
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- SVM 이란
- yolo
- Deep Learning
- self-supervision
- cnn 역사
- svdd
- Computer Vision
- TCP
- libtorch
- RCNN
- cs231n lecture5
- CS231n
- pytorch c++
- fast r-cnn
- 데이터 전처리
- support vector machine 리뷰
- Object Detection
- darknet
- 서포트벡터머신이란
- Faster R-CNN
- SVM margin
- DeepLearning
- 논문분석
- computervision
- yolov3
- pytorch project
- SVM hard margin
- pytorch
- CNN
- EfficientNet
- Today
- Total
아롱이 탐험대
Lecture 5-1: Training NN part 1 (~activation function) 본문

지난 시간에 이어서 lecture 5를 살펴보자

우선 수업을 시작하기 전 실전에서 train을 어떻게 하는지에 대해 설명을 하였다.
CNN을 train하려면 가장 필요한 건 막대한 데이터이다. 하지만 이 데이터들을 구하기도 힘들도 구했다 해도 train과 test 하는데 오랜 시간과 비용이 필요하다. 따라서 tensor flow, pytorch 같은 deep learning 모듈에서는 기본적인 finetuning 된 학습된 파라미터를 제공한다. (github이나 다른 사이트에서도 찾기 쉽다.)
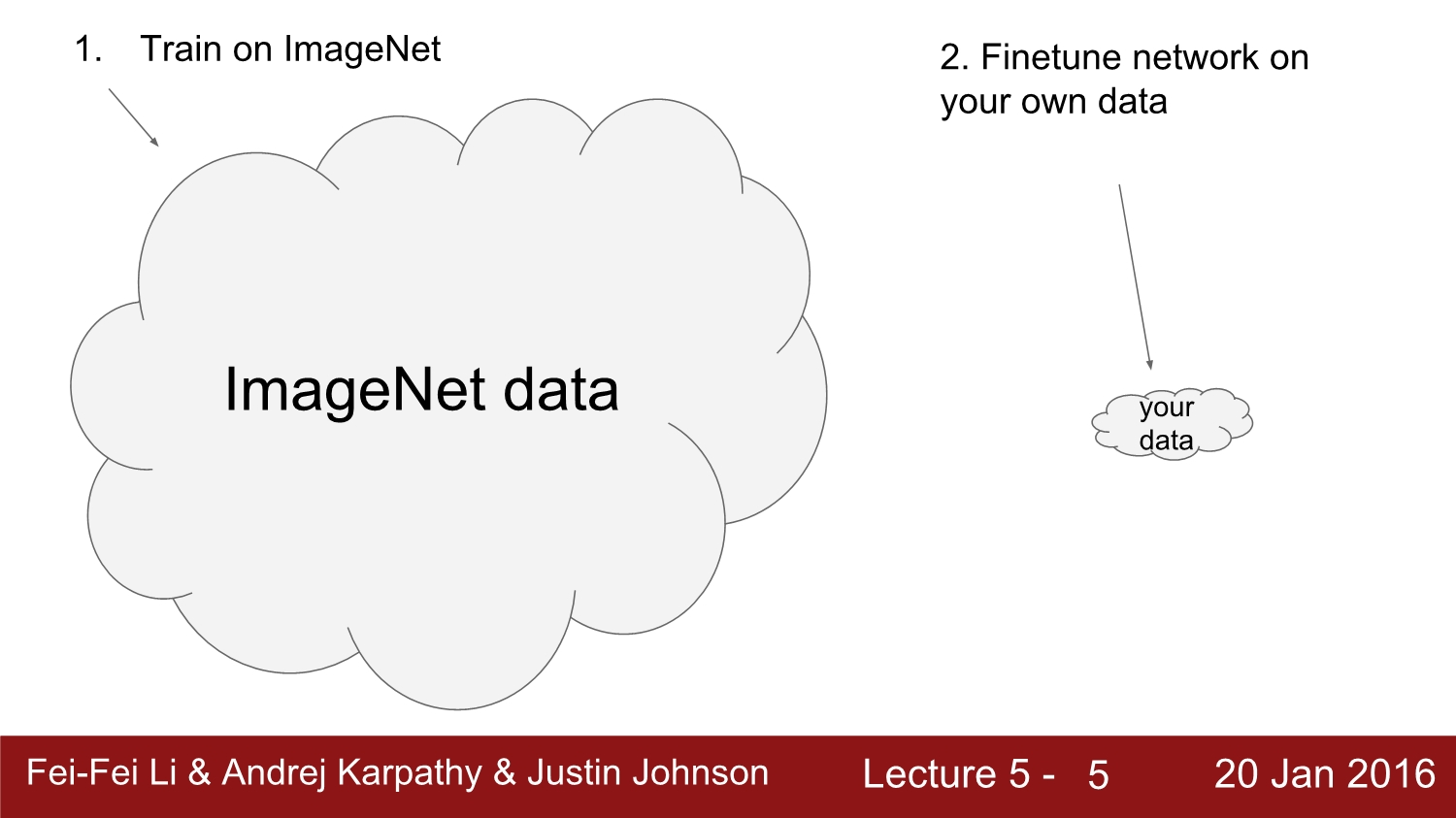
따라서 우리가 가진 데이터는 너무 적은데, 우선 image net이라는 open data 웹사이트에 접속하여 image net data를 기반으로 학습을 시킨다. 그 후 우리가 가지고 있는 소량의 데이터로 fine tuning을 한다.
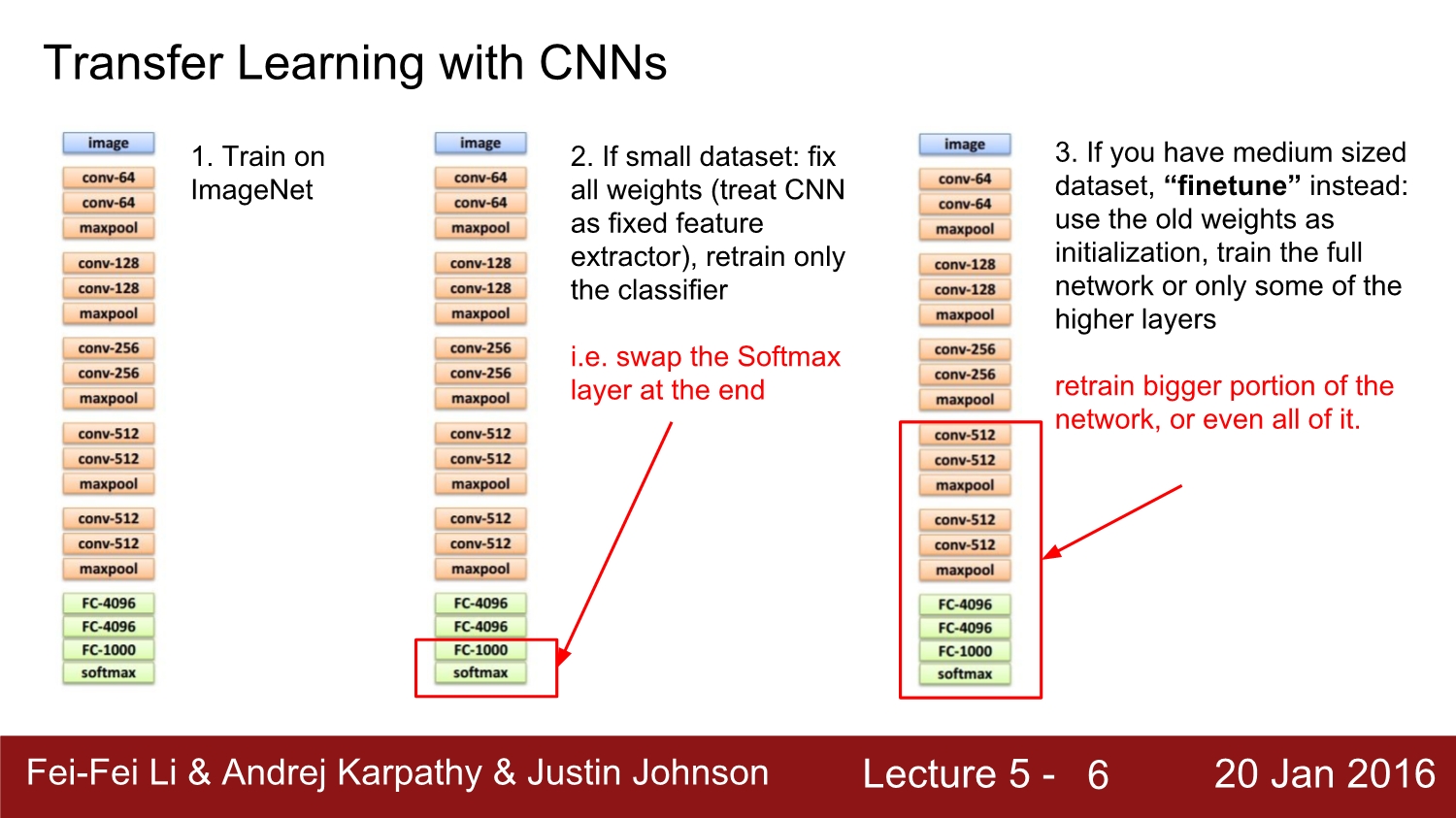
만약 우리의 data set이 소량이라면 기존의 학습한 data set을 고정하여 train한다. 그 후 과정은 크게 2가지로 나뉜다.
우선 첫번째 방법은 기존에 다른 data set으로 학습한 weights를 우리의 새로운 model의 initailization weight로 사용한다. 그 후 마지막 loss function이 속해있는 layer에서만 우리의 data로 다시 학습을 시킨다.
두 번째 방법은 앞단은 fix를 하고 아래쪽 layer에서만 우리의 data를 가지고 학습을 한다. 이 방법은 data의 양이 일정 수준 이상이 여야지 가능하다. 기존 가중치를 가지고 초기화하여 전체를 다시 학습시켜도 되고, 아니면 앞서 설명했던 것처럼 끝에서 일정 부분만 학습시켜도 된다.
대부분의 경우에서는 기존 가중치를 기반으로 finetuning을 시킨다고 한다.
본인도 이 방법을 cs231n 수업을 들으면서 처음알았다. 현재까지는 그냥 처음부터 train을 시켰는데 다음 프로젝트에서는 finetuning 방법을 시도해야 되겠다.

