
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- RCNN
- pytorch
- libtorch
- Computer Vision
- yolo
- EfficientNet
- 서포트벡터머신이란
- Deep Learning
- support vector machine 리뷰
- SVM 이란
- darknet
- pytorch c++
- self-supervision
- cnn 역사
- 데이터 전처리
- CS231n
- SVM margin
- Object Detection
- 논문분석
- SVM hard margin
- svdd
- computervision
- yolov3
- Faster R-CNN
- CNN
- pytorch project
- TCP
- DeepLearning
- fast r-cnn
- cs231n lecture5
- Today
- Total
아롱이 탐험대
Lecture 3: Optimization 본문
lecture 3에서는 lecture 2에 이어서 loss function과 optimization에 대해 리뷰하겠다.
우선 이번 챕터에서는 유명한 loss function인 SVM과 softmax에 대해 설명한다.

지난 시간에 이어서 input에 weight를 곱하고, bias를 더함으로써 3개의 label에 대해 loss를 결과 값을 구하였다.
이 결괏값들을 loss function을 통해 loss를 도출하게 되는데 우선 처음 알아볼 loss function는 SVM이다.
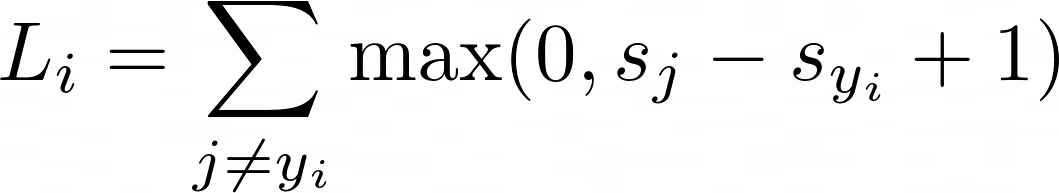
SVM은 위와 같이 정의되며 첫 번째 cat에 대한 loss는 계산을 하면 2.9가 된다.

car에 대한 loss는 0이다.

flog가 10.9으로써 loss가 가장 크고, 이는 인식률이 별로 좋지 않다는 것을 의미한다.

또한 full training loss는 3개의 loss를 label의 개수로 나누면 4.6이 된다.

SVM을 python으로 구현을 하면 이렇게 된다. 식을 넘 파이를 사용하여 그냥 변환한 것이다.

하지만 SVM에는 버그가 있다고 한다. 만약 우리가 Loss가 0인 W를 발견했다고 가정하자. 그러면 W는 unique 할까?

아까 예시와 같이 car label은 loss가 0이었다. 하지만 car에 대한 모든 loss들을 2배해도 이들은 전혀 unique하지 않다.

따라서 우리는 unique 하게 하기 위해 lamda 즉 weight regularization을 해준다.
이건 w가 얼마다 괜찮은지를 측정을 해준다. 결과적으로 보았을 때 weight regularization을 해주면 train set에 대한 정확도는 낮아지지만, test에 대한 정확도는 올라간다고 한다.

regularization 같은 경우 위 사진처럼 둘 다 함은 1이지만 w1보다는 w2가 더 좋다고 한다. 왜냐하면 모든 feature에 대해 영향을 주는 것이 더 좋기 때문이다. 따라서 regularization은 최대한 spread out 하여 사용한다.

다음은 2번째 loss function인 softmax에 대해 알아보자
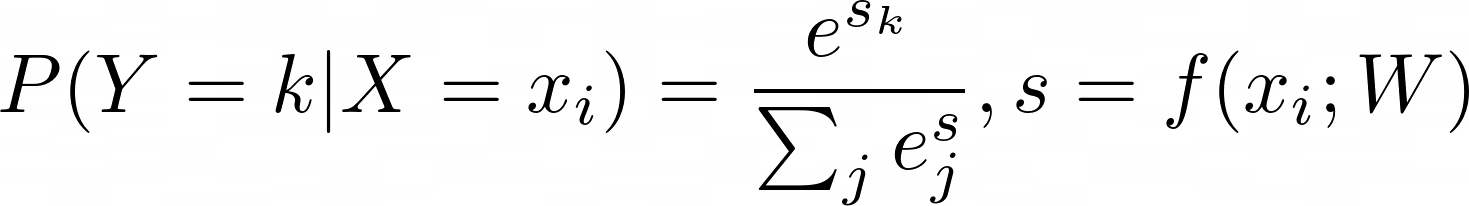
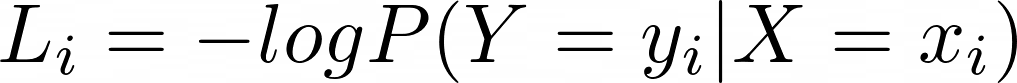
softmax는 이렇게 정의한다.
정확한 class의 -log를 최소화하는 방법인데 이는 Cross entrpy loss라고 부른다.

