
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- DeepLearning
- EfficientNet
- 데이터 전처리
- darknet
- pytorch
- cs231n lecture5
- 서포트벡터머신이란
- Computer Vision
- yolov3
- RCNN
- 논문분석
- CNN
- SVM hard margin
- fast r-cnn
- computervision
- CS231n
- Deep Learning
- Object Detection
- TCP
- SVM 이란
- Faster R-CNN
- cnn 역사
- svdd
- support vector machine 리뷰
- libtorch
- SVM margin
- pytorch project
- pytorch c++
- self-supervision
- yolo
- Today
- Total
아롱이 탐험대
Lecture 5-2: Training NN part 1 (~Data preprocessing) 본문

activation function에 이어 data preprocessing에 대해 알아보자

데이터의 전처리 과정은 우선 각각에 대해 평균을 빼줌으로써 zoro-centered 시키는 과정을 통해 정규화를 진행한다.
하지만 image에서는 zero-centered 과정은 필요하지 않다. 그 이유는 각각의 pixel은 0~255까지의 범위이기 때문이다.

PCA와 Whitening이라는 주성분 분석은 데이터의 차원을 줄이고자 진행한다. 하지만 이미지에서는 이것 또한 쓰지 않는다.

image에서는 전체 img에서 평균이 되는 img를 빼주거나 아니면 channel별로 mean값을 빼주는 방법이 있다.
이 두 가지 방법 중 후자인 channel의 mean을 빼주는 방식이 더욱 간편하다.

다음은 매우 중요한 weight initalization이다.

만약 모든 가중치를 0으로 초기화시킨다고 가정하자. 이때 생기는 문제점들은 모든 뉴런이 결국에는 동일한 연산을 하게 되고, backpropagation을 통한 gradient값 또한 모두 동일하게 될 것이다. 따라서 이 방법을 사용하게 된다면 symmetry breaking이 발생하지 않는다.

이러한 문제점 때문에 초창기 컴퓨터 과학자들은 random 한 small number로 weight initialization을 진행하였다.

하지만 이 방법은 작은 network에서는 효과적이지만 network가 커질수록 초기화해야 되는 random weight parameter가 많아지게 됨으로 문제가 생기게 된다.

해당 코드를 실행해봄으로써 각각의 layer에서 평균과 표준편차 값을 통해 문제점을 파악해보자
layer는 10개이고, 500개의 뉴런으로 구성되어 있다. 또한 activation function은 tanh를 사용하였다. weitht initailization은 앞 슬라이드처럼 가우시안 정규 분포를 따르는 random 한 값에 0.01를 곱해주었다.

출력된 결과를 보면 각각 layer에 대한 평균은 0으로 잘 수렴하는 모습을 볼 수 있다. 하지만 표준 편차는 급속도로 0으로 수렴하게 되어 결국 histogram을 보게 되면 가운데 쪽으로 몰리는 모습을 볼 수 있다.

이렇게 된다면 결국에 모든 activation은 0으로 수렴하게 되고, gradient도 이에 따라 사라지게 된다.

다음은 random 값에 0.01 대신 1을 곱하였을 때 결과다. 이 경우에는 w의 값들이 너무 커져버려 바로 overshooting이 일어나게 된다. 따라서 histogram을 보게 된다면 -1과 1에 몰리게 되고, 기울기 또한 0이 되어버린다. 이 경우에는 학습을 할 때 loss가 줄어들지 않게 된다.

다음은 xavier initialization을 적용하였을 때에 결과이다. 식을 보면 input의 수가 크면 클수록 많게 되고, 적으면 적게 되는 구조이다. histogram을 보면 잘 분포되는 것을 볼 수 있다.

하지만 xavier 초기화는 relu activation function을 사용하였을 때 문제가 발생한다.

이러한 경우를 해결하고자 he 초기화가 생겼다. 이는 단순하게 2로 나누어주면 된다. he 초기화 방법은 relu에 최적화된 초기화 방법이다.

아직까지도 weight initialization에 관련하여 다양한 연구들이 활발하게 진행 중이라고 한다.

하지만 가중치를 초기화하는 것보다 더 좋은 초기화 방법이 있다. 바로 batch 정규화이다. 이는 학습 과정 자체를 전반적으로 더 안정화시키고, 가속화시킨다. 배치 정규화는 각 layer를 거칠 때마다 x의 값을 각 각 위 식처럼 평균을 빼고, 표준편차로 나누어 normalization 하는 것이다. 이는 정규 분포를 적용하기 때문에 forward path와 backward path에도 문제가 없다.

배치 정규화는 우선 각 N*D로 구성되어있는 input X가 있을 때 X에 대한 평균과 분산을 구하여 정규 분포로 normalize 해준다.

일반적으로 convolution layer와 activation function사이에 위치한다고 한다.