너무 무리하게 많은 데이터를 train 하지 말라는 내용이다.

이제 본 수업에 들어가기 전 간단하게 Neural network의 역사에 대해 알아보자. 물론 중요한 내용은 아니지만 유익하고, 뉴런 네트워크가 힘든 과정을 통해 지금에 모습을 이룬 것을 알 수 있다.

NN (neuron network)의 시초는 1957년 퍼셉트론으로 거슬러 올라간다. 당시 Mark 1이라고 불린 machine은 서킷 기반의 하드웨어였다. 그 당시 activation function은 0과 1인 이진으로 되어 있어 미분이 불가능해 backpropagation이 안되었다고 한다.
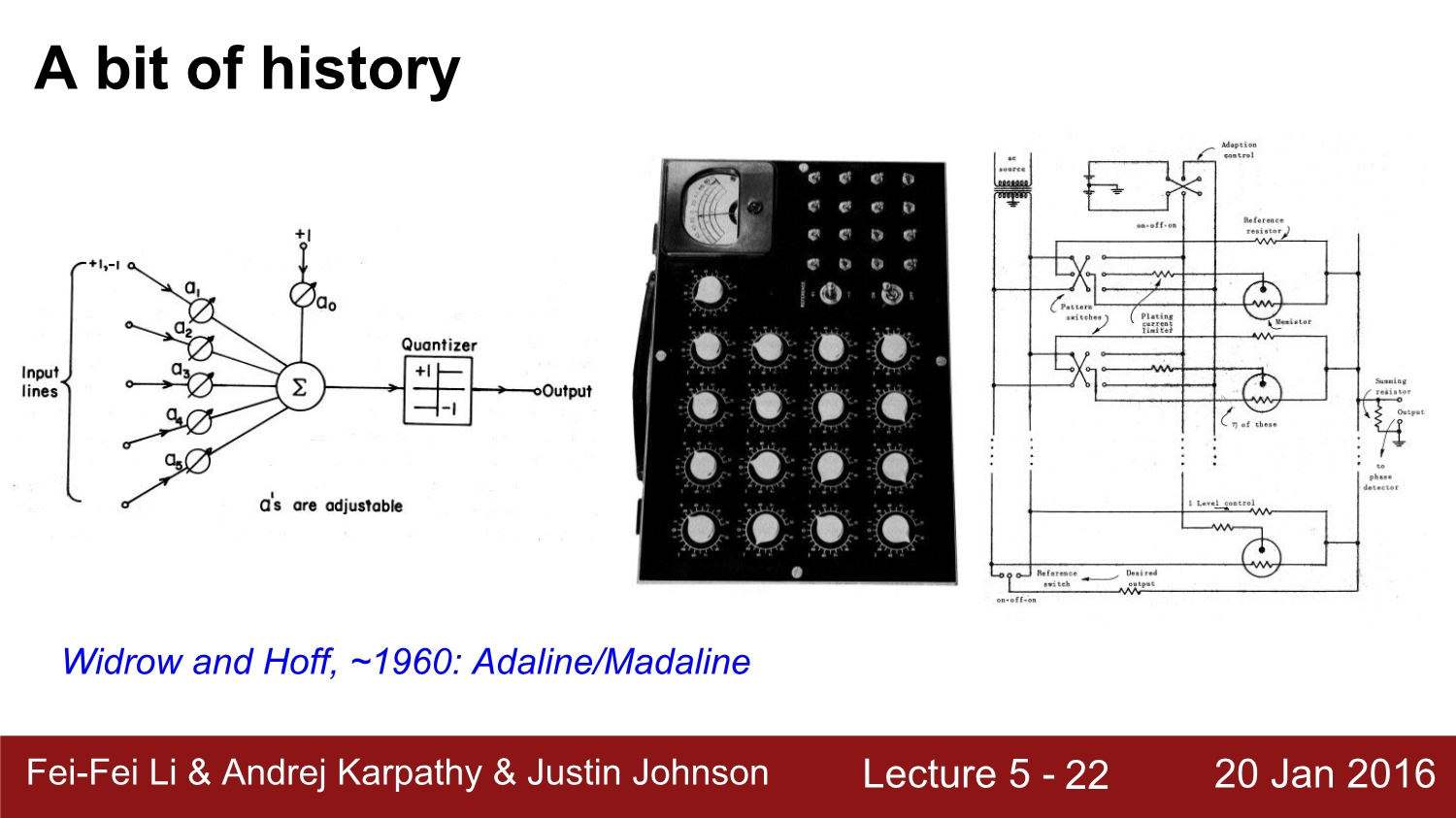
그 후 1960년대에는 perceptron을 겹겹이 쌓는 구조를 시도하였다. 하지만 이 당시에도 미분이 불가능하였다.
이때부터 1980년대까지 인공 신경망의 첫 번째 정체 기하고 한다.
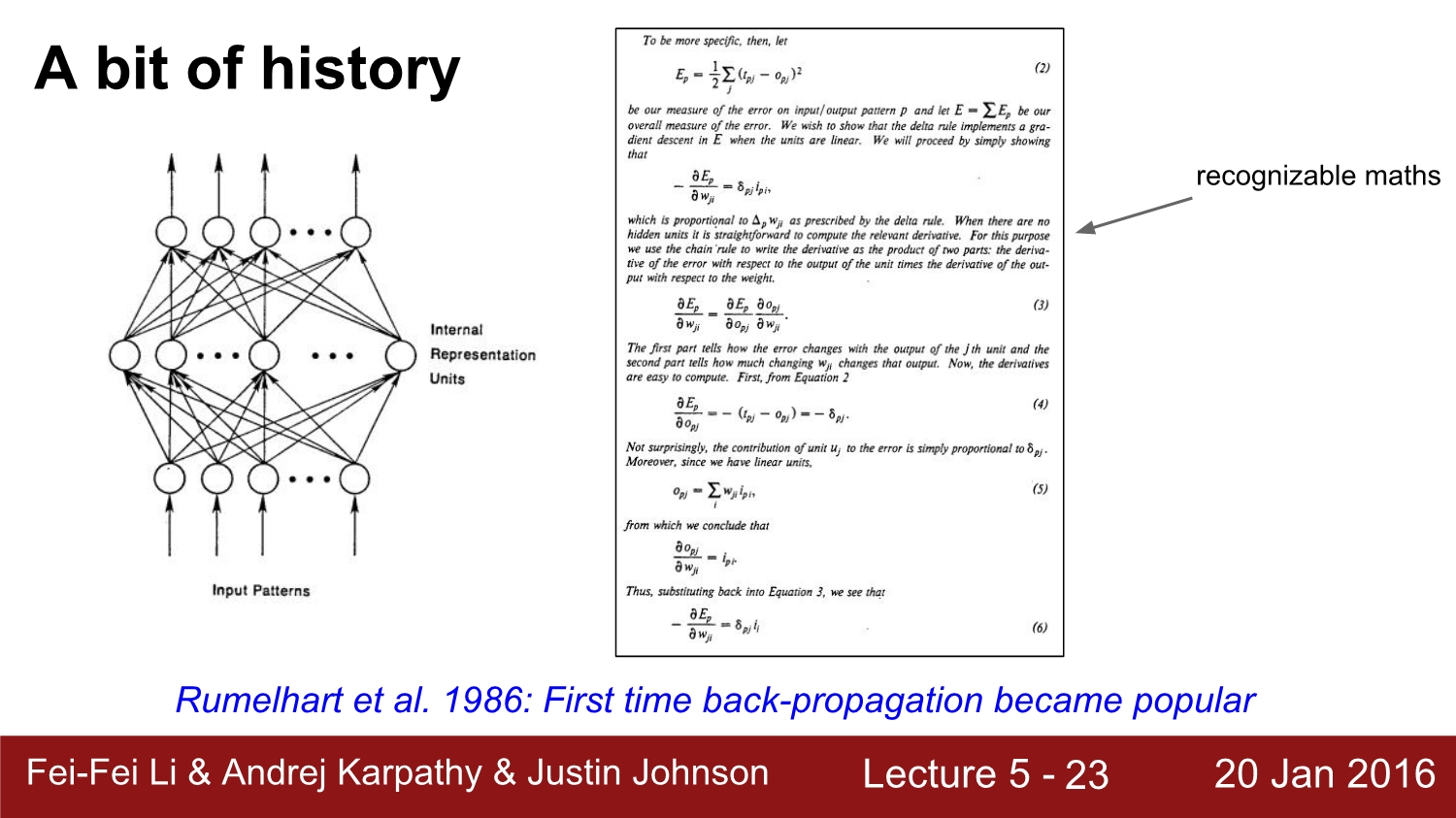
1986년 최초로 BP (backpropagation path)를 시도하여 성공하였다. 하지만 network가 커지고 깊어질수록 연산량이 매우 많아져 그 당시 hardware 기술로써는 불가능하였다. 이때부터 2000년대 중반까지 인공 신경망의 제2의 암흑기라고 한다.
