
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- computervision
- pytorch
- support vector machine 리뷰
- svdd
- DeepLearning
- Object Detection
- RCNN
- darknet
- Faster R-CNN
- Deep Learning
- yolov3
- Computer Vision
- pytorch project
- 서포트벡터머신이란
- cnn 역사
- fast r-cnn
- SVM margin
- CNN
- self-supervision
- TCP
- 데이터 전처리
- SVM 이란
- EfficientNet
- 논문분석
- CS231n
- yolo
- cs231n lecture5
- SVM hard margin
- libtorch
- pytorch c++
- Today
- Total
아롱이 탐험대
Deep anomaly detection using geometric transforms 분석 본문
1. anomaly detection 방법론
(1) One-class classification

처음 살펴볼 방법은 one-class classification이다. 이 방법은 의료 분야에서 많이 쓰인다.
공장을 예를 들어보자. 공장에서 나온 제품들은 대부분 결함이 존재하지 않는다. 따라서 정상 제품 대비 비정상 (결함) 제품을 찾기가 힘들다.
데이터 분류를 위해서는 각 클래스에 해당하는 데이터가 균일하게 분포되어야 한다. 하지만 이러한 상황에서는 불균형이 생기게 된다. 이를 해결하고자 결함 이미지를 수집하는 것은 시간이 오래 걸린다.
따라서 정상 이미지만 가지고 정상인지 비정상인지 판단하는 one-class classification 방법이 나오게 되었다.
one-class classification은 우선 1가지 class를 가지고 학습을 진행한다. 테스트 과정에는 다른 분류 이미지도 넣어 진행한다. 여기서도 완전히 pure 한 데이터만을 가지고 학습시키는 방법이 있고, 약간의 noise가 존재하는 데이터도 함께 넣으면서 학습시키는 방법이 있다.
오늘 살펴볼 논문에서는 pure 버전에 대해서만 다루고 있다.
(2) multi-class classification

classification 분야에서는 학습된 class 이외에 전혀 다른 데이터에 대해 판별하는 것도 매우 중요한 문제이다.
mult-class classification은 자율 주행 자동차 분야에서 자주 쓰이는 기법이다.
오늘은 one-class classification 분야에 대해 집중적으로 알아보자.
one-class anormaly는 크게 3가지로 나눌 수 있다.
(1) statistical model

딥러닝을 사용하면 과거보다 dimensional detection을 더욱 잘 할 수 있다.
이를 사용한 방법이 바로 statistical model이다.
원리는 input 이미지를 NN (Neural Networks)를 통해 나온 row embedding을 임의의 확률 분포로 fitting 시킨다.
그러면 확률 분포는 정상 이미지에 대해서는 높은 density 값을 주고, 반대로 비정상 이미지에 대해서는 낮은 density 값을 준다.
위 화면에서 빨간색 점선 기준으로 외각으로 갈수록 비정상 이미지라고 간주한다.
(2) Recinstruction based model
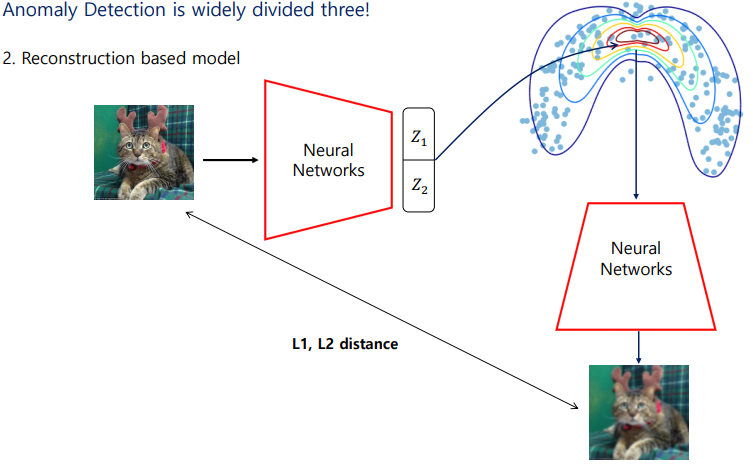
2번째 방법은 딥러닝을 사용하는 모델이다.
