
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Faster R-CNN
- Object Detection
- self-supervision
- support vector machine 리뷰
- CNN
- computervision
- CS231n
- Computer Vision
- SVM margin
- pytorch
- RCNN
- Deep Learning
- EfficientNet
- pytorch project
- yolo
- yolov3
- libtorch
- 서포트벡터머신이란
- 논문분석
- darknet
- svdd
- SVM hard margin
- pytorch c++
- cnn 역사
- DeepLearning
- TCP
- cs231n lecture5
- SVM 이란
- fast r-cnn
- 데이터 전처리
- Today
- Total
아롱이 탐험대
Accurate Image Super-Resolution Using Very Deep Convolutional Networks 분석 본문
Accurate Image Super-Resolution Using Very Deep Convolutional Networks 분석
ys_cs17 2020. 10. 6. 13:25해당 논문은 2016년 서울대 computer vision lab에서 지난 시간에 다루었던 SRCNN를 보완한 super resolution using deep learning에 관한 내용이다.
논문의 저자는 SRCNN에서 부족했던 3가지를 언급하며 이를 해결한 방법을 설명한다.
Context
SRCNN와 달리 해당 논문의 network인 VDSR에서는 large receptive field를 사용하여 넓은 image resion에 있는 다양한 정보들을 이용하여 높은 scale의 image에서도 안정적으로 작동하였다.
Convergence
residual learning과 초기값이 10^4인 높은 learning rate를 사용하여 기존 network보다 훨씬 빠른 Convergence를 달성하였다.
residual learning은 HR (High Resolution)과 LR (Low Resolution) 사이의 높은 유사도를 보이며 효율성을 증가시킬 수 있었고, 높은 learning rate로 인한 빠른 convergence는 residual learning과 gradient clipping을 통해 가능할 수 있었다.
Scale Factor
우리의 model은 single-model이지만 다양한 scale에서도 적용할 수 있는 model이라고 한다.
위 3가지를 요약하자면 우리는 very deep convolution network를 기반으로 하여 super resolution 방법을 증진시켰다.
보통 네트워크의 layer가 깊고 lr이 작으면 convergence는 느려지게 되지만 우리는 위에서 언급한 방법을 통해 convergence를 증진시켰다. 게다가 single network에서 발생하는 multi scale SR 문제를 해결하였고, 당시 sota를 달성한 network와 비교하면 상대적으로 정확도도 좋고 빨랐다고 한다.
SRCNN과 VDSR의 model을 아래 표와 함께 비교해보자.
|
SRCNN |
VDSR |
|
|
Architecture |
end-to-end learning |
end-to-end learning |
|
Receptive fields |
13*13 |
41*41 |
|
Scale factors |
*3 |
*2, *3, *4 |
|
Learning rate |
10^-5 |
learning rate decay (10^-2, 10&-6) |
|
Depth |
4 |
(Up to) 20 |
우선 구조 자체는 둘 다 end-to-end learning을 사용하였지만 조금 다른 점은 VDSR에서는 맨 마지막 부분에서 residual를 사용하였다. Receptive field는 VDSR에서 훨씬 크게 사용한 점을 볼 수 있고, Scale factors도 마찬가지다.
learning rate 같은 경우 SRCNN에서는 고정을 해두었지만 VDSR에서는 decay를 사용하여 lr를 tuning 하는 모습을 볼 수 있다.
depth는 SRCNN에서는 4개인 반면 VDSR은 Very deep convolution이란 이름에 알맞게 20개이다.

모델의 구조는 우선 image의 color space를 rgb에서 y cb cr로 나눈 후 각 channel에 대한 image를 Bicubic interpolation으로 원하는 scale factor로 upscale를 진행한다.
그 후 y channel에 해당하는 image만 VDSR network의 input으로 넣어주고, 원래의 y channel image와 더한 output과 HR image와 비교하여 residual learning을 진행한다. output과 HR image에 대한 loss 연산은 MSE를 사용한다.
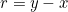

VDSR network에서 사용되는 filter는 모두 VGG와 비슷하게 20개의 3*3으로 구성한다.
residual을 사용한 이유는 결국 input과 output의 결과가 비슷하기 때문에 여기서 edge 부분에 초점을 두기 위해서 넣었다.
또한 gradient clipping을 사용하여 gradient 값이 너무 튀지 않게 구성하였고, 41*41로 input patch를 키우고, image에 대한 overlap을 사용하지 않았고, mini batch를 사용하였다. input patch를 키운 이유는 residual 연산을 하려면 input과 output의 size가 같아야 되기 때문에 처음에 upscaling을 하여 network의 input으로 들어간다.
이 논문의 가장 큰 장점은 residual을 사용하여 다른 논문과는 달리 경계 부분이 뚜렸한 모습을 볼 수 있다.
아래의 결과들을 보자



또한 residual을 통해 초반 안정적으로 학습하는 모습을 볼 수 있다.

SRCNN과 비교해서 확실히 좋아진 결과를 볼 수 있다.

Reference
'study > paper reviews' 카테고리의 다른 글
| Distilling the knowledge in a neural network 분석 (2) | 2020.10.15 |
|---|---|
| Neural Turing Machines 분석 (0) | 2020.10.13 |
| Deformable Convolution Nertworks 분석 (0) | 2020.09.16 |
| EfficientDet: Scalable and Efficient Object Detection 분석 (0) | 2020.09.14 |
| EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 분석 (0) | 2020.09.11 |



