
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- CNN
- SVM hard margin
- DeepLearning
- libtorch
- self-supervision
- svdd
- EfficientNet
- cnn 역사
- darknet
- 데이터 전처리
- pytorch c++
- SVM margin
- 논문분석
- pytorch project
- SVM 이란
- support vector machine 리뷰
- Computer Vision
- yolo
- pytorch
- RCNN
- fast r-cnn
- yolov3
- CS231n
- Object Detection
- Deep Learning
- 서포트벡터머신이란
- TCP
- Faster R-CNN
- computervision
- cs231n lecture5
- Today
- Total
아롱이 탐험대
Lecture 4: Backpropagation and Neural Networks part 1 본문
지난 시간 loss function과 gradient descent에 이어서 설명하겠다.
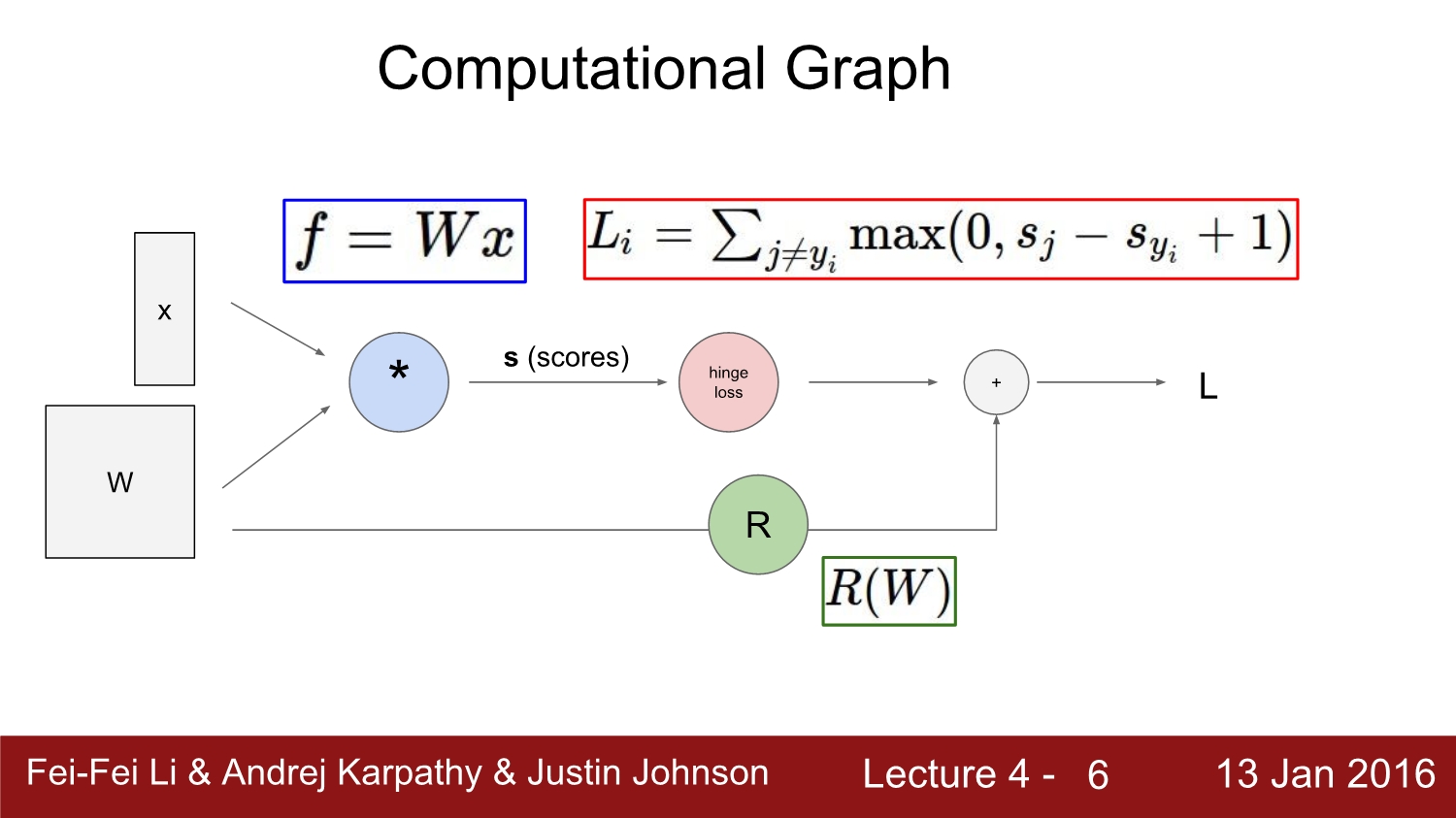
input과 weight를 곱해 bias를 더한 후 loss function을 통과하여 loss를 구하는 과정을 computation graph를 통해 시각적으로 표현하였다.
