
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- darknet
- computervision
- CS231n
- pytorch project
- RCNN
- 데이터 전처리
- DeepLearning
- Deep Learning
- Object Detection
- CNN
- yolo
- pytorch c++
- self-supervision
- SVM hard margin
- Faster R-CNN
- Computer Vision
- libtorch
- 논문분석
- svdd
- 서포트벡터머신이란
- pytorch
- support vector machine 리뷰
- fast r-cnn
- SVM 이란
- cs231n lecture5
- EfficientNet
- yolov3
- SVM margin
- TCP
- cnn 역사
- Today
- Total
아롱이 탐험대
Lecture 2: Image Classification pipeline 본문
본 정리에 앞서 현재 cs231n은 3 회독을 했지만 마지막 Lecture까지는 보질 못했다.
이번 기회에 다시 처음부터 cs231n을 공부하며 기본기를 다지려고 한다.
https://www.youtube.com/watch?v=3QjGtOlIiVI&list=PL1Kb3QTCLIVtyOuMgyVgT-OeW0PYXl3j5를 보며 공부하며 리뷰하였고, 어느 정도 deep learning에 대해 안다고 가정하고 글을 작성하겠다. 만약 밑바닥부터 시작하는 딥러닝을 안 봤으면 먼저 이 책을 본 후 cs231n을 공부하길 바란다. 본인은 처음부터 cs231n을 보며 공부를 하다가 한동한 힘들었다. (cs231n은 스탠퍼드 대학원 강의입니다.)
Lecture 1은 기본적인 오리엔테이션이니 시간이 남을 경우 보는 것을 추천한다.
그러면 lecture2를 시작하겠다.

computer vision에 있어서 image classification은 핵심적인 문제 중 하나이다. 여기서 image classification이란 말 그대로 컴퓨터가 이미지를 보고 어떤 object인지 알아맞히는 문제다.

컴퓨터가 이미지를 볼 때에는 사람과 달리 숫자로 구성된 array들의 합으로 보게 된다.
위 이미지와 같이 각 픽셀마다 rgb값이 있고 이 이미지의 size는 300*100*3 (height*width*channel)이다. 여기서 channel에 해당하는 값은 해당 이미지가 RGB형식으로 되어 있어 3 채널이 된다.
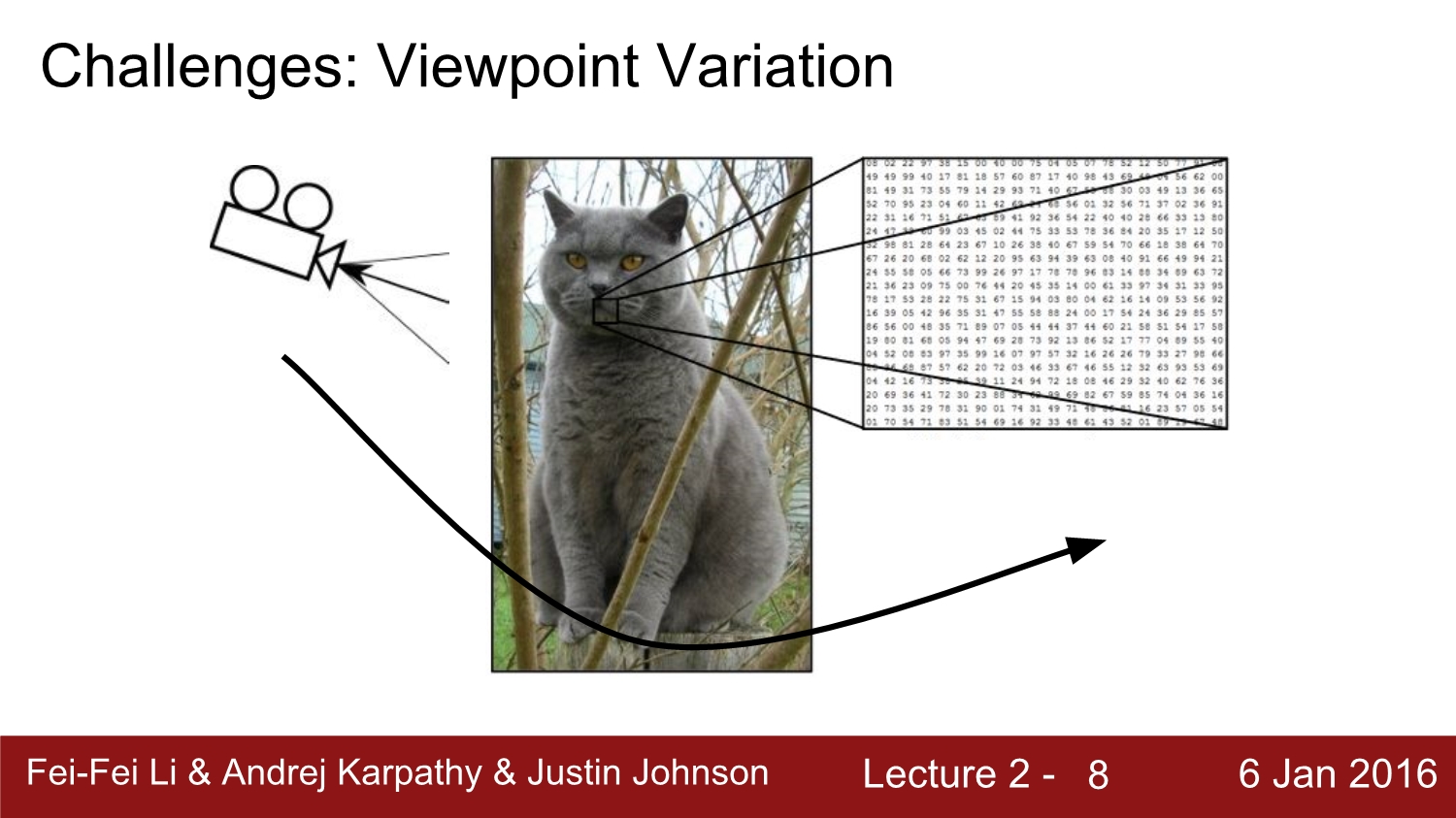
하지만 컴퓨터가 object를 인식하기에 위 이미지처럼 다른 각도에서 보는 이미지 등 환경적으로 많은 이미지의 변형들이 존재한다. 대표적인 예시를 보자