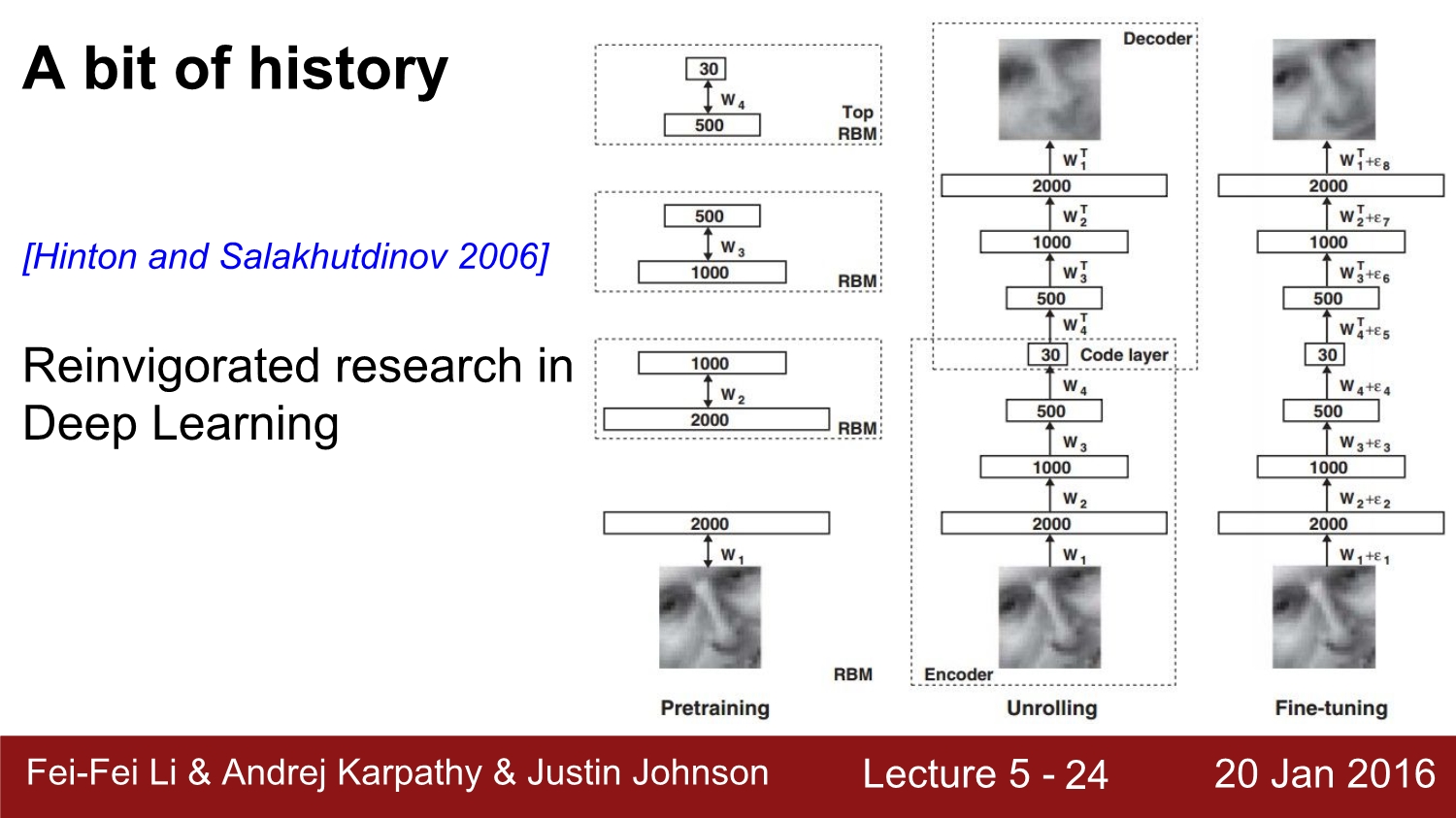
2006년에 이러서야 약 20년 만에 BP 과정이 제대로 동작하는 것이 가능하였다. 이때는 RBM을 이용하여 별도의 pretraining을 하였다. 각 단계에서 RBM을 이용하여 그다음의 module로 전달하는 방식이다. 이다음 단계에서는 이들을 1개의 큰 덩어리로 묶었고, 다음 단계에서 이들을 fine-tuning을 진행하였다.
하지만 나중에 연구에서 밝혀진바로써는 이럴 필요가 없었다고 한다. 왜냐하면 우선 weight initialization 과정이 문제가 있었고 또한 sigmoid function을 사용한 것도 문제였다.
이때부터 NN의 연구가 활성화되었고, deep learning의 시작이라고 할 수 있다.
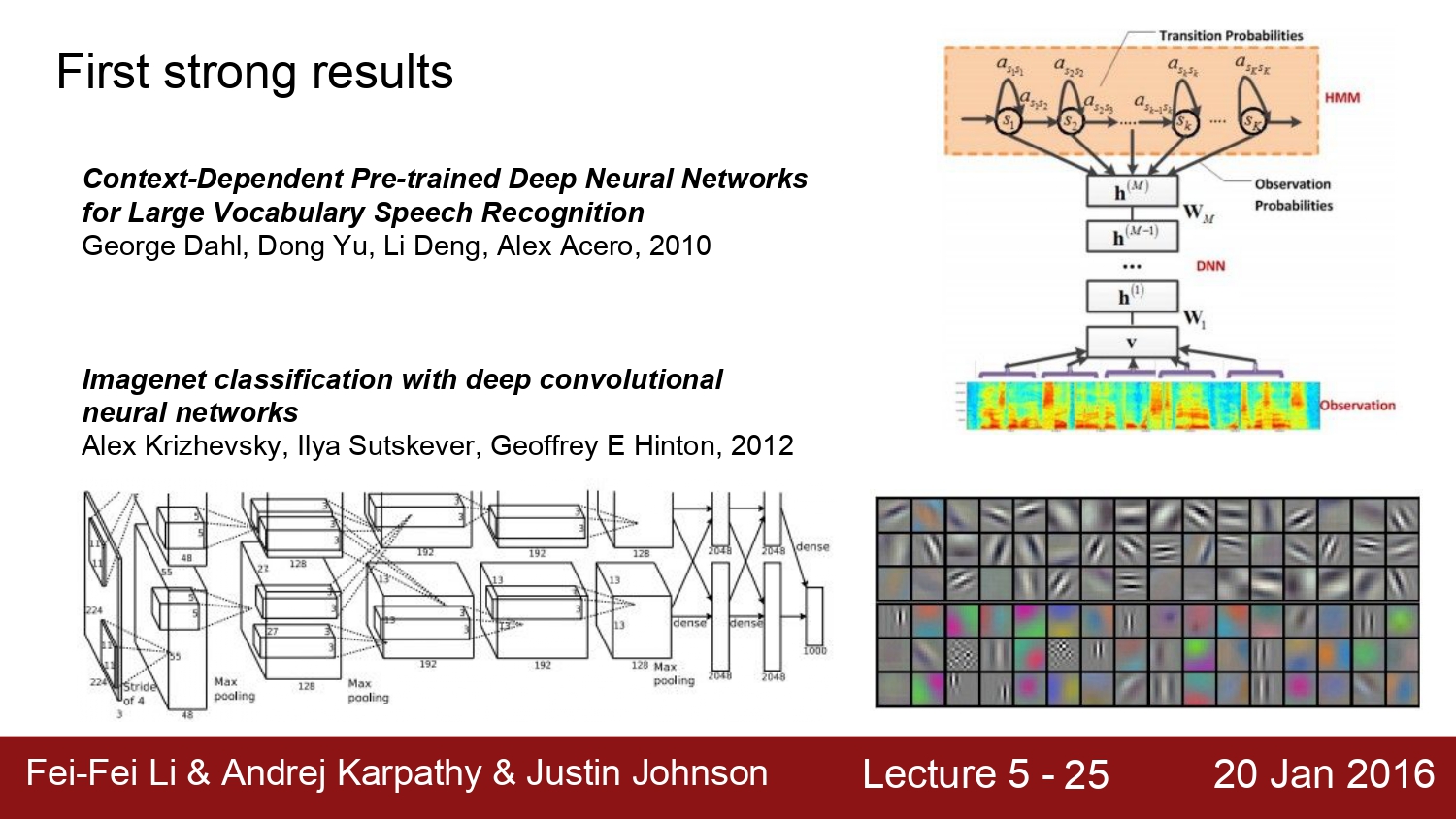
2010년 ms net의 등장과 2012년 alex net의 등장으로 딥러닝의 관한 연구는 본격적으로 시작했다. 그 이유는 이때부터 제대로 된 activation function을 사용하였고, 또한 GPU의 사용, data set의 증가 등 많은 요소가 있다.

