
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- RCNN
- 서포트벡터머신이란
- computervision
- pytorch project
- Object Detection
- yolo
- Faster R-CNN
- svdd
- pytorch
- 데이터 전처리
- darknet
- CS231n
- fast r-cnn
- pytorch c++
- SVM 이란
- support vector machine 리뷰
- SVM margin
- 논문분석
- cs231n lecture5
- TCP
- yolov3
- cnn 역사
- self-supervision
- SVM hard margin
- Deep Learning
- DeepLearning
- CNN
- EfficientNet
- Computer Vision
- libtorch
- Today
- Total
아롱이 탐험대
Unsupervised Visual Representation Learning Overview: Toward Self-Supervision 분석 본문
Unsupervised Visual Representation Learning Overview: Toward Self-Supervision 분석
ys_cs17 2020. 12. 28. 17:41해당 리뷰는 https://kh-kim.github.io/blog/2019/12/12/Deep-Anomaly-Detection.html 내용을 참고하여 작성하였습니다.
컴퓨터 비전 분야에 있어 대부분의 딥러닝 기법들은 Supervised learning 기반으로 학습을 진행한다. Supervised learning은 데이터 관리와 모델 선정을 적절하게 조정하면 매우 좋은 성능을 도출할 수 있다.
하지만 Supervised learning 학습 진행 시 사용되는 모든 학습 데이터에는 label이 mapping 되어 있어야 하고, 이 과정은 많은 시간과 노동이 필요하다. 또한 특정 task에서는 label이 존재하지 않을 수도 있다.
따라서 이 단점들을 보완하고자 Unsupervised learning과 같은 새로운 기법들이 활발하게 연구되고 있다.
오늘 알아볼 기법인 Self supervised learning은 Unsupervised learning의 하위 분류에 속한다.
Self supervised learning 즉 자기 지도 학습은 이름의 의미와 같이 Unlabeled data만 사용하여 스스로 학습을 진행한다.
자기 지도 학습을 간단하게 요약을 하자면 이미지의 higher level의 semantic한semantic 한 정보를 잘 이해할 수 있도록 user가 문제를 만들고, 이 문제들을 통해 semantic 한 정보를 학습하는 것이 자기 지도 학습의 핵심이다.
야기서 user가 창작한 문제를 pretext task라고 부르고, pretext task를 풀면서 얻어진 feature들은 downstream task로 transfer learning을 할 때 사용된다.
이렇게 설명하면 이해가 잘 안되니 지금까지 나왔던 대표적인 pretext 기법들의 논문들을 살펴보며 자세히 알아보자.
1. Exemplar (Discriminative unsupervised feature learning with exemplar convolutional neural networks)

위 논문에서는 STL-10이라는 데이터를 사용하였다. 원본 96*96 이미지로부터 object가 존재할 것 같은 영역 32*32를 crop 해준다. 이를 seed patch라고 부리고 이는 1개의 class를 의미하게 된다.
이런 식으로 왼쪽의 transformation을 이용하여 seed의 개수를 부풀린다.
결과적으로 이를 통해 나온 같은 이미지 상의 여러 seed들을 같은 class로 분류한다.
예를 들어 ImageNet을 사용하게 되면 이미지가 약 100만 장이므로 class 또한 100만 개가 된다. 따라서 학습의 난이도도 매우 높아지게 된다.
따라서 같은 클래스가 많이 존재하는 데이터에서는 해당 논문의 examplar를 적용하기에 적절하지 않다.
2. Relative patch location (Unsupervised Visual Representation Learning by Context Prediction)
다음 논문은 examplar의 단점을 보완한 논문이다.
위 이미지를 보면 한 장의 이미지로 부터 3*3 grid를 통해 patch를 crop 하게 된다. 그러고 나서 가운데 patch와 나머지 patch를 random 하게 가지고 왔을 때, 가운데 patch 기준으로 crop 된 patch가 몇 번째에 위치하는지 예측하게 된다.
위 예시 이미지는 8개의 class를 구별하는 문제라고 생각하면 된다.
예시 사진을 보면 사람도 풀기 힘들 정도의 난이도이다. 하지만 딥 러닝을 통해 컴퓨터가 학습하게 된다면 이미지에 대한 representation을 더 잘 이해할 수 있기 때문에 성능이 더 좋아 질 것이라고 가정한다.

논문에서 구조는 AlexNet을 기반으로 사용하였고, 이미지를 grid 할 때 약간의 gap을 두면서 crop하여 trivial solution을 피하려고 했다. 하지만 잘 해결되지는 않았다.
3. Jigsaw Puzzles (Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles)

다음 논문은 이전 논문과 마찬가지로 어느 정도 간격을 두어 9개의 patch를 crop한 후 random 하게 permutation 하여 원래의 permutation으로부터 만들어졌는지 예측하게 학습을 한다.
하지만 원래 9개의 patch는 총 9! (362880)개의 permutation을 갖기 때문에 현실적으로 학습이 불가능하다.