여기서는 max function을 이용하여 total loss를 구하였다.
computation graph는 눈으로 보기에는 이해하기 쉽고 간단하지만, 계산적인 측면에서는 수만수억 개의 뉴런을 모두 이렇게 계산하기에는 많은 한계점들이 존재한다.
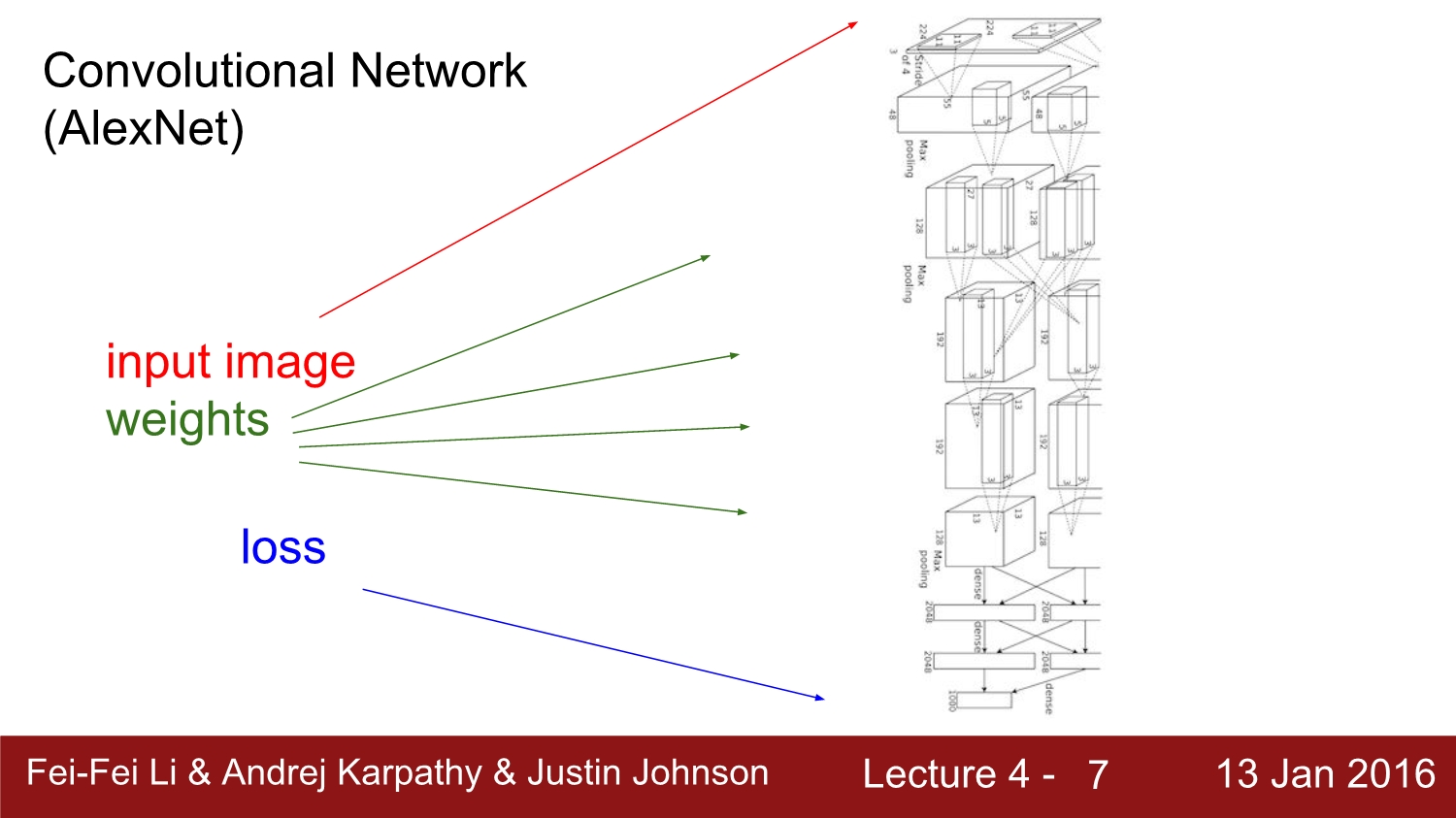
아래는 2020년 기준으로 잘 사용하지는 않지만 유명했던 network들이다.

간단한 예시의 module을 살펴보자. 우선 왼쪽에서 오른쪽 방향으로 가는 것을 FP(forward path)라 하고, 한국어로는 순 전파라고 한다. 우리가 구하고 싶은 건 각각 변수들의 영향력이다. 이를 통해 BP(backward path) 역적파를 구하여 loss를 갱신해야 한다.