정규화를 시킨 후 다음 단계에서 정규화한 결과들을 다시 조정을 한다. 이 값들은 학습을 하면서 계속 바꾸어준다. 이런 식으로 학습을 통해 batch normalization을 얼마나 할 것인지 결정할 수 있다.

위에서 설명했던 두 가지 단계를 sudo 코드로 간략화시킨 코드이다. batch normalization을 사용하면 gradient flos가 개선되고 빠른 학습이 가능하다고 한다. 그리고 핵심은 초기화에 의지 않아도 된다는 점이다. 왜냐하면 batch normalization자체가 정규화시키는 것이기 때문에 drop out 또한 사용할 필요가 없다.

주의할 점은 train 할 때랑 test 할 때의 과정이 다르다. train 할 때에는 batch를 기준으로 noramalization을 진행하지만 test 할 때에는 전체를 기준으로 normalization을 진행한다. 따라서 학습을 할 때 미리 mean과 variance를 구해야 한다.

다음은 Babysitting the Learning process 즉 의역하자면 학습 과정 관리이다.
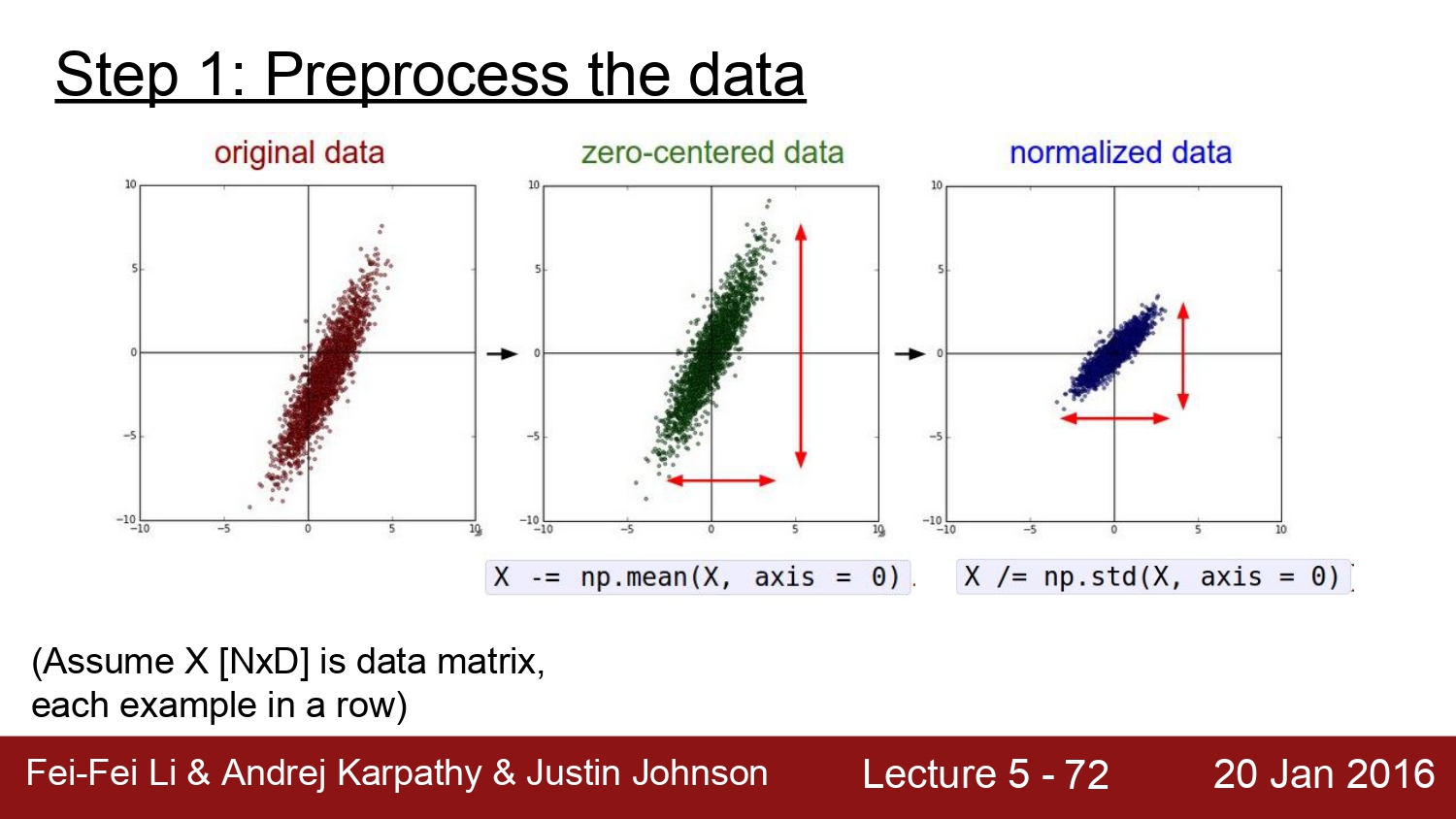
우선 처음은 전처리이다. img에 대해서 zero-centered mean을 진행한다.