이처럼 다양한 많은 문제점들이 존재한다. 컴퓨터가 이미지를 예측하기 위해서는 어떻게 해야 할까?

기본적인 predict함수 구성은 image를 함수의 input으로 넣으면 class label을 return 해주는 구조이다.

역사적으로 컴퓨터 비전에 있어서 다양한 방법들과 시도들이 많이 있었다. 이미지에서 윤곽선이나 shape를 detect 하여 library 화하거나 image array 관점으로 접근하여 기존 image array들과 비교하여 탐색하는 방법 등 다양하게 존재하였으나 정확도와 속도 측면에서 문제점들이 많이 존재하였다.

우리는 이미지와 라벨로 구성되어있는 데이터를 가지고 적절한 모델에 학습을 시킨 후 테스트 용 이미지를 통해 ㅠㅕㅇ과를 할 것이다.

우리가 사용할 dataset은 CIFAR-10이라고 불리는 data이다. 이 data들은 30*30 size로 총 10개의 label로 구성되어 있으며 50000장의 train image, 10000장의 test image를 제공한다.
오른쪽 이미지는 Nearest neibor라는 알고리즘을 통해 나온 이미지들이다. 자세히 보면 전혀 엉뚱하게 라벨링 되어있는 이미지들을 볼 수 있다.

Nearest neighbor란 현재는 쓰이지 않는 알고리즘이지만 여기서는 교육용으로 넣었다고 한다.
이는 단순히 test image의 array값과 train image의 array 값을 뺀 후 모든 array값들을 더해서 0에 가까울수록 서로 비슷하다고 판단하는 알고리즘이다.

Nearest neighbor 알고리즘을 구현한 코드이다.
우선 train 함수를 통해 X와 y를 넣어준다.
그다음 predict 함수에서 distance 계산을 해준 뒤에 결괏값이 가장 적은 label을 return 한다.
Nearest neighbor의 가장 큰 문제점은 이미지 1개를 predict 할 때마다 train의 존재하는 모든 image들을 탐색해야 한다. 따라서 time complexity는 O(n)이고, 이는 데이터가 많아질수록 시간도 linear 하게 증가한다는 의미이다.

이 논문은 nearest neighbor algorithm도 빨라질 수 있다는 논문이다. 이 강의에서는 생략했다.

L1 distance도 존재하지만, L2 distance 또한 존재한다. 이 둘은 hyperparmeter이기 때문에 실험을 통해 둘 중 더 좋은 성능을 내는 distance를 선택해야 한다.