cat에 대한 loss를 softmax를 하여 loss를 계산해보면 우선 처음에는 exp를 해주고 2번째는 normalize후 cross entropy를 통해 최종적으로 cat에 대한 0.89를 얻었다.
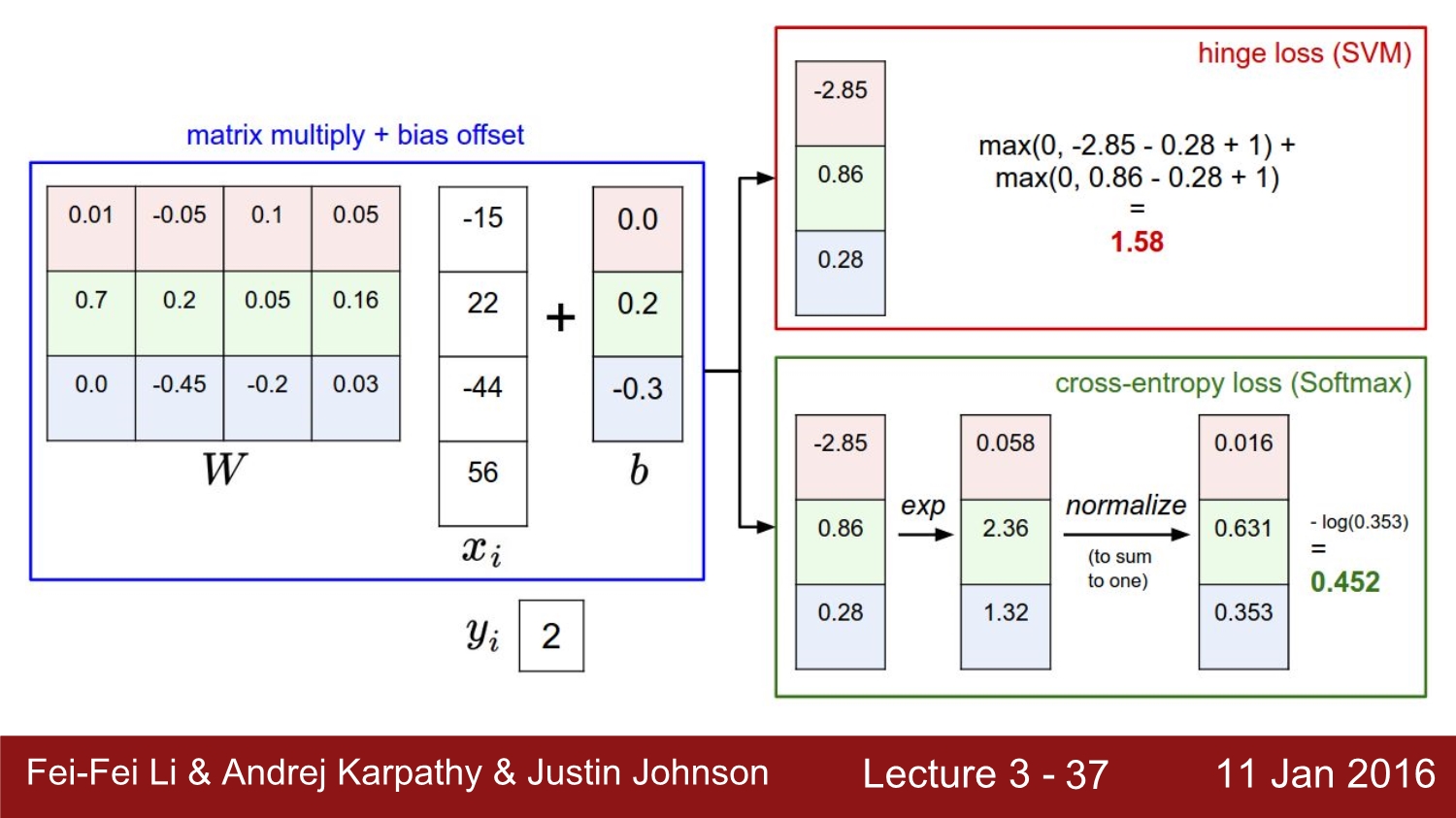
최종적인 loss를 SVM과 Softmax를 비교하면 각각 1.58, 0.452가 나온다.
비교를 하자면 SVM은 변화의 대해 둔감하고, softmax는 이에 반대라고 한다.