지금부터는 신경망에 관련된 다양한 설정과 학습, 그리고 평가에 대해 알아보자

우선 각 layer를 연결해주는 activation function부터 살펴보자

우선 activation function의 가장 큰 역할은 linear 한 sum을 non-linear 한 sum으로 변경해주는 점이다.

대표적인 activation function들이다. 우리는 우선 이 중에서 sigmoid function이 왜 지금 사용되지 않고, 왜 사용되면 안 되는지에 대해 알아보자

sigmoid function은 우선 넓은 범위의 수를 0과 1 사이로 setting 해주지만, 문제는 뉴런이 포화가 되어서 vanishing gradient 현상을 야기한다.

vanishing gradient 현상이 일어나는 이유는 sigmoid function은 매우 큰 값과 매우 작은 값이 input으로 들어가게 된다면 결론적으로는 0과 1로 수렴하게 된다. 이 요인 때문에 vanishing gradient 현상이 일어나게 되어 backpropagation가 사라지게 된다.

2번째 문제는 sigmoid의 결괏값은 모두 0 이상이기 때문에 0에 centered 된 결과 값이 나오지 않는다.

결괏값이 모두 양수이기 때문에 여기서 해당하는 W의 값도 무조건 양수가 된다. 따라서 양수*양수, 음수*음수인 gradient가 되어 1, 4분면에만 위치하게 된다. 이럴 경우에 gradient를 갱신하는 과정에서 결국엔 zig zag path가 되어 gradient update 과정에서 delay가 생길 수밖에 없는 문제가 발생한다.