따라서 해당 논문에서는 100개의 미리 정의된 permutation만 사용한다. 따라서 output은 100차원의 vector 중 어느 permutation을 사용하였는지 예측하게 된다.
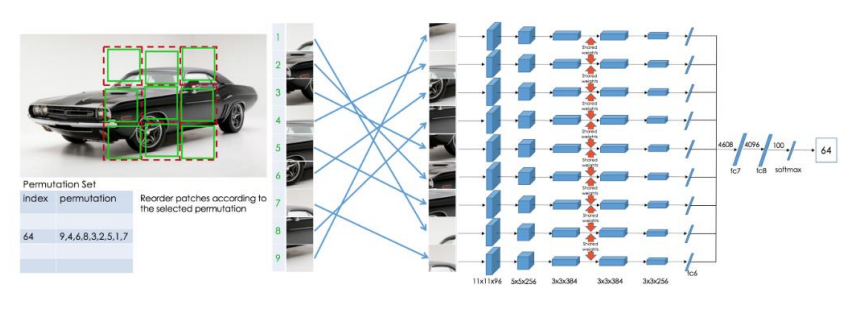
Network는 각 9개를 사용하였고, AlexNet 기반으로 제작되었다. 또한 weight는 서로 공유하는 구조이다.
4. Autoencoder-Base Approaches
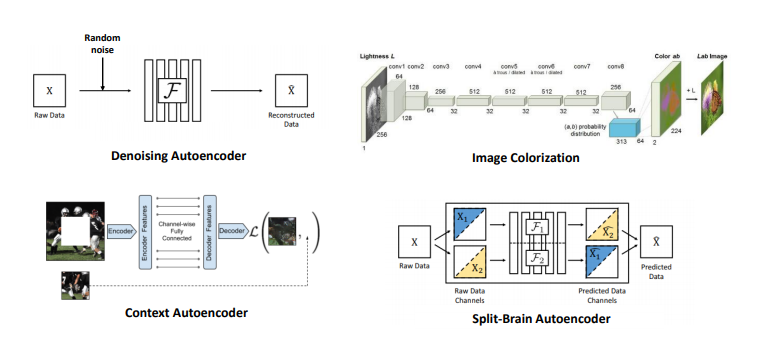
다음은 AutoEncoder를 기본으로 하는 접근법이다.
(1) Denoising Autoencoder: input image에 random noise를 주입한 뒤 복원을 하도록 학습을 시키는 방식이다.
(2) Image Colorization : 1channel image로부터 3 channel color image로 생성해내는 것을 학습시키는 방법을 제안하였고 이때 사용한 Encoder를 가져와서 Self-supervised learning task에 적용을 한 결과를 제시하고 있다.
(3) Context Autoencoder: image의 구멍을 뚫은 뒤 그 영역을 복원하는 것을 학습시키는 방식을 제안하고 있다.
(4) Split-Brain Autoencoder: Image Colorization의 후속 연구라고 할 수 있습니다. 다채널 image에서 channel을 쪼갠 뒤, 각각 channel을 예측하도록 학습을 시키는 방식에서 Split-Brain 이라는 이름이 붙게 되었으며, 예를 들면 RGB-D image에 대해 RGB image를 F1에 넣어서 Depth image를 예측하도록 학습을 시키고, Depth image를 F2에 넣어서 RGB image를 예측하도록 학습을 시킨 뒤 두 결과를 종합하는 방식으로 학습이 진행이 된다.
이 모든 기법들은 이미지 복원 기반으로 제작되었고, 이미지를 복원하면서 기본적인 representation을 배울 수 있다고 논문의 저자는 설명하였다.
5. Count (Representation Learning by Learning to Count)
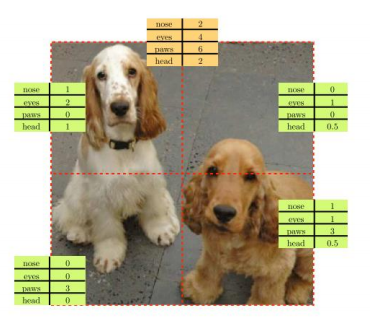
다음 논문은 각 영역을 가상의 vector들로 표현할 수 있다.
예를 들어 위 전체 이미지는 머리가 2개 눈이 4개로 표현되지만 이미지를 crop 할 시에는 각 영역 당 머리, 눈의 개수가 달라진다. 하지만 crop 한 이미지의 임의 vector를 다시 합치면 전체 이미지의 vector와 같아진다는 원리를 이용했다고 한다.
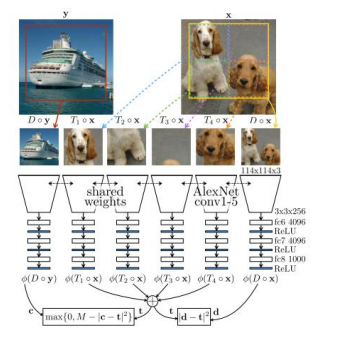
따라서 위 이미지와 같이 각각 down sampling 한 이미지를 model에 삽입하고, 각 feature vector를 추출한 다음 이 벡터들의 합과 원본 이미지에서 추출한 벡터들이 같아지도록 loss function을 구현하였다고 한다.
