
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- EfficientNet
- SVM hard margin
- TCP
- pytorch c++
- cnn 역사
- yolov3
- libtorch
- yolo
- DeepLearning
- SVM 이란
- Object Detection
- self-supervision
- pytorch project
- Computer Vision
- fast r-cnn
- CS231n
- svdd
- SVM margin
- Deep Learning
- pytorch
- cs231n lecture5
- support vector machine 리뷰
- darknet
- 논문분석
- Faster R-CNN
- 서포트벡터머신이란
- RCNN
- computervision
- CNN
- 데이터 전처리
- Today
- Total
아롱이 탐험대
Lecture 6: Training Neural Networks, Part 2 본문

지난 시간에 이어 Neuroal network의 학습 과정에 대해서 더욱 자세히 알아보자. 앞부분은 지난 수업의 복습이니 생략하겠다. 만약 기억이 안 나면 이전 포스팅을 보고 오길 바란다.

파라미터 업데이트에 관해 알아보자

뉴런 네트워크에서 training을 거치는 과정은 이런 과정으로 진행되고 마지막 줄과 같이 learning rate와 dx를 곱해 parameter update가 진행된다. 이러한 방법을 SGD 또는 경사 하강법이라고 부른다. 하지만 SGD는 갱신 속도가 매우 느려서 실제에서는 사용되지 않는다.

우리가 빨간색 행성에서 가운데에 위치한 행성으로 간다고 가정하자. SGD에서는 수직으로는 경사가 급하고, 수평으로는 얕다 따라서 가운데로 움직이는 벡터는 수직으로는 빠르게, 수평으로는 느리게 진행한다. 따라서 이렇게 지그제그로 매우 느리게 이동하게 된다.

SGD를 개선하고자 나온 방법이 Momentum이다. 여기에서는 속도를 의미하는 v 변수를 도입한다. 이것은 1번 update한 후 x의 위치를 v를 통해 update 해주는 방식이다. 쉽게 설명하자면 언덕에서 공을 굴린다고 생각하면 된다. 또한 여기서 나온 mu는 마찰계수인데 이를 통해 굴러가는 속도가 점점 느려지게 된다. 이는 hyper parameter로 보통 0.5, 0.9~0.99로 설정한다고 한다. 초반에는 0.5로 설정해주고 점점 마찰 계수를 올리는 방식으로 hyper parameter를 결정한다.

위에서 설명했던것과같이 마치 추가 흔들리는 것처럼 수렴한다.
하지만 Momentum은 속도라는 개념을 집어넣은 만큼 초반에는 overshooting이 발생해 처음부터 정확한 값으로 도달하기는 힘들다. 하지만 SGD보다는 갱신 속도가 훨씬 빠르다.

그다음은 momentum을 개선한 Nesterov Momentum update다. 이는 momentum보다 더 좋은 방법이라고 증명이 되었다고 한다. momentum은 2 step(momentum step, gradient step)으로 나누어지는데 이에 반해 nesterov는 momentum step이 이동하는 예상지점을 gradient step으로 둔다. 따라서 최종적인 벡터의 방향도 달라지게 된다.
이 두가지 방법의 차이는 뮤의 존재 유무이다.

하지만 nesterov에서 불편한 점이 있는데 이는 바로 theta이다. 왜냐하면 forward path, backward path과정에서 theta와 해당 위치에서 gradient를 구하게 되는데 nesterov 같은 경우에는 theta와 다른 위치에 있는 gradient를 요구한다. 따라서 호환성이 떨어져 결국에는 정확도 측면에서도 떨어지게 된다.
따라서 1번째 파란색 박스에 있는 식을 2번째 파란색 박스에 있는 식으로 보완해준다.
이러한 형식을 vanilla update 형식이라고 한다.
결론적으로는 nesterov는 방향을 미리 예측하고 목적지에 가기 때문에 momentum보다 속도가 훨씬 빠르다.

다음은 AdaGrad이다. 여기서는 cache라는 새로운 개념을 도입한다. 차이점은 cache의 root를 씌어준 것을 나눠주는 것이다. 특징은 모든 parameter들이 각각 다르게 learning rate를 적용받는다.

이렇게 adagrad를 적용하면 수직 축 같은 경우에서는 속도를 줄여주고, 수평축 같은 경우에는 속도를 높여준다.