마지막 3번째 문제는 exp() 연산은 매우 expensive 한 연산이다. 이러한 이유로 전체적인 network의 성능이 저하된다고 한다. 따라서 sigmoid 함수는 더 이상 사용하면 안 된다.
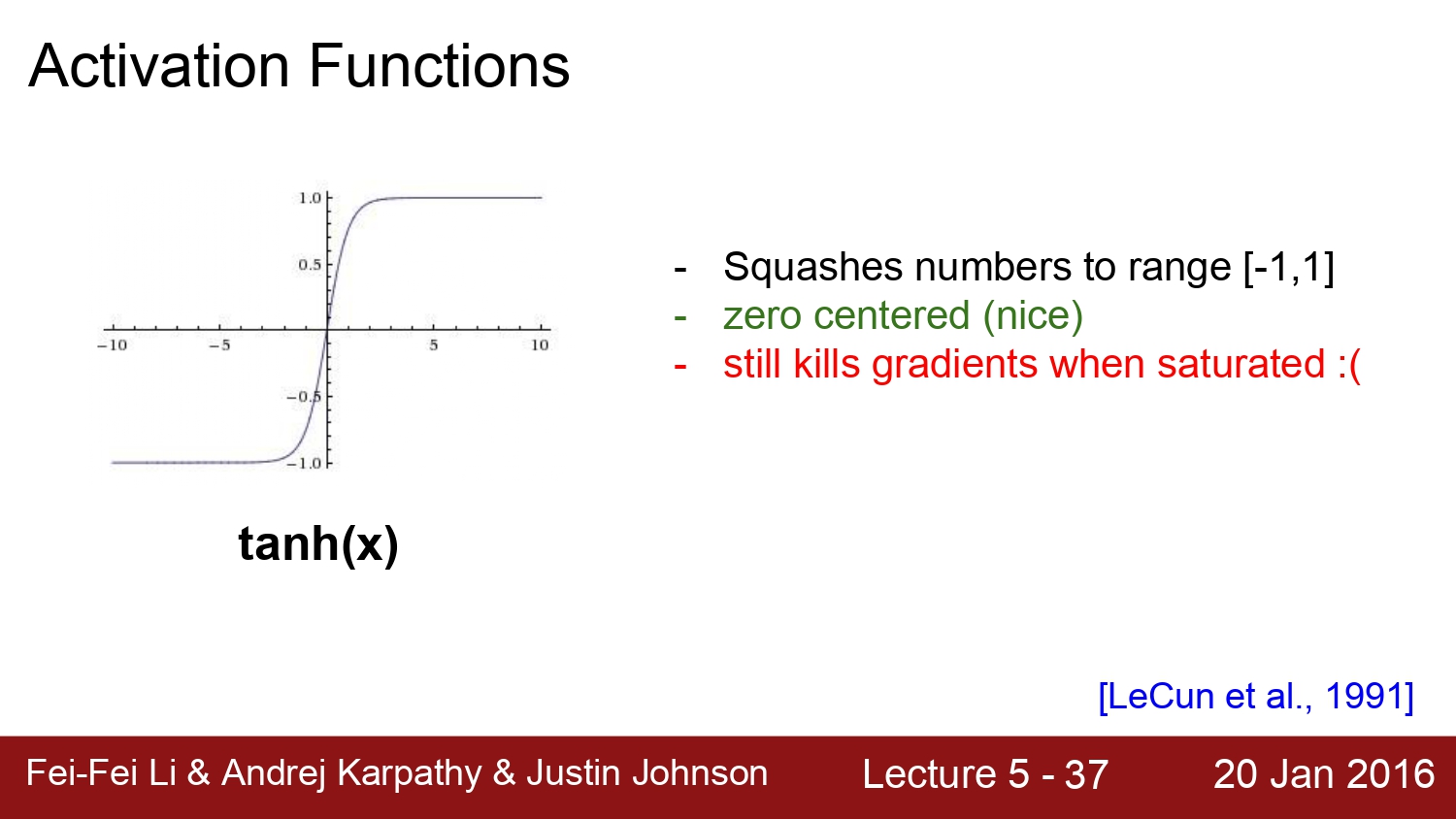
다음은 tanh함수이다. 이 함수의 장점은 zero-centered가 되었지만 이에 반해 여전히 x가 매우 크거나 작을 때에는 gradient 값이 0이 된다.
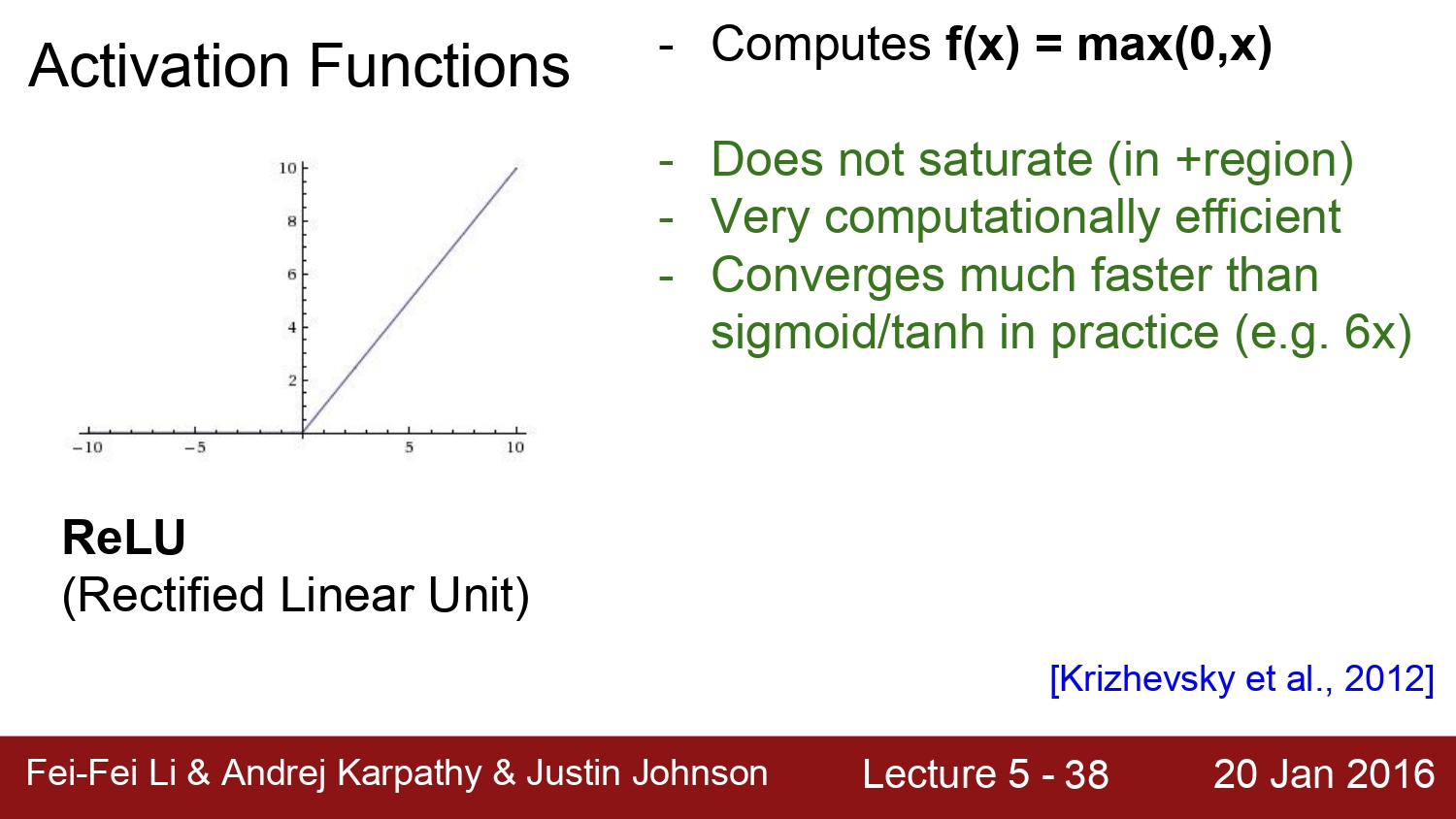
다음은 지금도 많이 쓰이고, activation function에서 가장 default 한 function인 relu이다.
relu는 0인 부분에서는 gradient가 존재하지 않는다. 또한 속도적인 측면에서 sigmoid, tanh보다 6배 더 빠르다고 한다.
하지만 여전히 문제점을 가지고 있다.
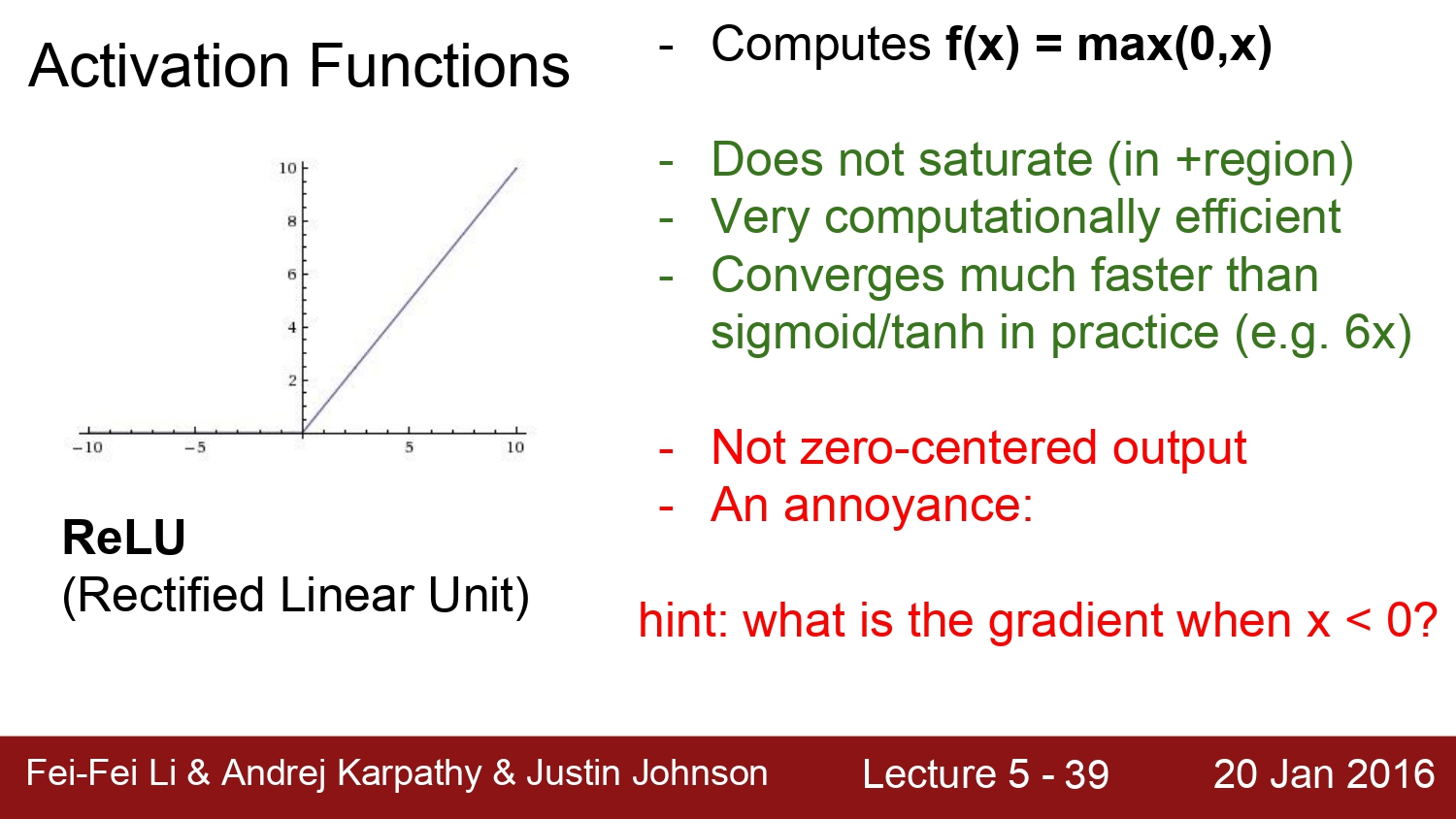
바로 0 centered가 아니다. x < 0인 경우에서는 gradient가 0으로 수렴하게 된다.