우선 더하기는 위 빨간 박스처럼 편미분 후 각각 1이 나오게 되고, 곱하기는 파란색 박스처럼 편미분 후 각 각 위아래 값으로 변하게 된다. 우리가 구하고 싶은 건 df/dx, df/dy, df/dz이다.
이를 구하기 위해서는 chain rule이라는 간단한 법칙을 통해 구할 수 있다.

우선 이 module의 output부분에 해당하는 변화량은 df/df이니 1이다. 이를 chain rule을 통해 df/dy를 구하게 되면 위와 같이 -4가 나온다.

df/dx도 마찬가지로 -4가 나온다. 간단하게 말하자면 +일 때는 그대로, *일 때는 위아래의 노드를 서로 switch 하여 곱해주면 된다.
그리고 위에 예시에서 dq/dx에 해당하는 부분은 local gradient, df/dq에 해당하는 부분은 global gradient로 정의한다.
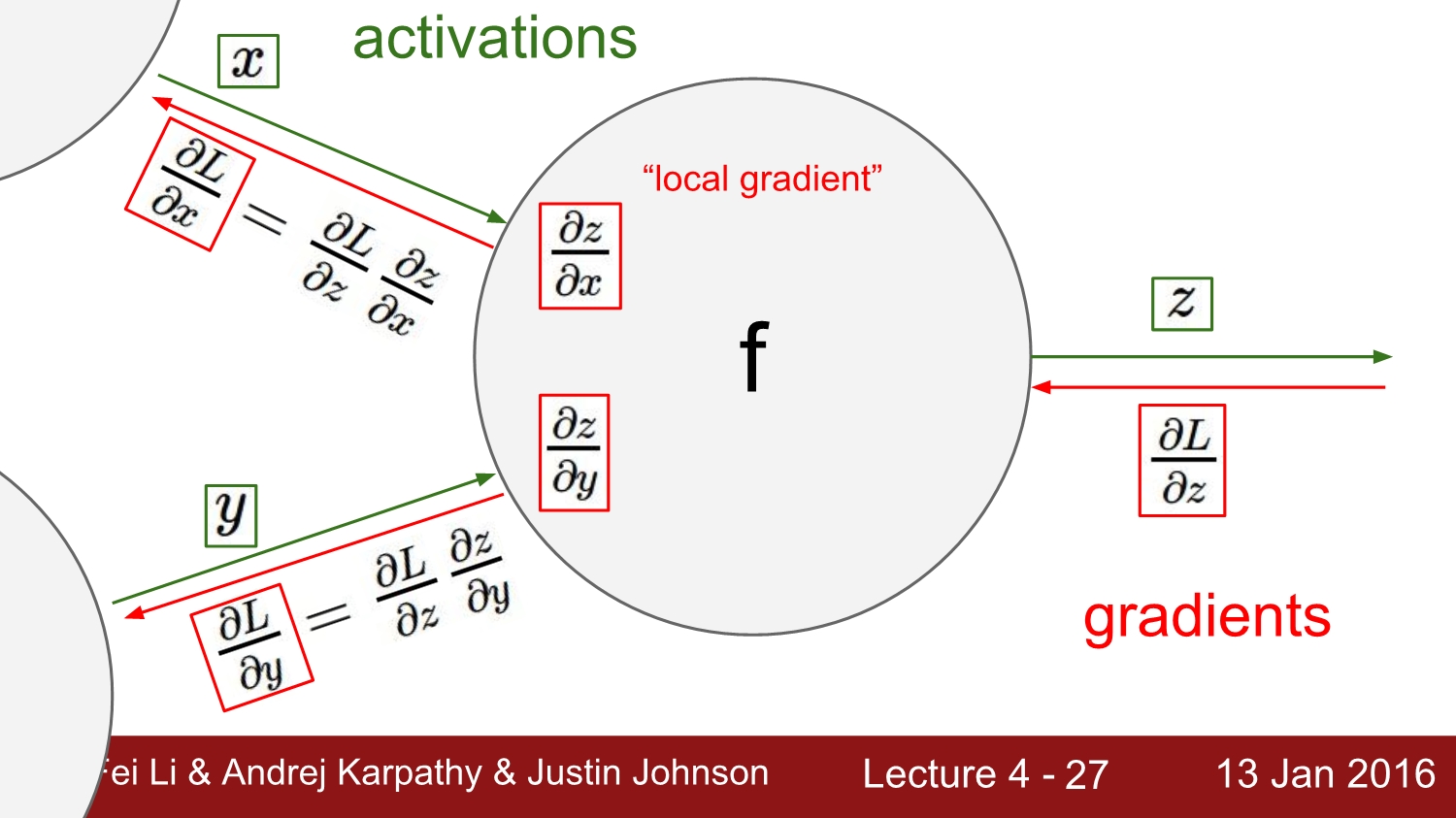
이중 local gradient는 FP를 진행하면서 얻을 수 있다. 따라서 FP를 하면서 memory에 저장을 하고 backpropagation 과정에서 global gradient를 얻으면서 parameter에 대한 gradient를 구하고, 이를 통해 loss를 갱신할 수 있다.