Auto encoder와 GAN등을 사용하는 모델이 이 분류에 속한다.
과정은 정상 이미지를 가지고 새로운 이미지를 만드는 sampling 과정을 거친다. 그러고 나서 여러 목적 함수를 가지고 학습을 진행한다.
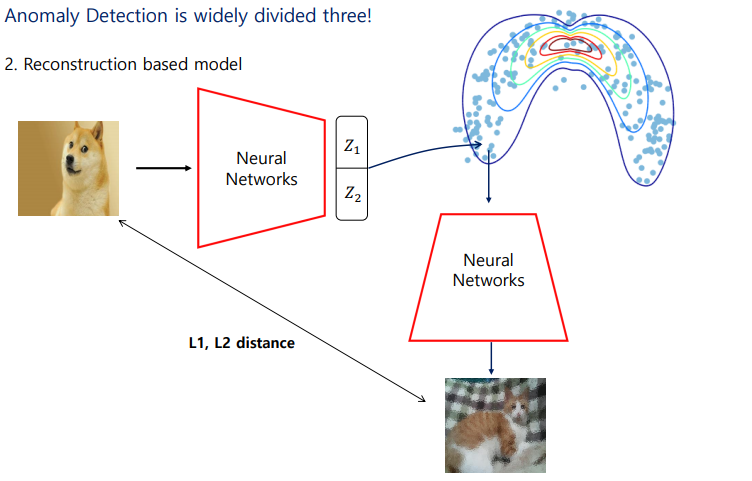
만약 비정상 이미지가 들어가면 NN 자체가 정상 이미지를 가지고 sampling을 하였기 때문에 눈으로 보기에도 이상한 이미지가 생성이 된다. 이 이미지를 가지고 L1, L2 distance가 높으면 비정상 이미지로 간주하게 된다.
(3) Kernel based model (DSVDD)
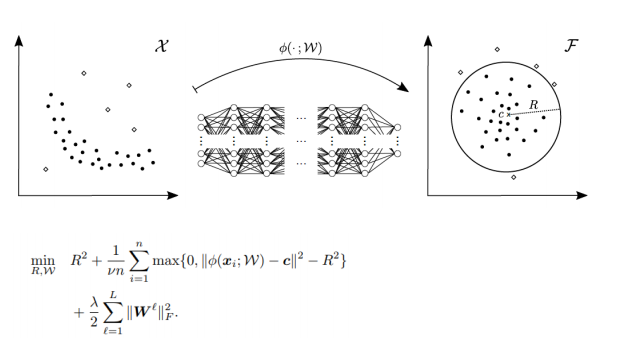
다음 방법은 정상 데이터를 NN과 Kernel을 사용하여 hyperspher를 이용해 인코딩을 해준다.
새로운 이미지가 들어오면 학습 과정에서 생성되었던 row dimensional embedding의 중심에서 새로운 이미지의 embedding의 거리를 가지고 anormal detection을 진행한다.
이 방법이 다른 방법들 보다는 성능이 가장 좋게 나왔다. 하지만 grayscale 한정이고, 높은 해상도에서는 정확도가 좋지 못했다.
2. 논문 본 내용
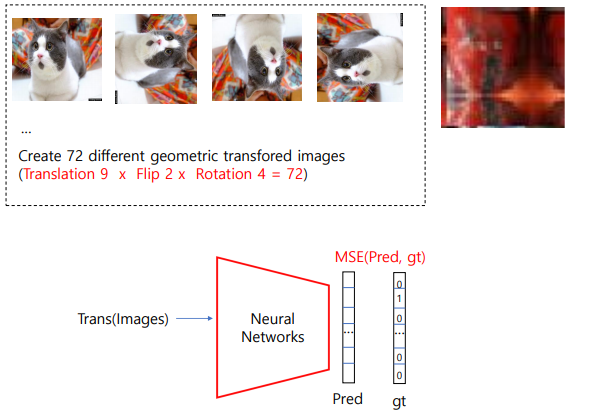
1장의 이미지가 있으면 9가지 방법으로 augmentation을 진행하고, 2개의 flip, 4개의 rotation을 적용하면 총 72가지의 geometric transform을 통해 데이터를 늘려 준다.