다음은 optimization에 대해 알아보자

지금까지 배운 것을 다시 보면 data set과 weight, bias가 만나 계산을 하고 이를 loss function을 통해 loss를 구한다.
하지만 loss는 weight에 대해 영향을 받는데 loss를 더욱 줄이고, 최적화를 시키려면 optimization 과정이 필요하다.

optimization 방법 중 하나인 random search는 말 그대로 weight를 random 하게 하는 것이다. 이는 절대로 쓰면 안 되는 방법이다.

random search를 통해 얻은 결과 15.5%의 정확도를 얻었다. 현재 SOTA가 95%인걸 보면 매우 낮은 정확도이다.

random search를 비유하자면 산 골짜기에서 눈을 가리고 텔레포트하는 거와 같다고 한다.

따라서 우리는 최적의 값을 구하기 위해 기울기를 구할 수 있는 수치 미분을 사용한다.
수치 미분이란 우리가 수학을 할 때 사용하는 미분과 달리 h의 값을 매우 작은 값으로 설정하여 순간 기울기 변화량을 구하는 미분법이다.

수치 미분을 사용하여 얻어진 기울기 값이다. (h를 0.0001로 설정했다.)

수치 미분의 단점은 우선 h의 값이 근삿값이라 정확하지 않고, 평가를 하는데 속도가 오래 걸린다는 단점이 있다.

따라서 우리는 numerical gradient를 사용하지 않고, analytic gradient를 사용한다. 하지만 numerical graident는 코드로 구현하기 쉽고, analytic gradient의 값을 확인할 때 사용한다.

다음은 앞에서 구한 gradient를 통해 weigth를 갱신을 해줘야 한다.
weight는 step size와 gradient를 곱한 값을 빼면서 갱신을 하는데 여기서 step size는 hyper parameter이다.
따라서 우리는 validation을 통해 step size를 결정하면 된다.