하지만 adagrad에서도 문제점이 있다. step size가 시간이 흐르면서 cache의 값이 증가되고, learning rate는 결국에는 0으로 수렴하게 된다. 이는 프로그램이 종료되는 것이고 즉 학습 과정이 예상치 못하게 일찍 종료될 수 있다.

adagrad를 보완하고자 나온 것이 RMSprop이다. 이는 decay_rate라는 것을 도입하였다. 원래는 cache를 구성할 때에는 gradient의 제곱으로 구하지만 RMSprop에서는 위와 같이 식을 수정해준다. RMSprop는 이를 통해 adagrad의 단점이었던 step size가 0이 되어버리는 현상을 막아준다.

여기서 재미있는 사실은 RMSprop은 정식적으로 paper에서 나온 것이 아니라 인공지능에서 가장 유명하신 교수님인 Hinton 교수님께서 수업시간에 "내가 연구해보다가 이렇게 했는데 더 잘되더라"라는 발언에서 나온 개념이어서 다른 paper에서 reference 될 때는 위와 같이 그냥 이야기에서 나왔다고 서술한다.

다음은 Adam update 방법이다. 이는 momentum과 RMSProp을 합친 것과 유사하다. 여기서 VECTOR v는 hyperparameter이다.
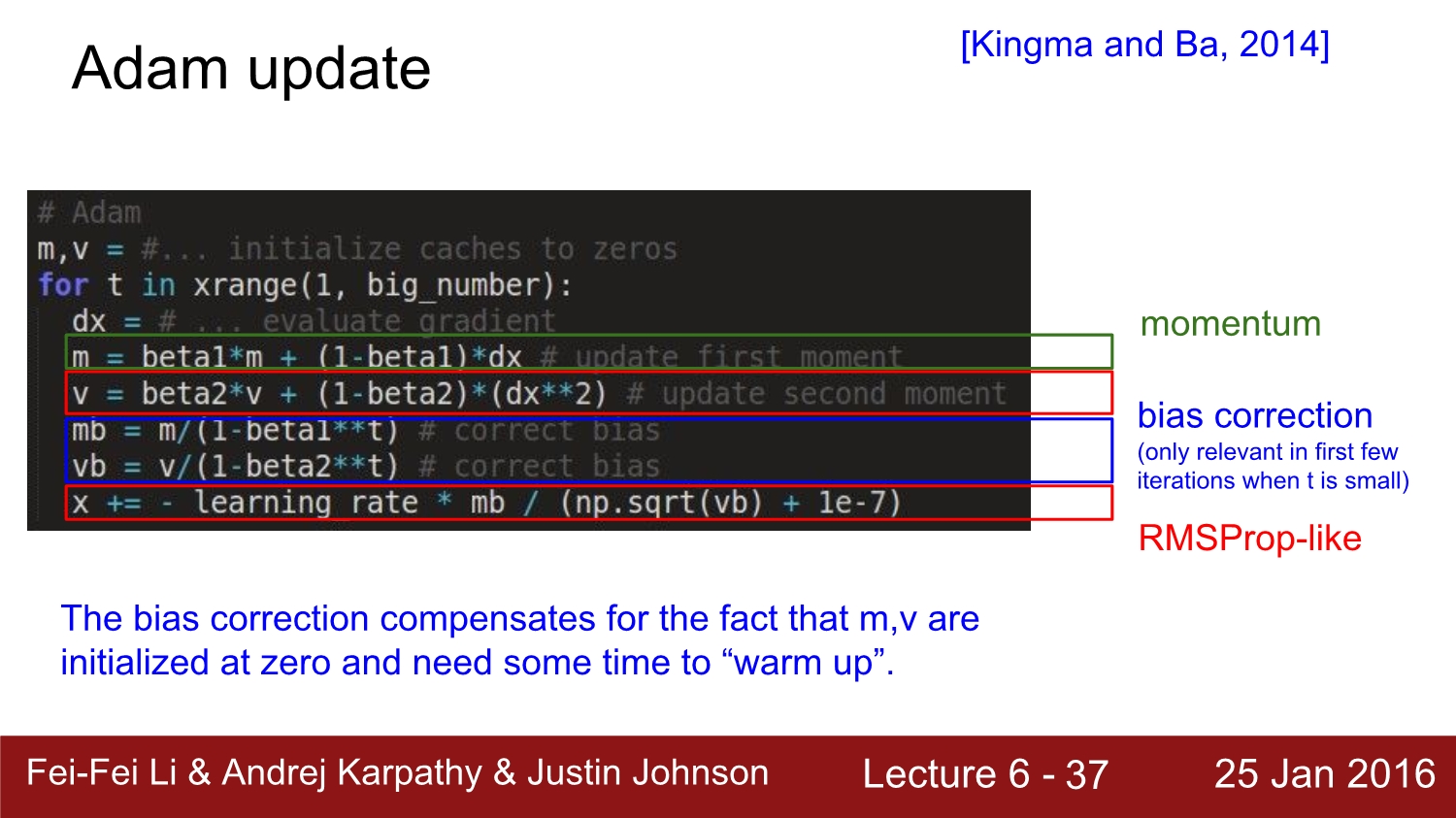
이것이 adam의 최종적인 형태이다. 역기서 bias가 있는데 이는 초기 값이 0일 때 scale up 해주는 역할을 한다.