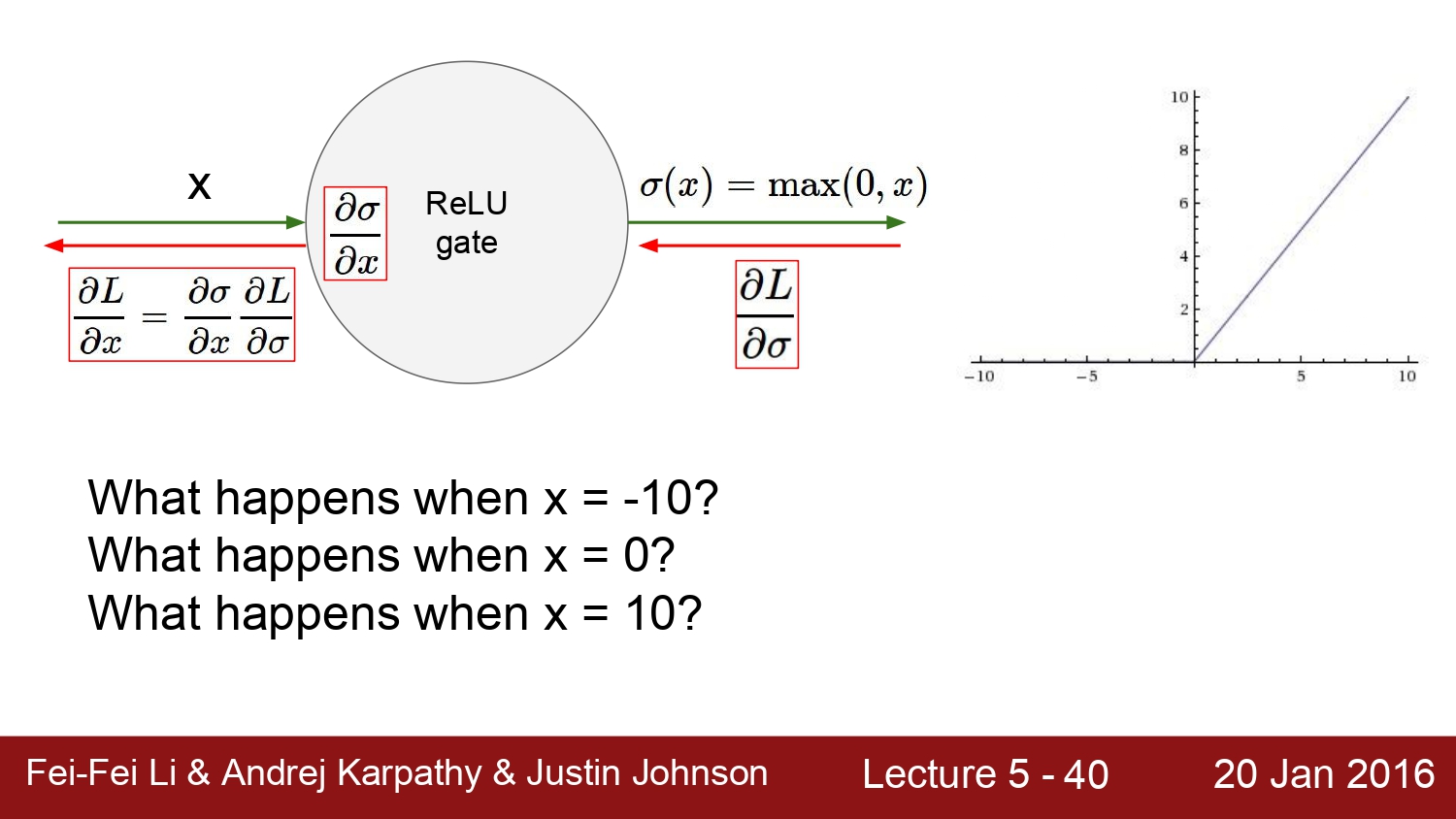
예를 들어보자. x가 10인 경우에는 gradient는 1이 된다. x가 -10이면 기울기가 0이 되어버린다. 결국에는 gradient가 죽어버린다는 의미이다. 또한 x가 0일 때에는 미분이 불가능하여 gradient가 정의되지 않는다. 하지만 이런 경우에는 희귀한 case라고 한다.
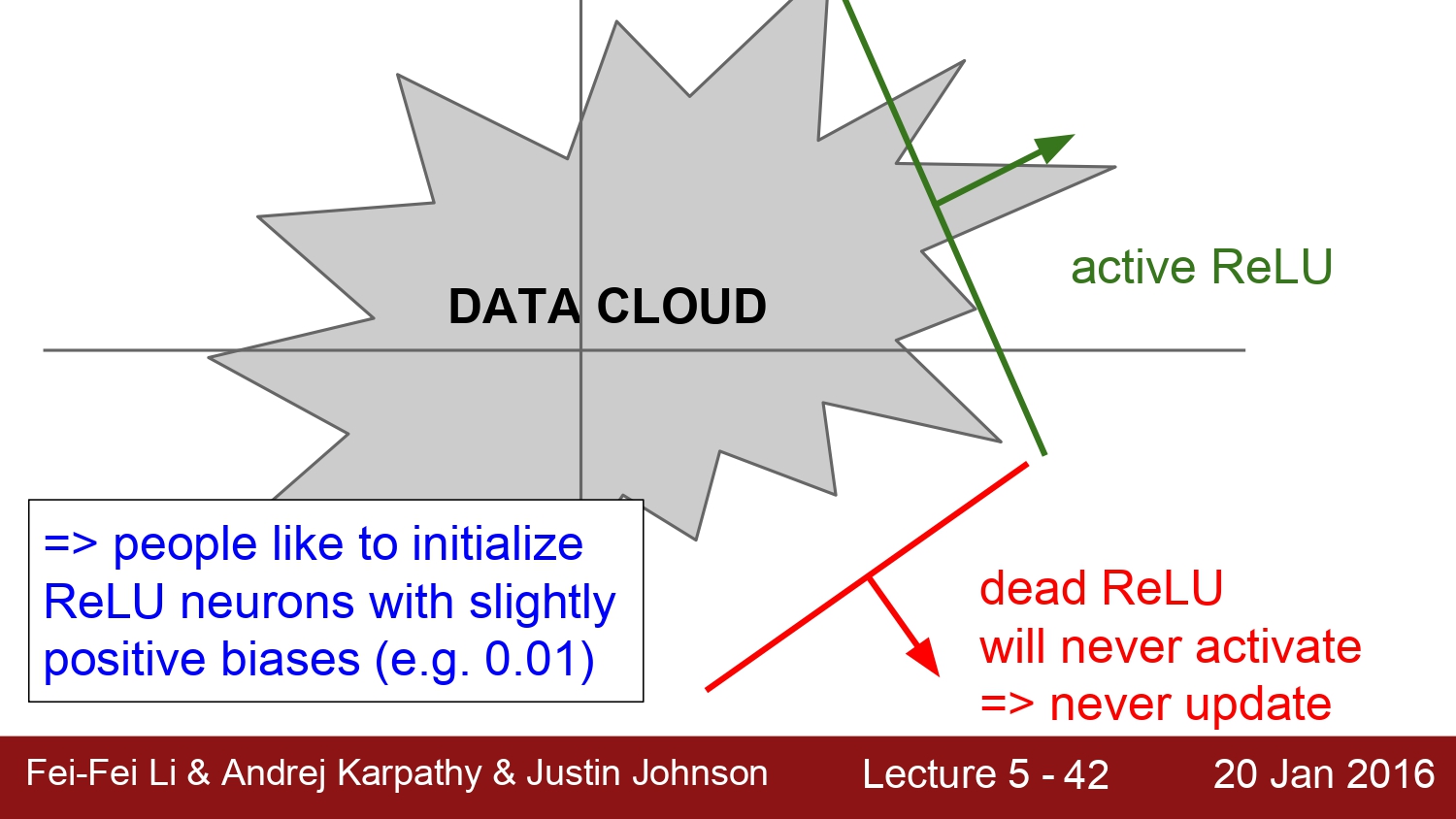
해당 좌표를 보면 회색 부분 안이 뉴런이 activation 된 case이고, 그 밖은 activation이 되지 않는 dead relu라고 한다.
dead relu가 발생하는 case는 weight를 initialization 할 때 dead relu에서부터 시작되는 경우와 learning rate의 값이 매우 커서 dead relu 범위로 튀어나오는 경우이다. 현실적으로 10%~20% 정도 발생하게 되는데 대부분의 case는 learning rate인 경우에 발생하게 된다. 이에 따른 해결책은 initialization에서 bias를 작은 양수로 초기화하면 해결된다고 한다. 하지만 이것에 대해서는 아직까지도 찬반양론이 존재한다고 한다.