우리가 지금까지 배운 갱신 방법은 training set을 모두 사용한 것이다. 하지만 현재 사용되고 있는 방법은 mini batch를 사용하여 training set 중 일부만 사용한다.
이 방법은 효율적으로 성능을 높인다고 한다. mini batch의 size는 자신이 사용하고 있는 ram과 gpu에 맞게 설정하면 된다.
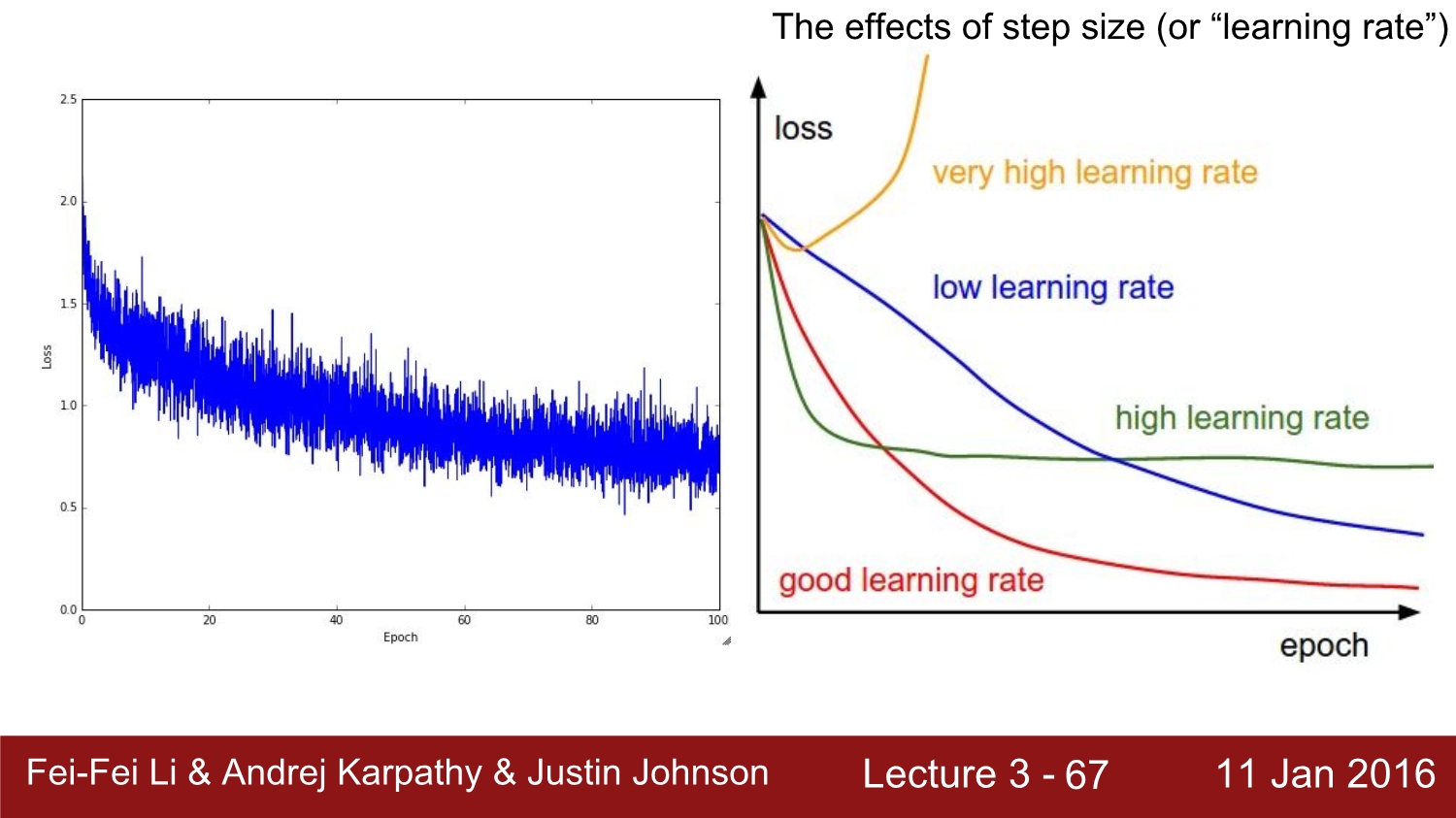