Nearest neighbor 후에 나온 k-Nearest Neighbor는 실행 방식은 비슷하지만 k개의 가까운 이미지를 찾고 이 중에서 다수결로 label값을 return 하는 algorithm이다. 위에 사진을 보면 NN보다 K-NN의 성능이 더 좋은 것을 확인할 수 있다.

이것은 K-NN으로 나온 결괏값들인데 물론 NN보다는 성능이 좋아졌지만 여전히 정확도는 많이 떨어진다.
왜냐하면 아무리 1위인 라벨이 정답 이어도 2,3,4,5가 오답 라벨을 선택했으면 그 image는 오답이 된다.

또한 테스트에 있어서 train set과 test set을 분리를 해야 한다. 왜냐하면 물론 test와 train 둘 다 같게 두면 test data에 한해 인식률은 좋아질 것이다. 하지만 우리가 원하는 건 컴퓨터가 한 번도 보지 못한 이미지들을 인식하는 것이다. 이뿐만 아니라 나중에 배우게 될 overfitting이라는 문제점도 존재한다.

또한 validation data set이라고 불리는 영역도 존재한다. 이는 hyper parameter를 결정하기 위한 train data set이라고 생각하면 된다. 만약 validation data set이 존재하지 않는다면 우리는 일일이 수많은 실험을 통해 hyper parameters를 결정해야 할 것이다.
그리고 여기서 Cross-valiation이라는 기법이 나오게 되는데 이는 각 train data를 k개의 fold로 나눈 후 각 iteration 마다 첫 번째는 fold1이 validation data, 두 번째는 fold2가 validation data... 이런 식으로 진행을 하는 기법이다. 이는 data가 적을 때 사용하면 효과적인 기법이다.
정리를 하자면 data는 크게 train, validation, test로 나뉘고 test data는 무슨 일이 있어도 train 과정에서 절대로 쓰이면 안 된다.

위는 k의 개수에 따라 정확도를 보여준다.

K-NN을 사용하면 안 되는 이유를 설명하고 있다. 가장 큰 이유는 distance는 예측을 100% 하는 것이 아니다. 위 이미지들을 보면 살짝 이동하였거나, 없어졌거나, 밝기가 다르면 모두 다른 이미지로 인식을 하게 된다.

다음은 Linear classification으로 넘어가 보자

앞으로 배울 것들은 모두 parameter를 기반으로 한다.

우리는 input과 weight를 계산을 하여 새로운 Giant matrix를 만들어 낸다. 여기서 weight 즉 W 값은 우리가 직접적으로 control를 해줘야 한다. input값과 W값을 계산한 후 bias라 불리는 b값을 더해준다.

앞에 설명했던 것처럼 W와 input을 행렬 연산을 통해 곱해준 다음 b값을 더해주고 score 값을 측정한다.
결과를 보았을 때는 dog score가 가장 높아 이 W값들은 별로 좋지가 않은 값들이라는 사실을 알 수 있다.

linear classifier로 학습된 weight들의 값을 보았을 때 car와 같은 weight는 확실히 자동차처럼 보이지만 dog나 horse 같이 역동적이거나 방향이 다른 이미지들은 성능이 별로 좋지 않아 보인다.

linear classifier를 공간적으로 해석하게 되면 확실히 선형적인 방법들은 한계가 있는 것을 알 수 있다.

우리가 지금까지 정의한 것은 score function을 정의한 것이다. 앞으로 우리는 loss function을 정의하며 더욱 정확성을 높이고, 손실을 줄어나가야 한다.
referance
http://cs231n.stanford.edu/2016/
Stanford University CS231n: Convolutional Neural Networks for Visual Recognition
Can I audit or sit in? In general we are very open to sitting-in guests if you are a member of the Stanford community (registered student, staff, and/or faculty). Out of courtesy, we would appreciate that you first email us or talk to the instructor after
cs231n.stanford.edu
'study > cs231n' 카테고리의 다른 글
| Lecture 6: Training Neural Networks, Part 2 (0) | 2020.04.13 |
|---|---|
| Lecture 5-2: Training NN part 1 (~Data preprocessing) (0) | 2020.04.13 |
| Lecture 5-1: Training NN part 1 (~activation function) (0) | 2020.04.13 |
| Lecture 4: Backpropagation and Neural Networks part 1 (0) | 2020.03.25 |
| Lecture 3: Optimization (0) | 2020.03.20 |



