
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- computervision
- libtorch
- Object Detection
- Faster R-CNN
- self-supervision
- SVM hard margin
- EfficientNet
- 논문분석
- CNN
- 서포트벡터머신이란
- cs231n lecture5
- RCNN
- support vector machine 리뷰
- yolov3
- fast r-cnn
- darknet
- SVM 이란
- TCP
- 데이터 전처리
- CS231n
- DeepLearning
- Deep Learning
- svdd
- yolo
- pytorch project
- pytorch c++
- SVM margin
- cnn 역사
- pytorch
- Computer Vision
- Today
- Total
아롱이 탐험대
YOLO: You Only Look Once: Unified, Real-Time Object Detection 본문
YOLO: You Only Look Once: Unified, Real-Time Object Detection
ys_cs17 2020. 3. 18. 12:00You Only Look Once: Unified, Real-Time Object Detection
-Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi-
1. Introduction

저번 시간 분석하였던 Faster R-CNN에서는 real time에서 적용하기 힘든 단점이 있었다. 하지만 오늘 분석해볼 YOLO는 real time에 적용할 수 있는 속도를 갖고, 기존 real time에 적용시킨 network보다 약 2배정도 성능이 좋다. 기존 R-CNN network들은 two stage method였지만 YOLO는 one stage method이다. 또한 기존 network들은 주로 여러 객체를 탐지할 때 이미지에서 각 객체를 분할하여 탐지하였지만 YOLO는 이름의 의미와 같이 You Only Look Ones 즉 이미지를 한번만 보는 것으로 여러 객체들의 종류와 위치를 탐지하는 네트워크이다. 이로 인해 속도는 더욱 증진시키고, 낮은 background error를 보인다.
간단한 시행 영상과 기술 요약은 https://www.youtube.com/watch?v=Cgxsv1riJhI 를 보면 이해가 될 것이다.
2. Network

우선 모델의 전체적인 구성을 단계별로 보면
1) 이미지를 S*S Grid로 나눈다
2) 여기서 각각의 Grid cell은 b개의 bounding box와 이에 대응하는 confidence score를 갖는다. 만약 해당 cell의 객체가 감지되지 않으면 confidence score는 0이다.

3) 각각의 grid cell은 c개의 conditional class probability를 갖는다.

4) 각각의 bounding box는 x, y, w, h, confidence로 구성이 된다. 여기서 (x, y)는 bounding box의 중심점이고 이는 grid cell의 상대적인 좌표로 결정된다. 만약 x가 grid cell의 가운데 있으면 x는 0.5이다. (w, h)는 전체 이미지 크기의 상대적인 비율로 나타낸다. 만약 width가 전체 이미지의 50%이면 w는 0.5이다.
Test할 때는 위에서 구한 conditional class probability와 confidence score를 곱해 class specific Confidence를 구한다.

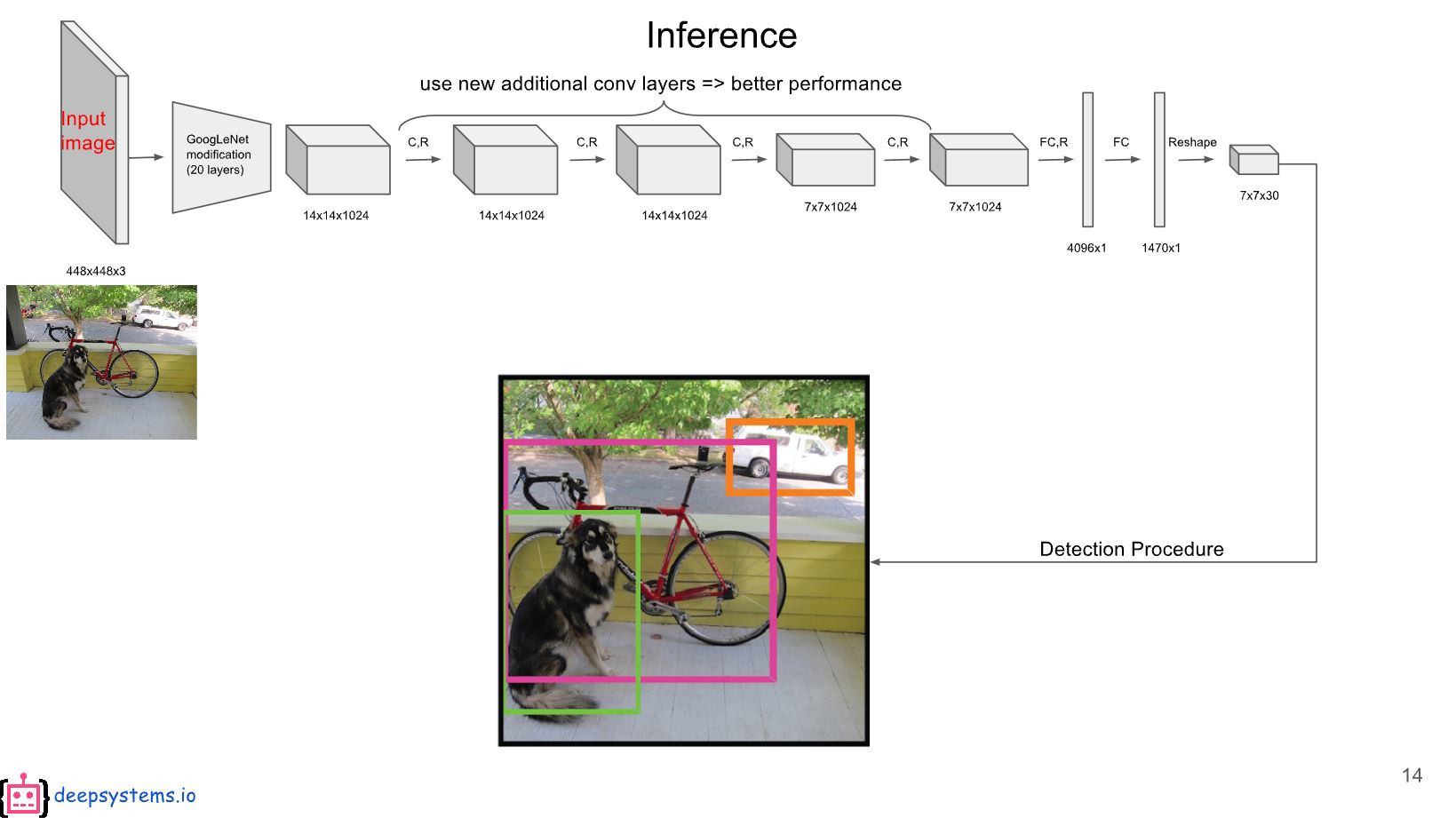
사용되는 network의 전체적인 구성이다. 이 network는 google net을 기반으로 만들었다고 한다. 또한 google net후 추가적으로 4개의 convolution layer와 2개의 fc를 사용하였다.