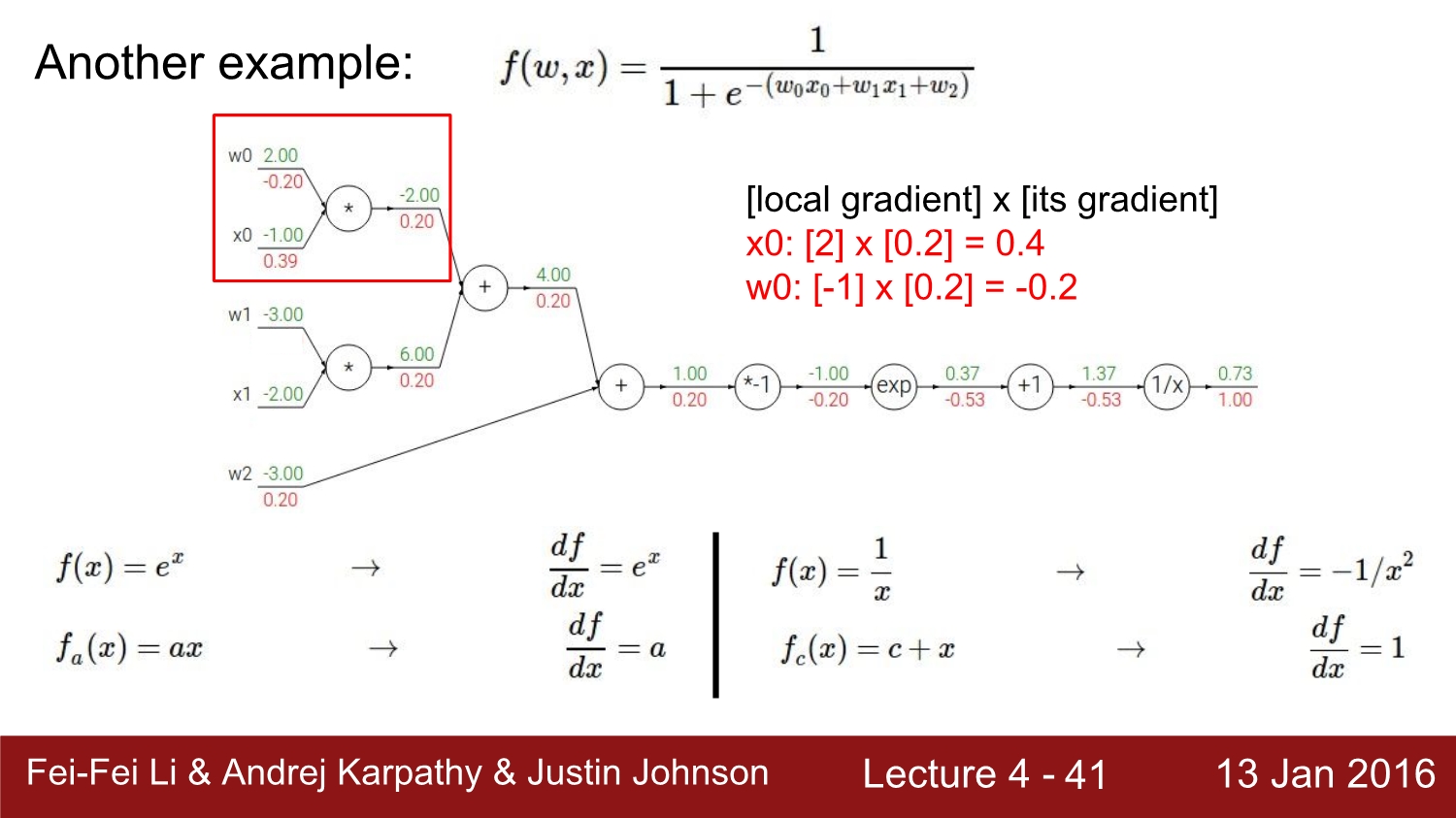
다음은 보편적인 activation function으로 알려진 sigmoid 함수에 대한 backpropagation 계산이다.
우선 아래에 미분식을 정리를 해놓았고, FP를 통해 얻어진 local gradient를 통해 각 parameter의 gradient를 얻었다.
쉽게 생각하면 미분 값에 해당 gradient 값들을 대입하고, +는 그대로, *는 위아래로 바꿔서 곱하면 각각의 값들이 나오게 된다. x0는 0.39는 오타이고 0.4가 정답인 값이다.