여기서 과연 어떤 learning rate를 사용하는 것이 좋을까? 정답은 존재하지 않는다. 왜냐하면 lr은 시간의 경과에 따라서 변경해주는 것이 가장 좋다.

여기서 step decay는 epoch에 따라 learning rate를 변경해주는 것을 의미한다. 종류가 3가지가 있는데 현실에서는 exponential decay를 가장 많이 쓴다고 한다. 그리고 default parameter update method는 adam을 사용한다.
여기서 loss function을 구하는 데 있어 gradient만 구하면 이를 1st order method라고 한다.

이 와달리 2nd order는 hessian을 구해서 경사뿐만 아니라 이 곡면이 어떤 형식으로 구성되어 있는지 알 수 있다. 이 경우는 학습할 필요 없이 바로 최적점으로 갈 수 있다는 장점이 존재한다. 이러면 learning rate도 구할 필요가 없다. 수식에 대한 내용은 수업에서 생략하였다. 장점은 속도가 빨라지고, hyperparameter를 구할 필요가 없어지는 것이다. 하지만 second order는 deep 한 network에서는 현실적으로 사용할 수 없다고 한다. 그 이유는 해당 크기의 행렬과 역행렬이 필요하기 때문에 메모리 소비뿐만 아니라 연산량도 매우 많아진다.

second order optimization으로 유명한 method는 2가지가 있다. 우선 BGFS는 rank 1에 hessian을 집어넣음으로써 second order를 시행한다. 하지만 여전히 메모리에 대해 문제가 존재한다.

L-BFGS에서 보완을 하였는데 모든 noise를 다 제거하는 방법이다. 이는 full batch에서는 잘되지만 mini batch에서는 잘되지 않는다고 한다. 요즘 연구 동향을 따르면 거의 대부분은 mini batch로 더욱 효율적으로 training을 하기 때문에 L-BFGS도 잘 쓰이지 않을 것 같다.

정리를 하자면 default optimizer는 Adam을 쓰고, 만약 full batch 방식으로 train을 할 거면 L-BFGS도 쓸 수 있다.

다음은 Ensemble에 대해 알아보자

단일 모델 대신 여러 종류의 독립적인 모델을 학습시킨 후 test 때 이들의 평균을 내준다. 그러면 성능이 약 2% 더 향상된다고 한다.

앙상블이 이해가 잘 되지 않아 구글에 검색해본 결과 위처럼 병렬적으로 같거나 다른 data set으로 학습시킨 독립의 model들을 combiner로 합친 후 test과정에서 이들을 모두 합쳐 평균의 결괏값을 도출해낸다고 생각하면 된다. 이는 전문가 여러며 이이 모여 회의를 한다고 비유한다.
물론 단점도 존재하는데 여러 모델을 관리해야 하는 점, 평균값을 구하려면 linear 하게 속도가 느려지는 점들이 있다.

또한 다른 tip은 단일 모델 내에서 train 할 때 각 epoch마다 해당 check point 간 앙상블을 하더라도 성능이 향상된다고 한다.

또한 parameter vector들도 앙상블을 적용하면 성능이 향상된다. 예를 들어 우리가 bowl처럼 생긴 함수를 가지고 있으면 우리는 step size가 너무 커져버려 목적지를 지나치게 된다. 하지만 step size 대신 평균만큼 가게 된다면 목적지에 훨씬 더 효율적으로 도달하게 되고 이는 성능이 향상된다는 의미이다.

다음은 regularization 기법 중 하나인 dropout이다. drop out은 2012년 alex net에서 사용되었으며, 전에 언급했던 것처럼 이때부터 deep learning의 시대가 찾아왔다.

drop out을 적용하게 되면 일부 랜덤 한 node들을 0으로 설정한다.