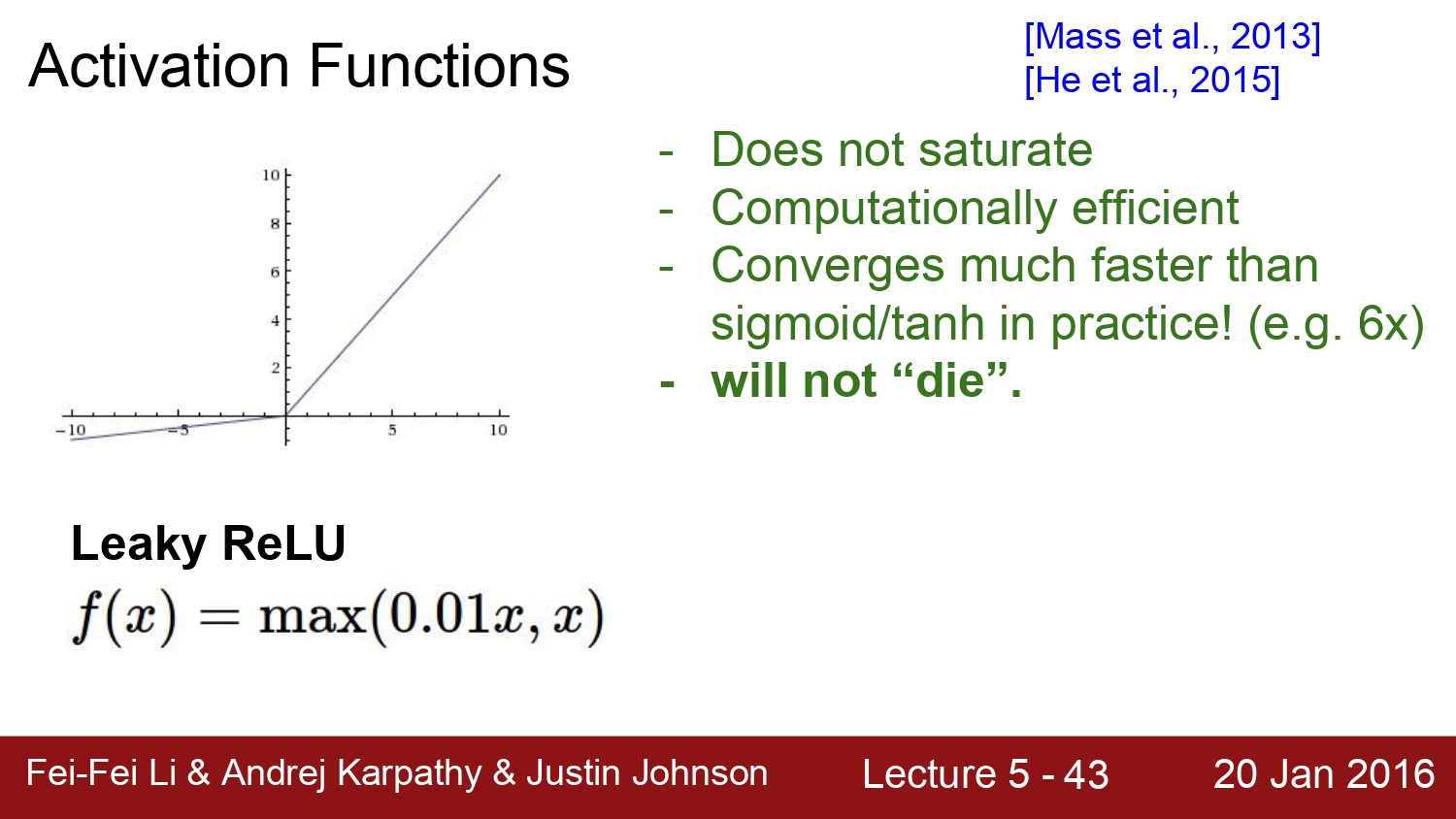
다음은 Leaky Relu이다. relu와 다른 점은 0보다 작을 때에는 0.01x를 곱해주는 것이다. 이런 경우에는 x의 범위와 상관없이 gradient가 죽는 case가 발생하지 않는다. 하지만 이 방법도 완전히 검증되진 않았다.
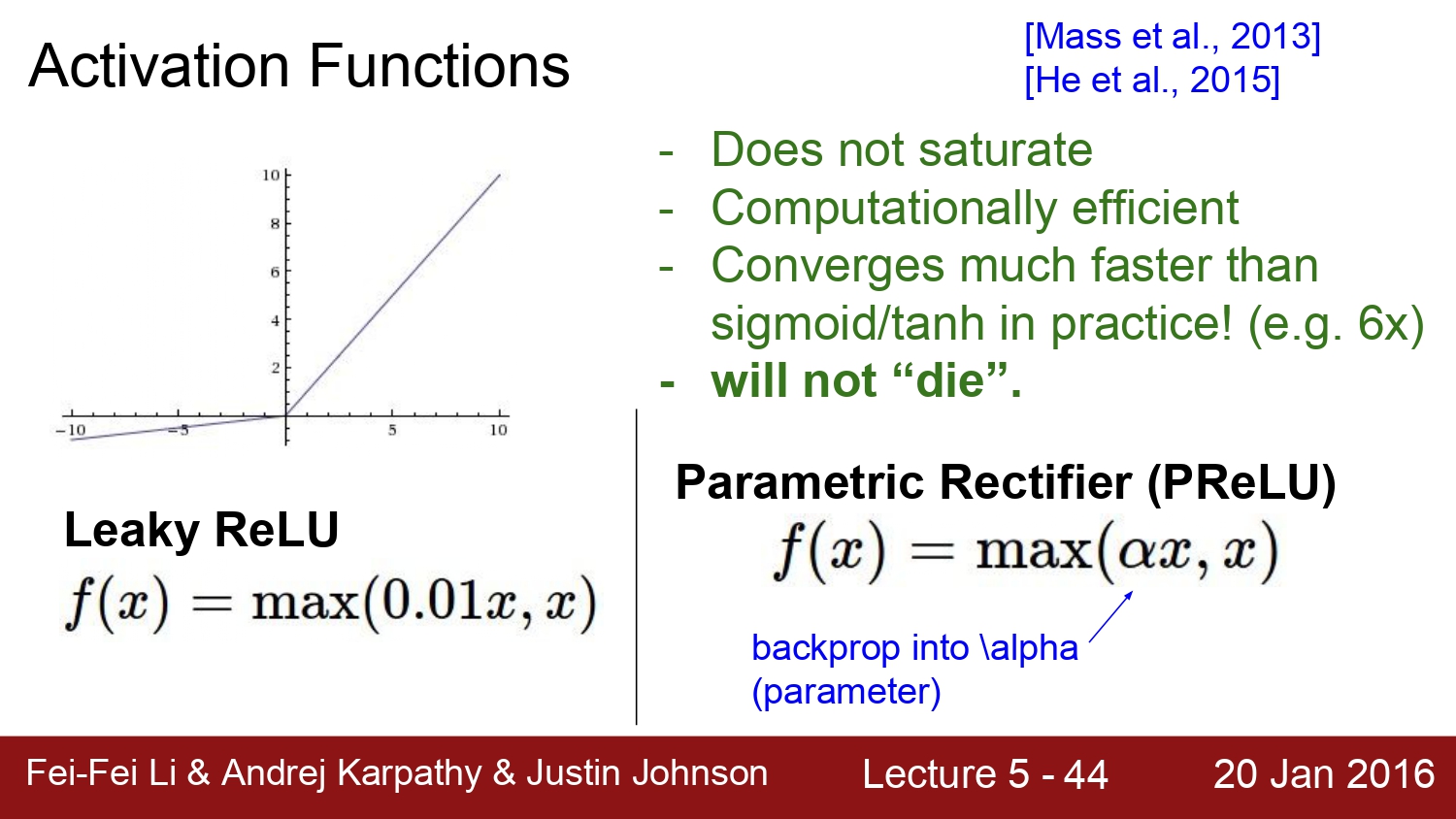
Parametric Rectifier (PReLu)는 a값 자체에서도 backpropagation 과정을 통해 학습되어 결정된다고 한다.
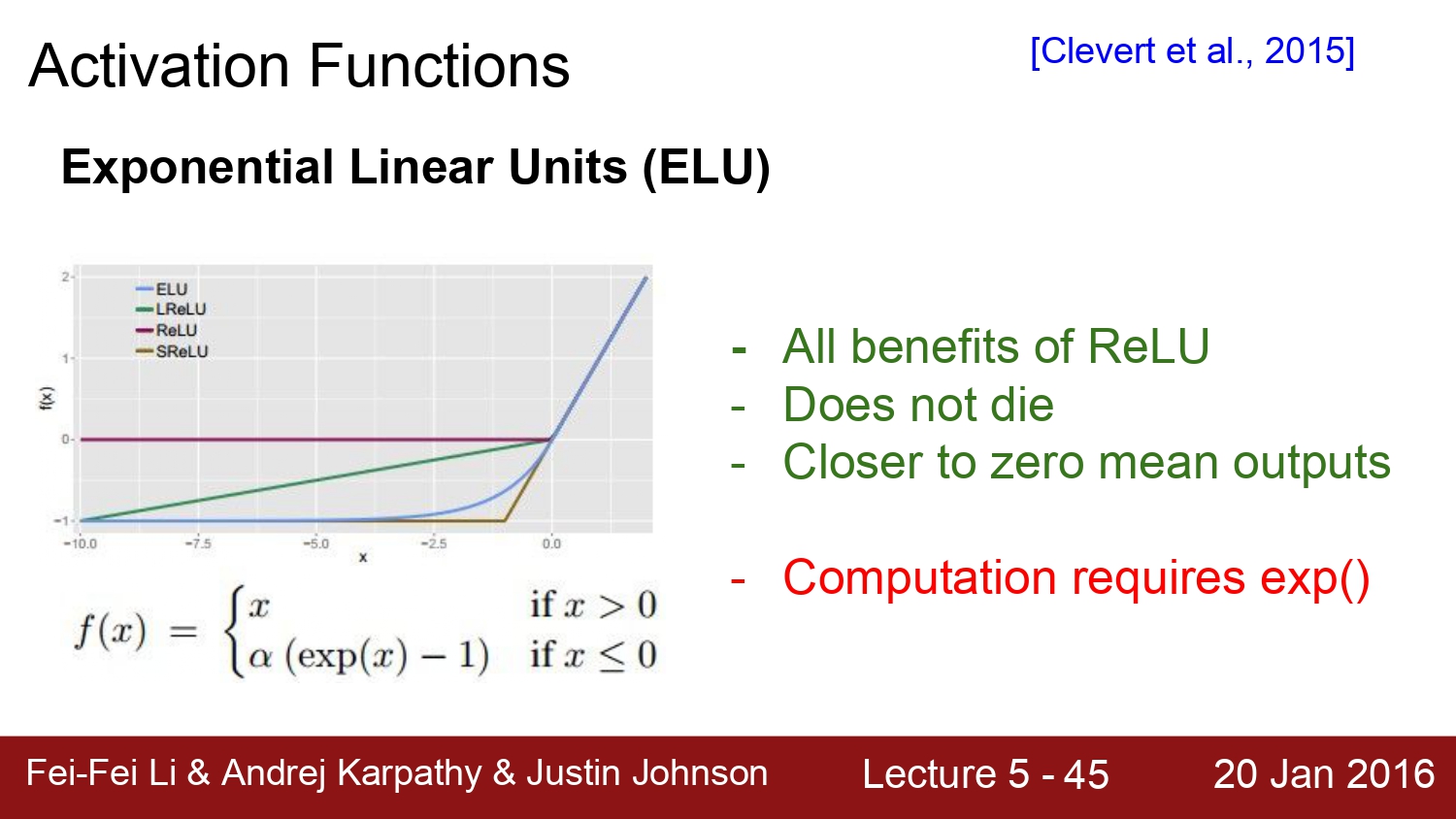
다음은 ELU이다. 이연 산은 relu의 모든 장점을 다 갖는다. 또한 zero-centered mean에 가깝다 하지만 아쉬운 점은 앞에서 설명한 바와 같이 exp(x) 연산이 cost가 매우 expensive 한 점이다.