하지만 이렇게 학습을 시키면 모든 feature vector가 0으로 되어버리는 trivial solution이 발생할 가능성이 높아지는데, 이를 방지하고자 x와 함께 아예 다른 이미지 y를 같이 삽입해줌으로써 contrastive loss를 추가해주었다.
6. Multi-task (Multi-task Self-Supervised Visual Learning)

다음은 간단한 방법이다.
앞서 설명한 relative patch location, colorizaton, exemplar, motion segmentation을 동시에 학습시켜 결과적으로 가장 좋은 성능을 낼 수 있다.
7. Rotations (Unsupervised representation learning by predicting image rotations)
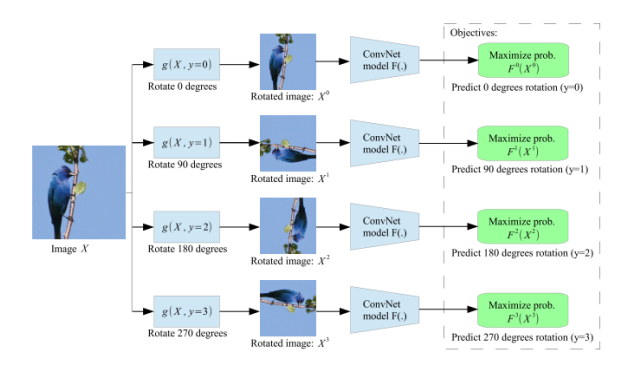
마지막으로 알아볼 논문은 원본 이미지로 부터 몇 도 가량 rotation 되었는지 예측하는 pretext이다. class는 0, 90, 180, 270으로 나누어진다.
이 논문의 저자는 원래의 이미지로부터 rotation이 얼마나 되었는지 예측하게 된다면 이미지에 대한 canonical orientation을 잘 이해하게 되고, 이를 배우게 되면 이미지의 전반적인 representation을 알 수 있을 것이라고 한다.
여기까지는 방법론이고 이제는 이를 어떻게 측정하는지 알아보자
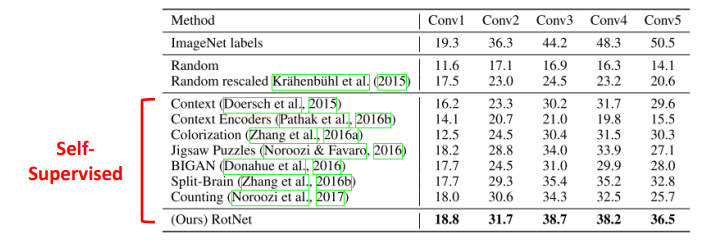
Task generalization을 측정하기 위해 imagenet classification을 downstream으로 가져가서 성능을 측정한다.
모든 unsupervised method들은 pre trained 된 imagenet으로 학습을 시키는데 이때는 label을 사용하지 않고 오로지 self-supervision으로 만든 pretext를 사용하여 학습을 시킨다.
그다음은 모든 feature map들의 weight를 freeze 시키고 마지막 layer에 linear classifier를 붙인다.
이때는 image net data도 사용하지만 label도 같이 사용하여 supervision 방법으로 학습한다.
이를 통해 성능을 측정한다.
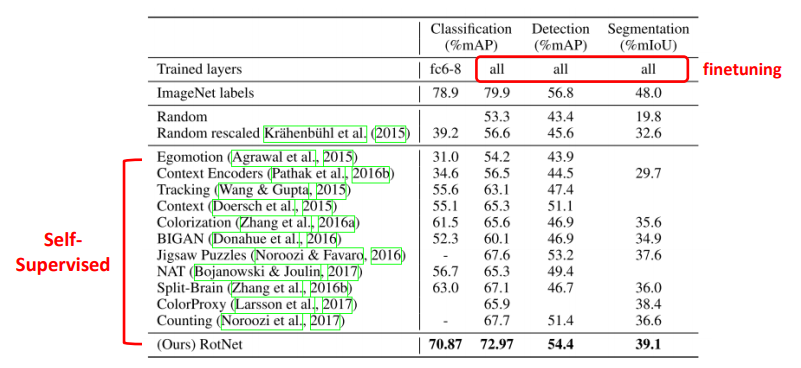
다음은 dataset을 변경하였을 때 얼마나 generalization 되는지 측정하는 지표이다.
Pascal voc를 사용했다. 3가지 task에 대해서도 실험을 했다.
'study > paper reviews' 카테고리의 다른 글
| CNN attention based networks (2) | 2021.03.12 |
|---|---|
| Deep anomaly detection using geometric transforms 분석 (0) | 2021.01.04 |
| Distilling the knowledge in a neural network 분석 (2) | 2020.10.15 |
| Neural Turing Machines 분석 (0) | 2020.10.13 |
| Accurate Image Super-Resolution Using Very Deep Convolutional Networks 분석 (0) | 2020.10.06 |