위 그림은 mini batch를 사용하였을 때 나타나는 loss 값들이다. mini batch가 모두 달라서 그래프의 결과가 직선이 아닌 마구잡이로 되어있는 것을 볼 수 있다.
그리고 오른쪽은 step size 즉 learning rate의 설정인데 이는 초반에는 약간 큰 learning rate를 사용하다가 점점 값을 낮추는 방법으로 설정한다고 한다.
우리가 배운 update 방식은 SGD라고 부르고, 갱신 방법은 여러 방법이 존재한다.
ex) Momentum, NAG, Ada, Adagrad 등...
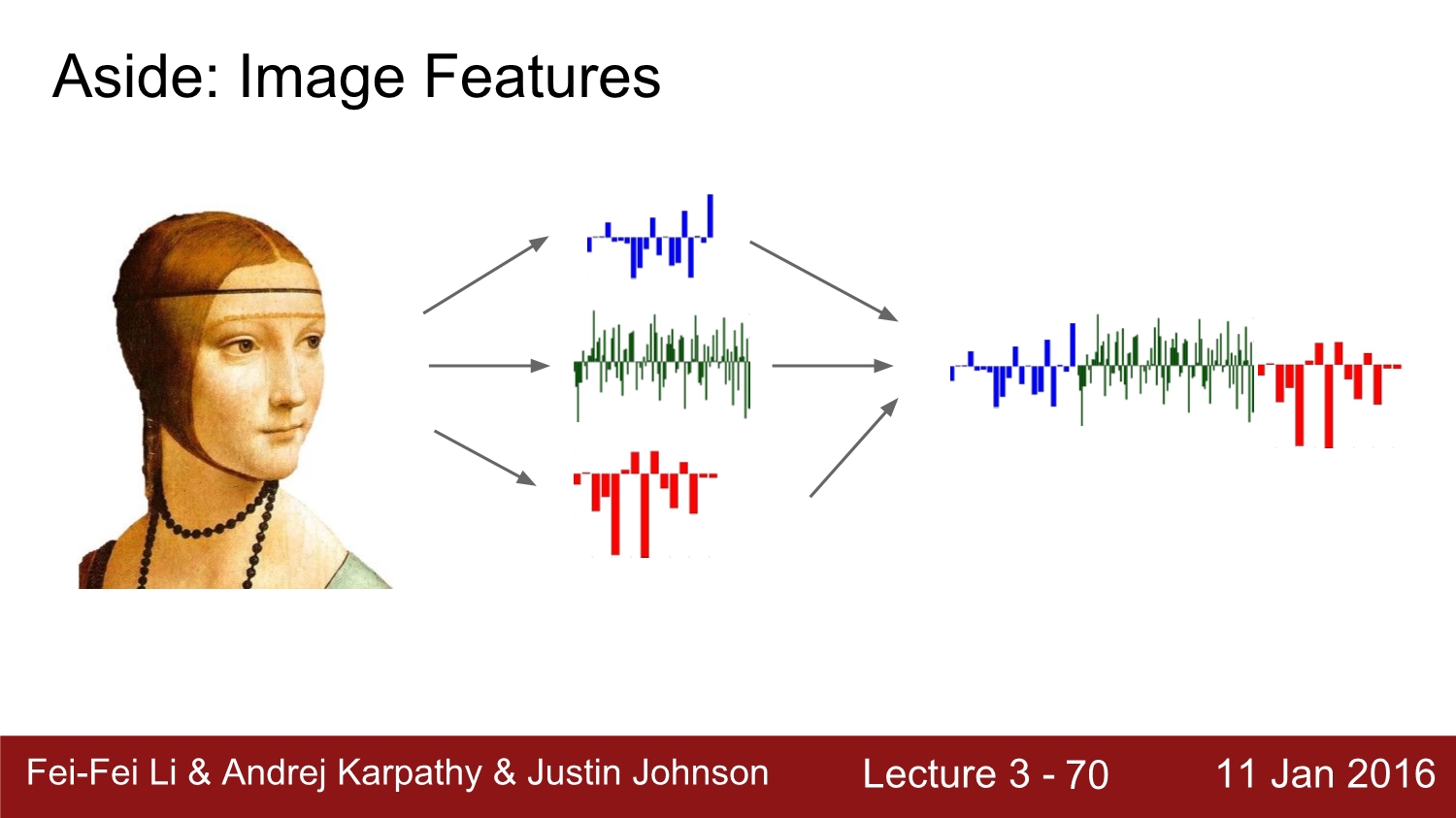
과거에 image의 feature를 찾을 때는 각 pixel의 RGB 값을 뽑고 이 값들을 hist 화하여 linear classifier를 진행하였다고 한다.