하지만 sigmoid는 미분을 하게 되면 위에 있는 식처럼 나오게 된다. 따라서 복잡한 계산과정 없이 한 번에 계산이 가능하다.
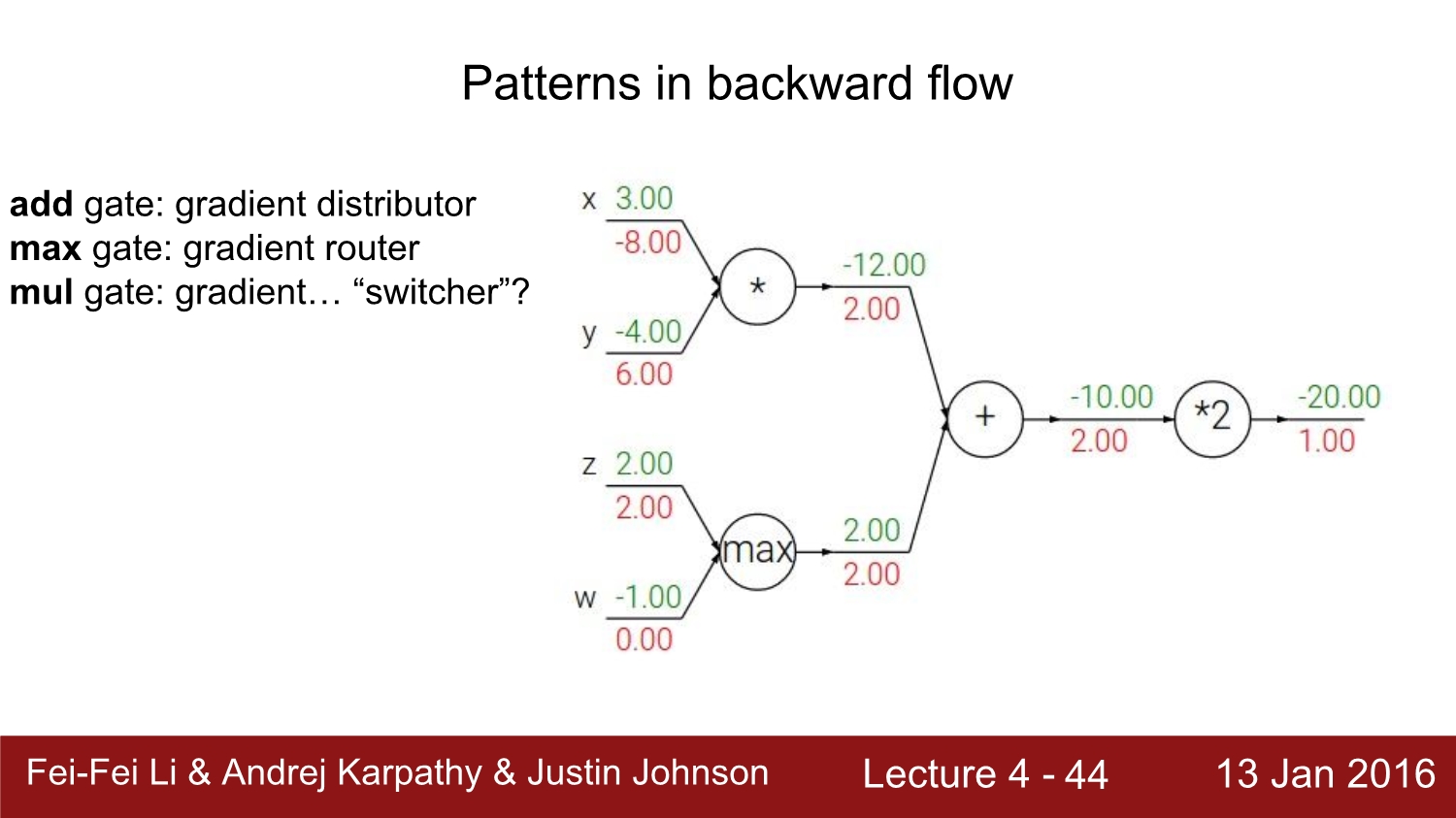
다시 한번 BF를 정리하자면 add는 그대로, mul은 위아래를 바꿔서 곱하고, max는 최대 값은 그대로, 아닌 값은 0으로 처리하면 된다.