위 코드를 살펴보면 np.random을 통해 일부 노드들을 2개의 masking을 통해 0으로 설정한다. forward path뿐만 아니라 backward path에서도 fowardpath에서와 같은 노드를 dropout 시키면서 train을 진행해야 되고, node를 drop할 뿐만아니라 drop connect라고 weight 자체를 drop 하는 기법도 존제한다.

drop out의 장점은 무엇일까? 1번째는 노드가 중복성을 갖게 하는 것이다. 예를 들어 고양이 사진을 인식하는 노드들이 있다고 가정하자. 각각의 노드들은 귀, 꼬리, 피부 등 서로 다른 부위를 인식한다. 여기서 만약 귀, 피부가 인식이 되지 않았지만 다른 노드에서는 인식이 되면 이 이미지를 고양이라고 인식할 수 있을까? drop out은 각 노드들의 역할을 서로 중복성 있게 만들어줌으로써 인식률을 더 높인다.

또 다른 장점은 서로 가중치를 공유하여 평균치를 내는 방법이 마치 앙상블 효과와 비슷하다는 해석이 존재한다.

dropout은 test시에는 절대로 사용하면 안 된다. 효율성이 매우 떨어진다고 한다.

그 이유는 test time 때 x라는 output을 얻었다고 하자. 만약 p가 0.5일 때 우리가 얻을 수 있는 기대치는 몇일까?

정답은 총 4개의 경우의 수가 존재한다. 계산에 의하면 결국에는 1/2가 나오게 되고 p와 동일한 값이 된다. 2배가 더 비효율적으로 된 모습을 볼 수 있다.

이제부터는 본격적으로 CNN에 대해 알아보자

역사적으로 CNN을 보았을 때 1959년 Hubel & Wiesel이 생명 공학 관련 연구로 노벨상을 받게 된다. 연구의 간략한 내용은 고양이가 특정한 물체를 봤을 때 시신경으로부터 흥분을 받아들이는 것에 대한 대뇌 신경 실험이다. 물체의 방향이 달라지면 그래프가 요동친다. 이는 특정 뉴런은 특정 방향에 반응한다는 의미다.

또 다른 발견은 각 cortex에서 근접한 shell은 지역성을 띈다는 사실이다.

locality가 유지된다는 점은 high level로부터 low level까지 나뉜다. 이러한 내용을 바탕으로 컴퓨터 공학에서 이와 비슷하게 실험을 하였다.

이는 1980년 후쿠시마에 의한 neurocognitron 구조이다. 이 당시에는 backpropagation이 불가능하였다.

이후 1998년 이것이 실용화가 된다. 이 당시에는 우편물의 zip code를 분류하면서 기계학습으로 사람의 일을 대신 진행하였다. 이 당시에는 backpropagation이 가능하였다.

그 이후 CNN이 가장 큰 발전을 한 것은 2012년 Image net을 우승한 AlexNet 덕분이다. 이때부터 딥러닝 학습을 이용한 컴퓨터 비전이 발전하였다. 재밌는 사실은 Le-net과 구조상 차이가 별로 없지만 activation function, data의 양, weight initialization, batch normalization, 네트워크의 깊이 등 많은 요인이 있다.

그 이후 CNN은 classification, retreval, object detection 등 다양한 분야에서 활용되었다.











주목해야 되는 사실은 2013년에 원숭이와 동일한 수준까지 왔고, 현재는 CNN이 사람을 뛰어넘었다.

실험에 의하면 원숭이와 alex net 둘 다 각 뉴런의 인식이 비슷하게 나타났다. 즉 CNN이 사람만큼 또는 사람 이상이 될 수 있는 이유이다.
referance
http://cs231n.stanford.edu/2016/
https://www.youtube.com/watch?v=KT4iD6yiqwo
'study > cs231n' 카테고리의 다른 글
| Lecture 8: Spatial Localization and Detection (0) | 2020.04.17 |
|---|---|
| Lecture 7: Convolutional Neural Networks (0) | 2020.04.16 |
| Lecture 5-2: Training NN part 1 (~Data preprocessing) (0) | 2020.04.13 |
| Lecture 5-1: Training NN part 1 (~activation function) (0) | 2020.04.13 |
| Lecture 4: Backpropagation and Neural Networks part 1 (0) | 2020.03.25 |



