
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 논문분석
- support vector machine 리뷰
- cnn 역사
- TCP
- 데이터 전처리
- pytorch project
- DeepLearning
- Object Detection
- svdd
- Faster R-CNN
- 서포트벡터머신이란
- EfficientNet
- yolov3
- SVM hard margin
- CNN
- fast r-cnn
- cs231n lecture5
- darknet
- computervision
- SVM 이란
- pytorch
- Computer Vision
- self-supervision
- Deep Learning
- yolo
- SVM margin
- libtorch
- pytorch c++
- CS231n
- RCNN
- Today
- Total
아롱이 탐험대
Distilling the knowledge in a neural network 분석 본문
기존의 ensemble 같은 경우에는 연산 시간이 매우 오래 걸린다는 단점이 있다. 따라서 이 논문에서는 ensemble을 single model로 이전하는 방법을 탐색하였고, 이 과정을 distilling이라고 부른다.
NN (Neuron Network)은 좋은 알고리즘이지만 예전 논문들의 layer만 보더라도 regularization 과정 없이 Fully-connect 된 node들을 많이 접할 수 있었다. 이 같은 경우에는 모든 node들이 연결되어 있어 over fitting 문제에 매우 취약했다. 따라서 이를 해결하기 위해 ensemble이라는 모델을 사용한다. 이는 input을 여러 NN으로 받고, 이를 합쳐 output으로 내는 방법이다.

ensemble의 종류는 다양하지만 Ann ensemble에서는 단지 parameter를 서로 다르게 initialize 하는 것이 좋다고 한다.
ensemble은 단점도 존재한다. 바로 memory 공간이 많이 소비되고, 시간도 오래 걸린다.
따라서 해당 논문의 목표는 이 단점들을 해결하기 위해 ensemble을 single model로 이전하는 것이 목표이다.
해당 목표를 위해 이전 논문에서 다양한 방법으로 문제를 접근하였다.
첫번째는 만약 관측치를 많이 가지고 있으면 ensemble을 하지 않아도 일반적인 성능이 높아질 것이라는 추론이다.
ensemble 같은 경우에는 train data가 많지 않아도 일반화 성능이 높게 학습된다. 하지만 기존 single model 같은 경우에는 train data에만 적합되는 over fitting이 일어나는 경우가 많다. 따라서 데이터를 더 증가시키는 방법이 1번째 방법이다.


이 방법을 사용하기 전에 우선 model을 학습시켜 overfitting 상태로 만든다. 그리고나서 데이터를 증가시켜야 하지만 우리는 충분한 양의 데이터를 가지고 있지 않다. 따라서 인공적인 데이터를 생산해야 한다.
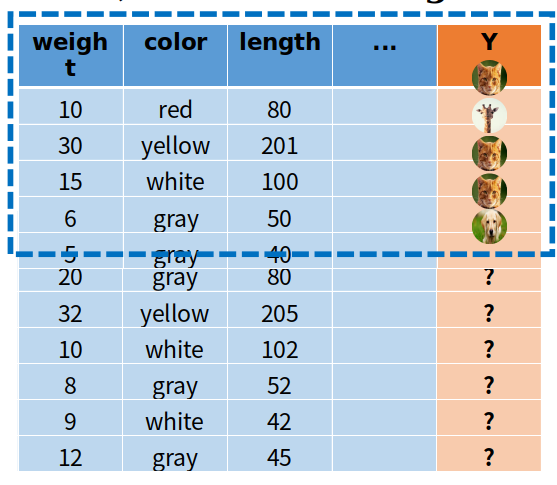
파란 점선으로 된 부분이 우리가 가지고 있는 데이터와 결과이고, 인공적으로 생성한 데이터는 라벨이 존재하지 않는다. 우리는 ensemble을 통해 학습된 model을 사용하여 인공적으로 생성한 데이터를 input으로 하여 이에 따른 label을 붙이면 된다.

결과적으로 다량의 데이터를 이 방법을 통해 생산한다.