논문에서도 설명했던 것처럼 각 parameter들을 S, B, C 순서로 (7, 2, 20)이라고 가정하고 설명하겠다.
우선 grid cell을 7*7로 나눈 후 앞에 5개에는 첫번째 bounding box의 x, y, w, h, confidence 값이 채워진다. 또한 그 다음은 두번째 bounding box에 해당하는 x, y, w, h, confidence의 값이 채워진다. 그 후 나머지 20개에는 class에 대한 conditional class probability 값이 채워진다.
위에서 설명한 class specific confidence score를 계산을 하려면 첫번째 bounding box 기준으로 idx 4에 해당하는 confidence 값과 10~29에 해당하는 20개의 conditional class probability를 곱하면 구할 수 있다.

따라서 각 7*7개의 grid cell에 각 2개씩 존재하는 bounding box의 class specific confidence score를 계산을 하면 총 98개를 얻을 수 있다. 이 98를 가지고 non-maximum suppression을 하여 20개의 class로 구별되어 있는 object와 이에 대응되는 location을 구할 수 있다.
YOLO에서 사용되는 loss function을 분석해보면

(1) Object가 존재하는 grid cell i의 predictor bounding box j
(2) Object가 존재하지 않는 grid cell i의 bounding box j
(3) Object가 존재하는 grid cell i

Lamda coord: coordinate(x,y,w,h)에 대한 loss와 다른 loss들과 균형을 위한 parameter
Lamda noobj: obj가 존재하는 box와 존재하지 않는 box에 균형을 위한 parameter
해당 논문에서는 위 이미지처럼 진행하였다고 한다.

전체적인 loss function을 살펴보면 object가 존재하는 grid cell i의 bounding box에 대해 x, y, w, h에 해당하는 loss를 구하고, 해당하지 않는 bounding box에 대해 conditional class probability를 계산한다. 또한 맨 아래에서는 object가 존재하는 grid cell i에 대해 conditional class probability를 계산하여 더한다.

또한 해당 network에서 activation function은 rectified linear activation을 사용하였다.
3. result

Pascal VOC 2007로 train 결과 real time에 속하는 network들 사이에서는 63.4라는 압도적인 결과를 가졌고, real time에 속하지 못하는 네트워크와 비교를 하였을 때 나쁘지 않는 결과가 나왔다.

또한 Fast R-CNN과 비교하였을 때 selective search가 아닌 한번에 image를 detecting하는 방식으로 background를 훨씬 더 잘 감지하는 결과를 보였다.
하지만 YOLO에게도 한계가 존재하는데 그건 바로 작은 물체에 대해서는 감지 능력이 약하다. 하지만 real time을 준수하고, 정확도 측면에서는 실생활에 적용하기 좋은 네트워크라고 생각한다.
4. reference
You Only Look Once: Unified, Real-Time Object Detection (paper)
https://curt-park.github.io/2017-03-26/yolo/
https://www.youtube.com/watch?v=L0tzmv--CGY&feature=youtu.be
'study > paper reviews' 카테고리의 다른 글
| YOLO9000: Better, Faster, Stronger (YOLOv2) (0) | 2020.05.07 |
|---|---|
| SSD: Single Shot Multibox Detector (0) | 2020.03.23 |
| Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (0) | 2020.03.16 |
| VGG NET: Very Deep Convolution Networks For Large-Scale Image Recognition (0) | 2020.03.13 |
| Fast R-CNN (0) | 2020.03.13 |