주의할 점은 transforming을 진행할 때 zero padding을 하면 성능이 잘 안 나온다고 한다. 또한 rotation 진행 시에도 주어진 4개의 각도로 진행해야 한다.
이 데이터를 가지고 NN에 넣어 input이 어떤 transform을 적용했는지 MSE나 cross entropy를 이용하여 학습을 진행한다.
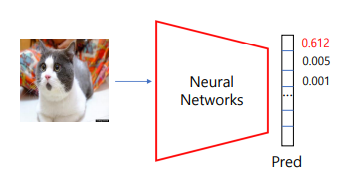
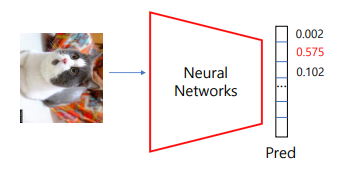
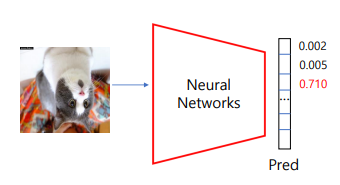
테스트 과정에서는 이미지가 들어왔을 때 그 이미지에 대한 확률 값이 나온다.
이 이미지의 72개의 확률에 대해 최대 확률을 다 더해주면 anomaly score가 나오게 된다.
score 계산은 2가지 방법이 있다.
1. simple version
- 위 계산과 같다.
2. complicated version
- softmax의 합은 1이기 때문에 dirichlet 확률을 도입할 수 있다.
이미지에 대한 확률에 대해 dirichlet 확률을 fitting 시킨다. 이를 통해 정상은 높은 density, 비정상은 낮은 density 값을 갖게 된다.

3. Result
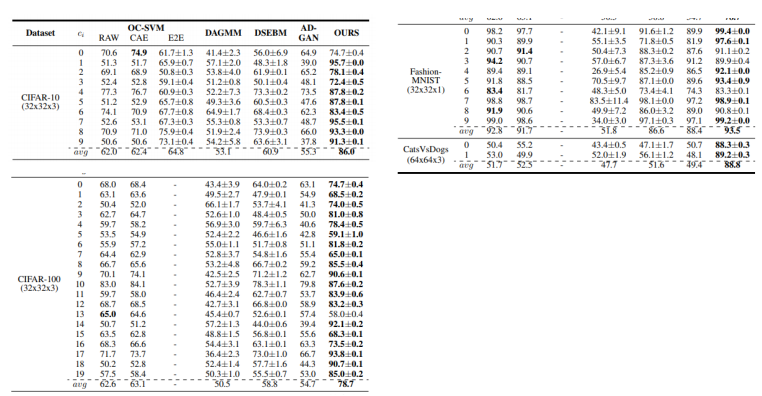
실험은 10개의 class에 대해 1가지 class를 결정한다. 그리고 data augmentation을 시키고 model에 넣는다.
성능 중 가장 큰 비중을 차지하는 augmentation은 rotation이라고 한다. (90%의 영향력이 있다.)
위 결과처럼 다른 model을 사용하는 것보다 해당 paper의 성능이 월등히 높은 것을 볼 수 있다.
4. Reference
'study > paper reviews' 카테고리의 다른 글
| Auto-Encoding Variational Bayes (VAE) 분석 (2) | 2021.07.14 |
|---|---|
| CNN attention based networks (2) | 2021.03.12 |
| Unsupervised Visual Representation Learning Overview: Toward Self-Supervision 분석 (0) | 2020.12.28 |
| Distilling the knowledge in a neural network 분석 (2) | 2020.10.15 |
| Neural Turing Machines 분석 (0) | 2020.10.13 |