결과적으로 train data가 많을 수록 single model이 ensemble 하였을 때와 비슷해지는 모습을 볼 수 있다.
distilling 방법을 사용하기 위해 다른 방법으로도 접근할 수 있다. 이는 label class의 확률 분포를 이용하는 방법이다.
이 방법은 label에 해당하는 값 대신 ensemble 방법으로 logit 값을 줌으로써 data의 분포를 알아보는 방법을 사용한다.
여기서 logit이란 마지막 hidden layer의 weight에 해당하는 값으로 class의 score라고 생각하면 된다.
또한 그냥 logit을 사용하는 방법 대신 logit에 noise를 줌으로써 regularization을 해주는 방법도 존재한다.
마지막 방법은 이 논문의 내용인 distilling ensemble이다. 확률 분포를 줄 때 softmax를 사용하는 방법이다.
우선 ensemble model을 가지고 각 데이터를 softmax 연산을 해준 다음에 각 관측치에 따른 class의 확률을 계산하게 된다. 이를 가지고 단순히 single model을 학습하면 ensemble이 전이된다고 한다. 또한 확률을 가지고 학습하는 것이 regularization 되는 효과가 있다고 한다.

해당 논문에서 쓰이는 softmax는 기존과 달리 T라는 temperature에 해당하는 변수를 추가한다.

t는 값이 작다면 logit 값이 큰 값들은 1에 가까워지고, logit이 작은 값들은 0에 가깝게 변환해준다. 반대로 t값이 크면 모든 확률이 다 비슷해진다. 따라서 확률 분포의 의미가 없어진다.
t가 1일 때는 ensemble model의 확률이 1에 가까워져 확률 분포를 알기 힘들다고 한다. 예를 들어 정답 class가 a인 데이터를 학습시키면 결과적으로 logit이 a에 대한 확률만 매우 크고 나머지는 작아 확률 분포를 알기 힘들다는 의미이다. 기존 softmax의 t는 1이다. 해당 논문에서는 t 값을 2~5 정도로 사용한다.
적당한 t 값을 구해야 하는데 이는 실험을 통해 결정한다고 한다.
이 과정을 통해 label을 결정하게 되고 이를 통해 single model을 구상하게 된다.

cost function은 cross-entropy의 변형 버전을 사용했다.

변형 과정을 살펴보면 우선 기본적인 cross-entropy에서 cost function으로 사용하기 위해 마이너스를 붙인다. 그러고 나서 값이 너무 0으로 가까워질 수 있어 log transform을 진행한다.

기존은 label 값이면 1을 썼던 반면, 이 논문에서는 softmax로 구한 확률 값으로 대체하고, target이 ensemble의 결과 class면 위 수식을, original이면 아래 수식을 적용한다. a 값은 실험을 통해서 결정한다. 논문에서는 0.5로 설정하였다고 한다.

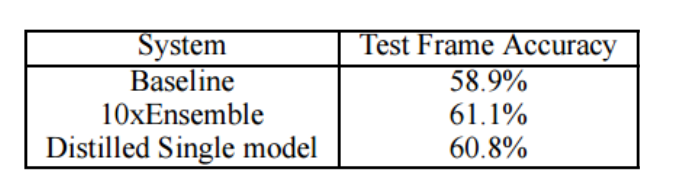
결과적으로 ensemble을 이전시킬 수 있었고, 계산 시간, 공간은 더 적은 모습을 알 수 있다.
최근 논문에서는 softmax의 t와 a 값을 조절하기보다는 logit 값을 사용하는 추세라고 한다.
reference
'study > paper reviews' 카테고리의 다른 글
| Deep anomaly detection using geometric transforms 분석 (0) | 2021.01.04 |
|---|---|
| Unsupervised Visual Representation Learning Overview: Toward Self-Supervision 분석 (0) | 2020.12.28 |
| Neural Turing Machines 분석 (0) | 2020.10.13 |
| Accurate Image Super-Resolution Using Very Deep Convolutional Networks 분석 (0) | 2020.10.06 |
| Deformable Convolution Nertworks 분석 (0) | 2020.09.16 |