다음은 구조 설정이다.

그다음은 시작과 동시에 parity loss를 구하여 loss 값이 제대로 구해지는지 확인하는 과정이다.

그다음에 regularization 설정 후 다시 한번 체크해준다.

그러고 나서 전체 데이터 중 일부 데이터만을 이용하여 체크한다. reg를 0으로 설정해서 데이터를 적게 하여 overfitting이 일어나게 되면 정상적으로 작동하는 것이다.

만약 overfitting이 되지 않는다면 backward path과정이나 learning rate 설정이 잘못되어있는 것이다.

학습 결과를 보면 cost가 거의 변화하지 않는데 이것은 learning rate의 값이 너무 작아 update가 제대로 일어나지 않는다는 의미이다. 만약 lr이 너무 작아서 loss가 줄지 않는데 train과 validation의 정확도가 올라가게 된다면, 그 이유는 처음 score가 defuse 한데 이걸로 start 하면 해당 score가 변화를 할 것이고, lr이 너무 작기 때문에 loss가 변화하지 않는다. 하지만 score에 대해서는 학습을 하긴 했기 때문에 증가한다고 한다. 이런 경우는 일반적인 경우라고 한다.

반대로 lr을 매우 크게 하면 loss는 없어지게 된다.

loss를 보면 너무 커서 lr이 너무 크다는 것을 추측할 수 있다. 결국에는 cross validation 과정을 통해 hyper parameter를 잘 결정해야 한다.

hyper parameter 최적화

시작은 coarse 하게, 마무리는 fine 하게 진행해야 한다. 처음에는 epoch을 적게두어 점점 증가하는 방식으로 진행해야한다.

log space라는 것을 주의해야 한다. log space에서 연산을 하는 이유는 이게 연산에 더 유리하다고 한다.
우선 hyper parameter는 val_acc에서 가장 높은 얘로 설정을 한다. 그다음에 2단계로 넘어간다.

해당 설정된 범위에서 값을 더욱더 좁힌다. 이러면서 val_acc가 높아지는 것을 발견할 수 있다. 여기서는 0.53 정도가 가장 크다.

하지만 여기서도 주의해야 할 점이 있다. -0.3 부분을 보게 되면 다른 것으로 변경해야 할 필요가 있다. 왜냐하면 random search 외에도 grid search라는 방법이 존재한다. 이는 random 하게 search 하는 것이 아니라 모든 범위를 등간격적으로 search를 하는데 매우 비효율적이다.

위 이미지를 보게 되면 오른쪽은 random search, 왼쪽은 grid search이다. 자세히 보면 결국에 찾아내는 점들은 random search가 더욱 효율적으로 찾아내고 있는 모습을 볼 수 있다.

hyper parameter를 찾아내는 방법은 수없이 많다. 교수는 이를 마치 dj가 믹싱 하는 것이라고 비유한다.

fei-fei li는 약 70대의 컴퓨터를 사용하여 적합한 hyper parameter를 찾아낸다고 한다.

hyper parameter는 주로 loss를 모니터링하여 찾아낸다. 위 그래프는 빨간색 줄과 유사할수록 learning rate가 좋은 것을 의미한다.

만약 초기화를 잘못해주면 이러한 경우가 생겨 결국에는 종료될 때까지 loss가 최대로 줄지 않는다고 한다.

정확도 또한 계속 monitoring을 해주어야 한다. loss 같은 경우에는 사람이 해석하기 힘들지만 acc의 같은 경우에는 사람이 해석하기가 쉽다. 사람마다 선호하는 것이 다르다고 한다.
train과 val의 gap이 생기는 이유는 당연하지만 이게 너무 클 경우에는 overfitting을 고려해야 한다. 이럴 때는 regularization strength를 증가해야 한다.

마지막으로 monitoring 해야 할 요소는 w update/w전체 크기이다. 이게 0.001과 비슷해야지 정상적이라고 한다.
referance
http://cs231n.stanford.edu/2016/
https://www.youtube.com/watch?v=KT4iD6yiqwo
'study > cs231n' 카테고리의 다른 글
| Lecture 7: Convolutional Neural Networks (0) | 2020.04.16 |
|---|---|
| Lecture 6: Training Neural Networks, Part 2 (0) | 2020.04.13 |
| Lecture 5-1: Training NN part 1 (~activation function) (0) | 2020.04.13 |
| Lecture 4: Backpropagation and Neural Networks part 1 (0) | 2020.03.25 |
| Lecture 3: Optimization (0) | 2020.03.20 |