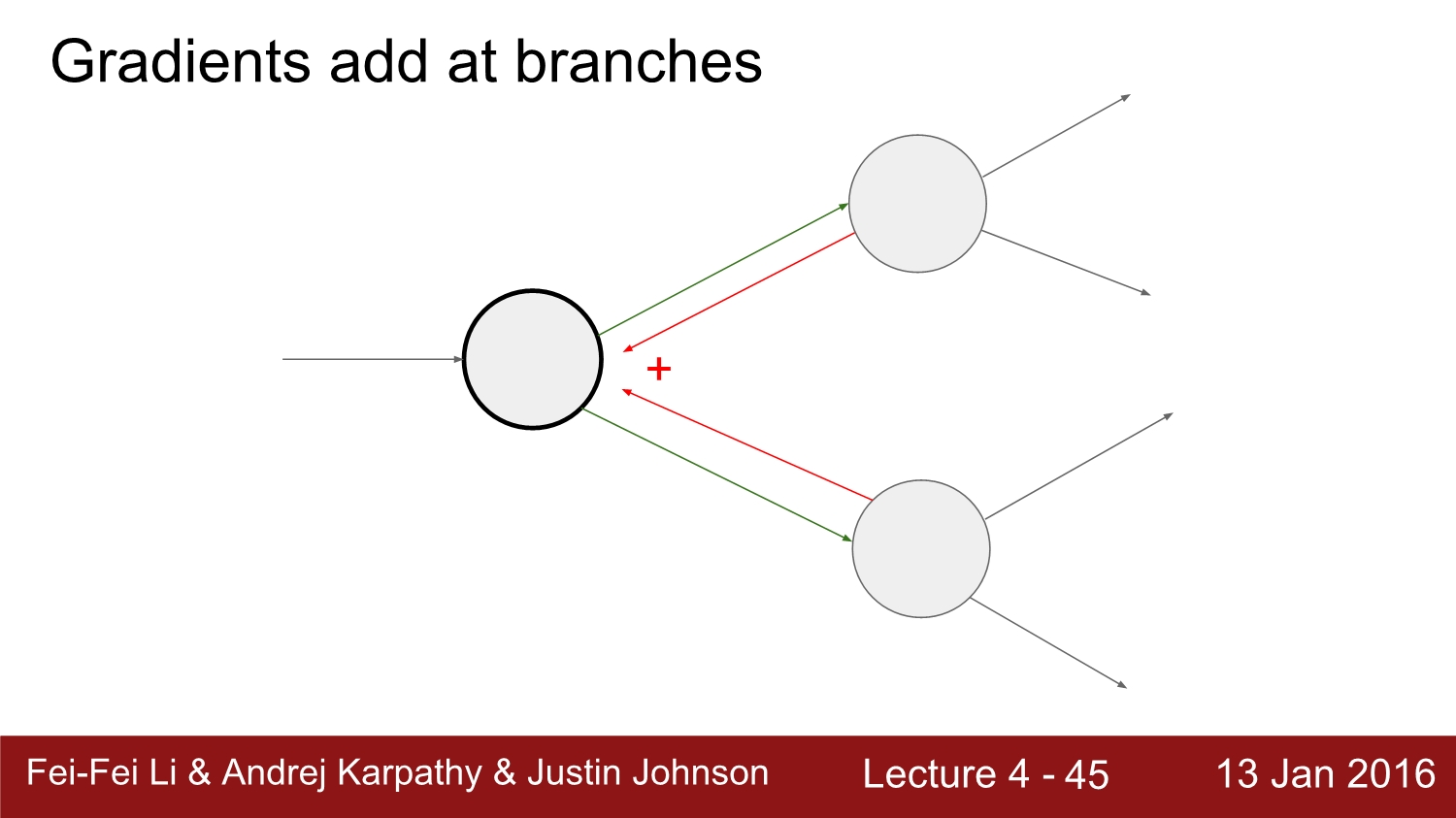
만약 위와 같이 노드가 구성되어 있으면 노드 2개를 더하면 된다.

다음은 python으로 fp와 bp를 구현한 코드다.
forward 과정에서는 우선 각 x와 y에 해당하는 값들을 메모리에 저장 후 z를 return 해준다.
그리고 backward에서 메모리에 저장되어 있던 x와 y를 사용하여 dz를 곱해 준 후 진행한다.



실제로 들어가는 값들은 숫자가 아닌 matrix들이 들어가게 된다.
위 예시는 4096차원 vector가 activation function을 통해 output으로 나온다는 의미이다.