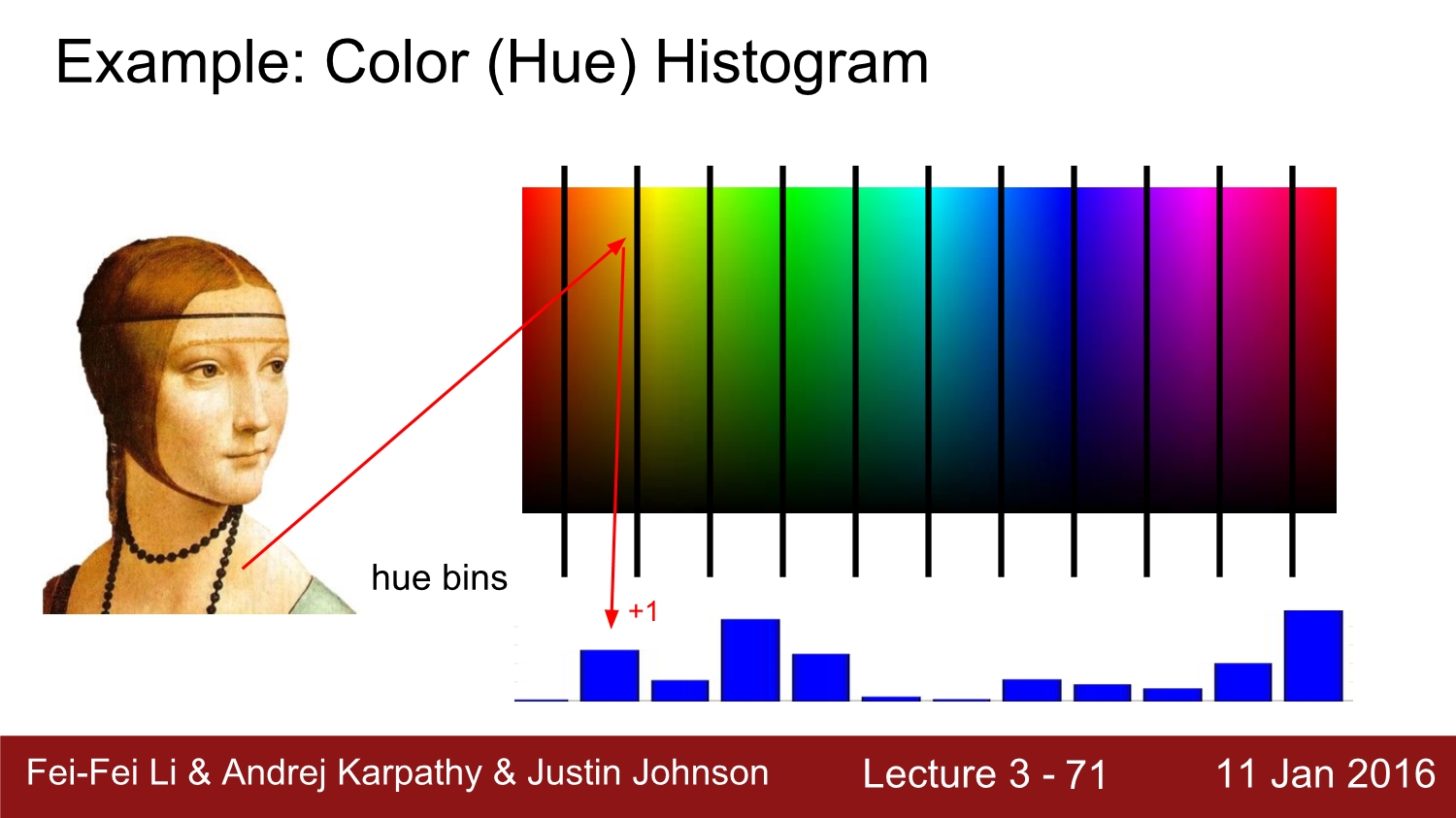
이 히스토그램 값들을 통해 edge와 같은 feature를 찾을 수 있다.
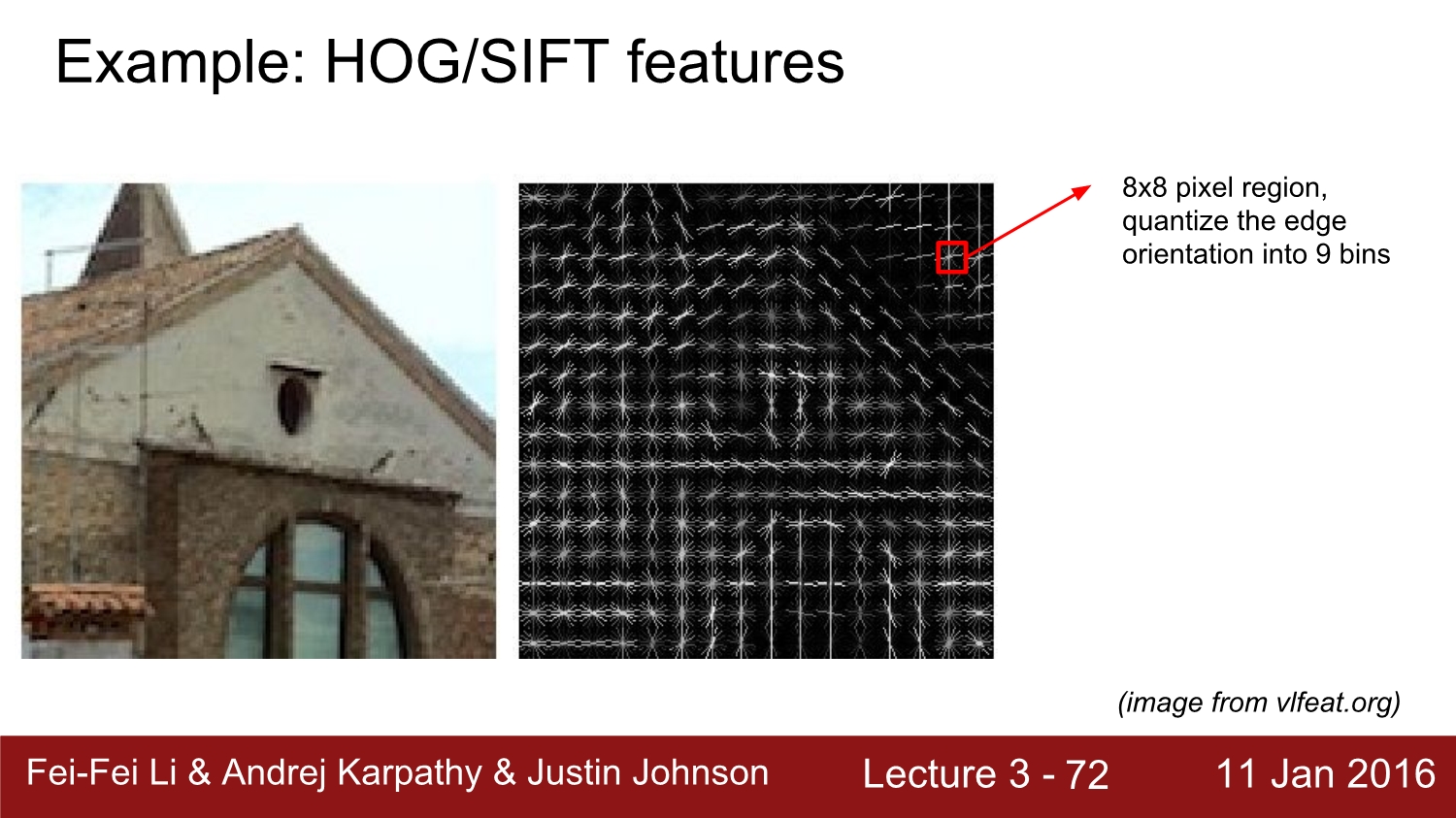
또 다른 방법은 HOF와 SIFT를 활용하여 feature를 찾는 방식이다.
이는 edge의 방향을 9가지로 구분하여 threshold를 따라 8*8 pixel의 방향을 결정하여 feature를 추출한다.