다음은 maxout이라는 방법이다. 이는 단순한 형태가 아니고 뉴런이 연산하는 방법 자체를 변경한 방법이다. relu와 leaky relu를 보안하는 방법인데 단점은 w1과 w2라는 parameter가 추가된 점이다. network는 수만, 수억 가지의 parameter로 구성되는데 이를 적용함으로써 parameter가 2배로 증가하게 되어 연산량도 증가하게 된다는 점이다.

정리를 하자면 특별한 case가 아닌 이상 relu를 사용하고, 실험을 하고 싶을 때에는 다른 activation function을 사용하자.
하지만 tanh와 sigmoid는 더 이상 사용하지 말자. 하지만 LSTM에서는 여전히 sigmoid를 사용한다고 한다.
referance
http://cs231n.stanford.edu/2016/
https://www.youtube.com/watch?v=KT4iD6yiqwo
'study > cs231n' 카테고리의 다른 글
| Lecture 6: Training Neural Networks, Part 2 (0) | 2020.04.13 |
|---|---|
| Lecture 5-2: Training NN part 1 (~Data preprocessing) (0) | 2020.04.13 |
| Lecture 4: Backpropagation and Neural Networks part 1 (0) | 2020.03.25 |
| Lecture 3: Optimization (0) | 2020.03.20 |
| Lecture 2: Image Classification pipeline (0) | 2020.03.19 |