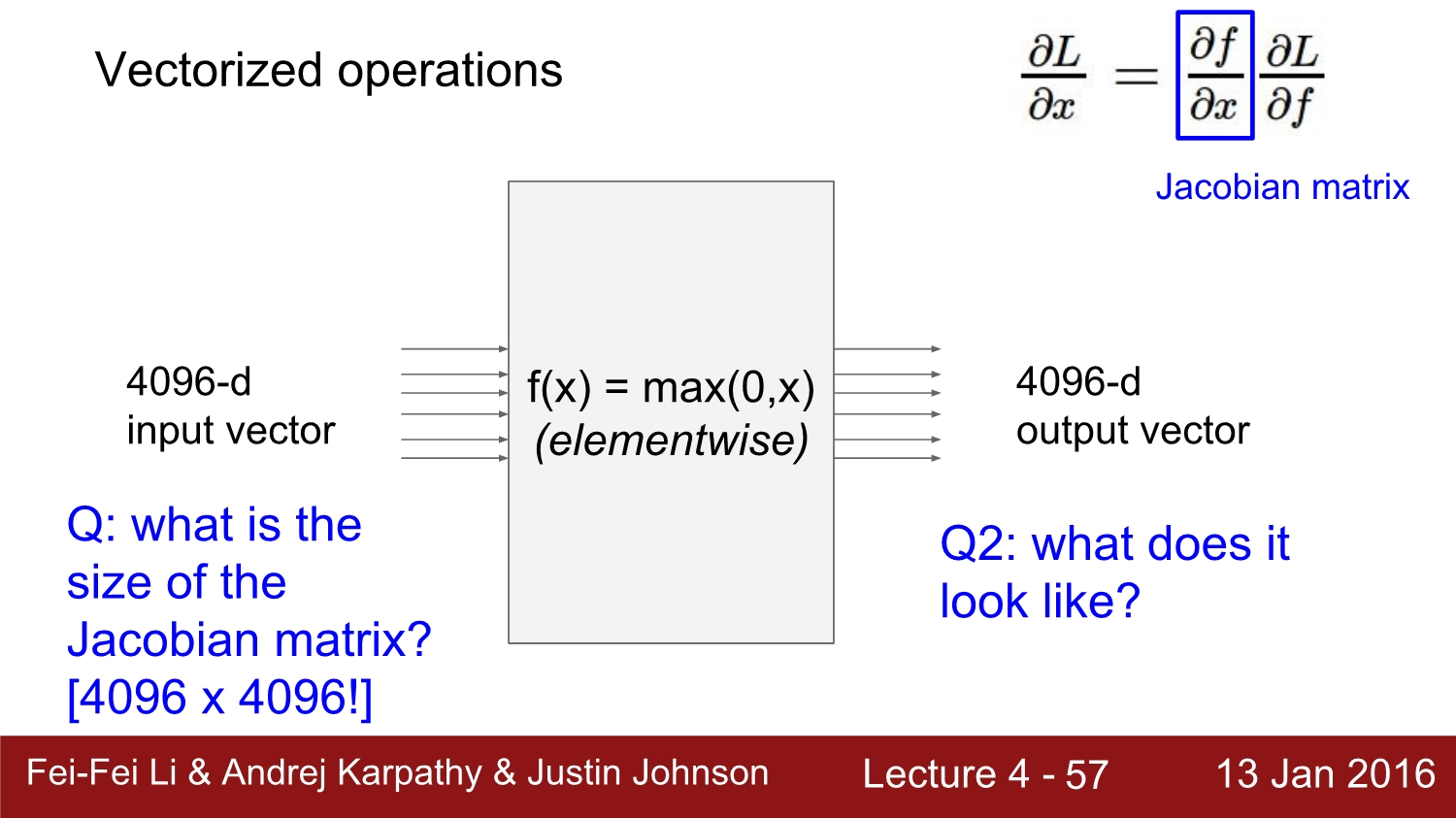
위의 예시처럼 4096*4096을 jacobian matrix를 통해 한번에 loss를 계산을 하게 된다.

하지만 실제로는 mini batch를 사용함으로써 크기가 더욱 커진다. 위 예시는 mini batch size가 100인 예이다.

우리는 이제부터 layer가 1개가 아닌 여러 개의 layer로 구성된 neuron network에 대해 공부를 할 것이다.
