network와 compound scaling method를 모두 활용하여 최적의 값과 적은 양의 parameters, latency를 갖는 EfficientDet을 구현하였다.
이는 모든 면에서 ACC와 efficiency를 증진시켰고, EfficientDet-D7 dms 51.0 mAP로 COCO dataset에서 State-Of-art를 기록하였다.
또한 EfficientDet은 기존 비슷한 ACC를 갖는 network보다 gpu에서 3.2배, cpu에서 8.1배 더 빠르다.
Reference
https://arxiv.org/pdf/1911.09070.pdf
https://www.youtube.com/watch?v=11jDC8uZL0E
'study > paper reviews' 카테고리의 다른 글
| Accurate Image Super-Resolution Using Very Deep Convolutional Networks 분석 (0) | 2020.10.06 |
|---|---|
| Deformable Convolution Nertworks 분석 (0) | 2020.09.16 |
| EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 분석 (0) | 2020.09.11 |
| YOLOv3: An Incremental Improvement (0) | 2020.06.04 |
| YOLO9000: Better, Faster, Stronger (YOLOv2) (0) | 2020.05.07 |