Bag of words는 우선 이미지의 작은 local patch를 보고 벡터를 통해 사전을 만든다. 그리고 가장 유사하게 생긴 이미지를 k-means를 통해 찾고, linear classifier를 사용하여 구별한다.
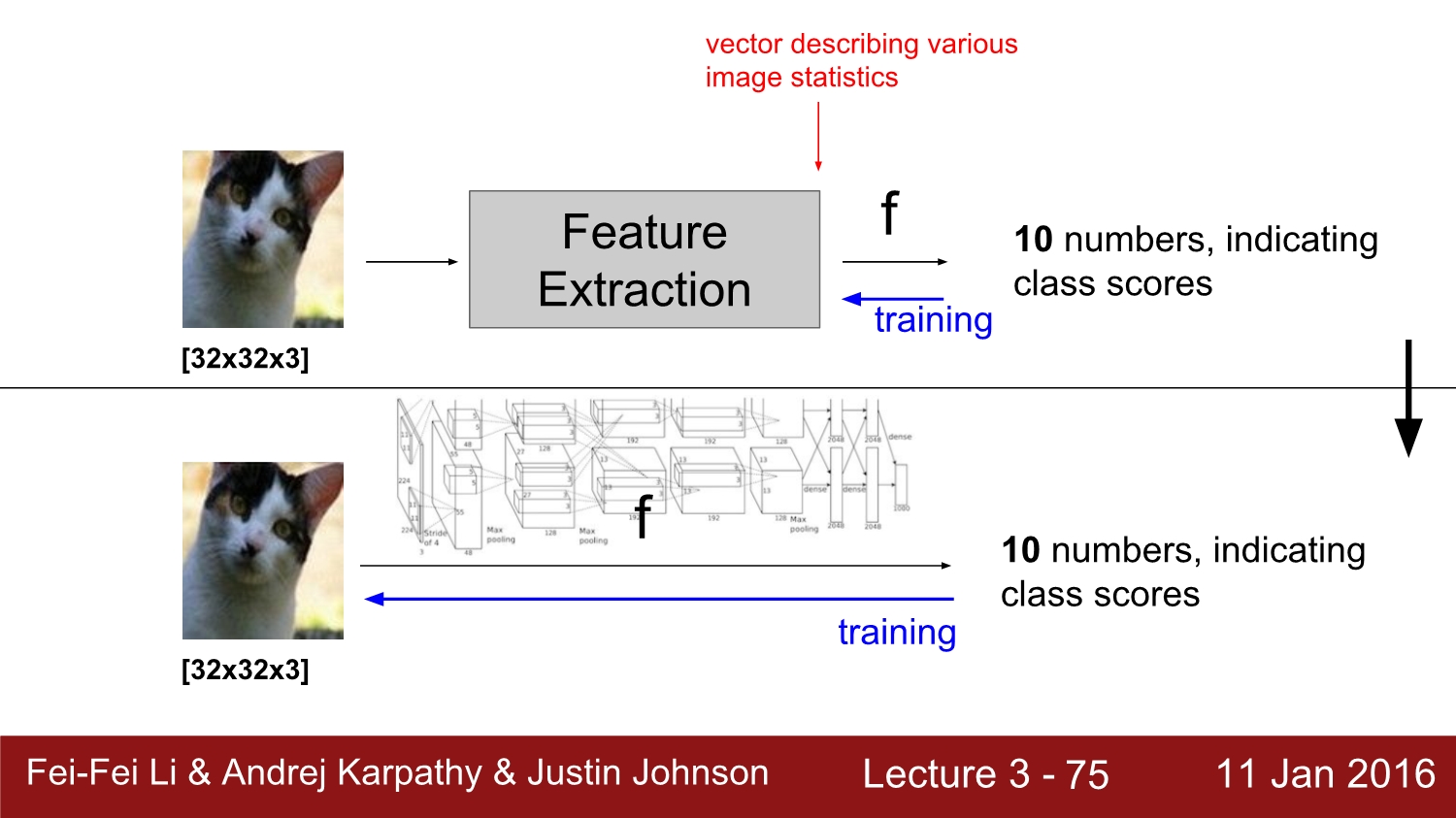
이전까지의 영상처리와 현재의 영상 처리의 차이점은 바로 특징점 추출이다. 현재 사용하고 있는 딥러닝 모델들은 특징점을 따로 찾지 않고 model을 통해 영상의 결괏값을 얻는다.
referance
http://cs231n.stanford.edu/2016/
Stanford University CS231n: Convolutional Neural Networks for Visual Recognition
Can I audit or sit in? In general we are very open to sitting-in guests if you are a member of the Stanford community (registered student, staff, and/or faculty). Out of courtesy, we would appreciate that you first email us or talk to the instructor after
cs231n.stanford.edu
'study > cs231n' 카테고리의 다른 글
| Lecture 6: Training Neural Networks, Part 2 (0) | 2020.04.13 |
|---|---|
| Lecture 5-2: Training NN part 1 (~Data preprocessing) (0) | 2020.04.13 |
| Lecture 5-1: Training NN part 1 (~activation function) (0) | 2020.04.13 |
| Lecture 4: Backpropagation and Neural Networks part 1 (0) | 2020.03.25 |
| Lecture 2: Image Classification pipeline (0) | 2020.03.19 |