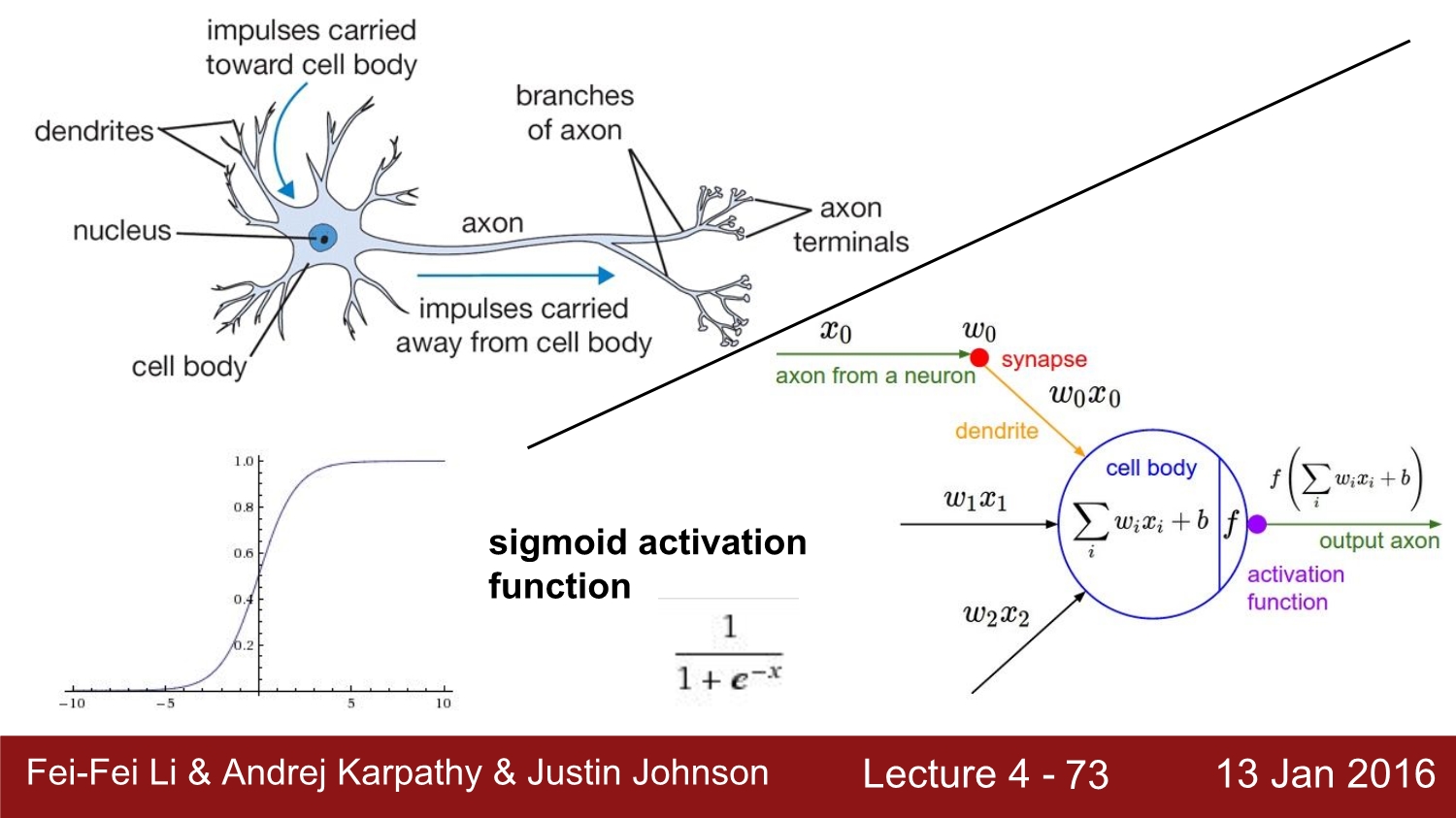
뉴런과 인공 뉴런을 비교한 사진이다. 인공 뉴런은 input과 weight가 곱해진 값을 bias와 합쳐 activation function을 통해 다음 뉴런에게 값을 전달한다.

실제 뉴런과 인공 뉴런을 비교하자면 다른 점이 매우 많다. 우선 생물학적 뉴런은 생물의 종류에 따라 모두 다르고, 훨씬 복잡하다. 그리고 시냅스도 단순한 가중치를 가지는 것이 아니다. 따라서 이런 부분은 조심스럽게 접근해야 한다.

다음은 activation function 모음이다. 당시 기준으로 ReLu를 많이 사용한다고 한다.

뉴런 네트워크의 구조이다. 기본적으로 layer의 개수는 weight를 가지고 있는 layer만 수에 포함시킨다. 따라서 input layer는 개수에서 제외하면서 부른다.
그리고 위 사진처럼 모든 node가 연결되어 있는 layer를 FC(Fully-connected layer)라고 부른다.

각 layer는 sigmoid를 사용하여 간단하게 구현할 수 있다.

layer 층에 따른 분류 능력의 차이이다. layer가 깊어짐에 따라 더욱 분류를 잘하는 것을 볼 수 있다.

하지만 실질적으로는 size가 정규화시키는 것은 아니다. overfitting을 막으면서 일반화를 시켜야 된다.
따라서 reguarize가 잘된 network가 더 좋은 network라고 볼 수 있다. overfitting에 관한 이야기는 다음 시간에 하겠다.
referance
http://cs231n.stanford.edu/2016/
https://www.youtube.com/watch?v=KT4iD6yiqwo
'study > cs231n' 카테고리의 다른 글
| Lecture 6: Training Neural Networks, Part 2 (0) | 2020.04.13 |
|---|---|
| Lecture 5-2: Training NN part 1 (~Data preprocessing) (0) | 2020.04.13 |
| Lecture 5-1: Training NN part 1 (~activation function) (0) | 2020.04.13 |
| Lecture 3: Optimization (0) | 2020.03.20 |
| Lecture 2: Image Classification pipeline (0) | 2020.03.19 |



