
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- EfficientNet
- DeepLearning
- pytorch project
- cs231n lecture5
- CS231n
- pytorch
- svdd
- SVM margin
- yolo
- Object Detection
- SVM hard margin
- yolov3
- support vector machine 리뷰
- TCP
- 데이터 전처리
- SVM 이란
- self-supervision
- Deep Learning
- 서포트벡터머신이란
- 논문분석
- Faster R-CNN
- Computer Vision
- darknet
- fast r-cnn
- computervision
- libtorch
- RCNN
- cnn 역사
- pytorch c++
- CNN
- Today
- Total
아롱이 탐험대
Lecture 8: Spatial Localization and Detection 본문

이전까지는 cnn의 동작원리에 대해 알아보았고, 오늘부터는 cnn의 많은 종류 중 하나인 Spatial Localization and Detection에 대해 알아보자. 참고로 이번 챕터에서는 몇 개의 논문이 나오는데 이는 cs231n 분석에서 생략하고 논문 리뷰 카테고리에 있는 논문 리뷰를 링크를 줄 테니 참고 바란다.

CNN을 크게 보면 4가지 종류가 있다. 전체적으로 본다면 오른쪽으로 갈수록 컴퓨터 입장으로써 더 어렵다고 생각하면 된다.
우선 맨 왼쪽에 위치한 classification부터 보자. classification은 단순히 사진을 input으로 받으면 cnn이 이에 해당하는 label을 붙어준다.
두 번째인 classification+localization은 앞서 설명한 classification과 해당 object의 위치 box를 좌표로 반환하는 localization을 합친 구조이다.
세 번째인 object detection은 2번째 classification+localization과 비슷하지만 차이점은 여러 object를 detecting 할 수 있는 점이다.
마지막인 instance segmentation은 여러 object를 각각의 평상을 따라 구별해준다.
오늘은 classification+localization과 object detection에 대해 알아보자

classification+localization부터 살펴보자

우선 classification의 같은 경우에는 input으로 image가 주어지면 output은 해당 image에 해당하는 lebel이 나오게 된다. 이때 사용하는 평가 지표는 accuracy이다.
이에 반해 localization도 비슷하지만 output은 object가 속해있는 box 좌표이고, 사용하는 평가지표는 IoU이다. 이는 정답 영역과 output으로 나온 영역의 비율이라고 생각하면 된다.

여기서 잠깐 Image net이라는 세계에서 가장 유명한 이미지 인식 대회가 있다. 이 대회는 classification뿐만이 아닌 여러 분야가 있는데, 여기서 사용하는 data set은 1000개의 class로 구성되어 있다. 이 대회도 다른 논문과 마찬가지로 top 5 error를 도출한다. localization 같은 경우에는 0.5 이상이 되면 정답이라고 간주한다.

Localization을 하는 방법 중 첫 번째 방법인 Localization as Regression에 대해 살펴보자. regression는 k개에 대한 물체를 localization 할 때 detection에 대해 신경을 쓰지 않아도 된다. 그 이유는 이 방법은 input image를 넣었을 때 output으로 나오는 box 좌표와 정답 box 좌표의 loss를 비교하며 backpropagation을 통해 update 하여 최적화를 진행한다.

이를 수행하는 방법은 첫 번째는 classification을 진행할 모델을 학습시킨다.

step 2는 Regression head를 conv layer의 끝부분에 추가시킨다.

step은 regression head를 오직 SGD와 L2 loss를 사용하여 update 한다.
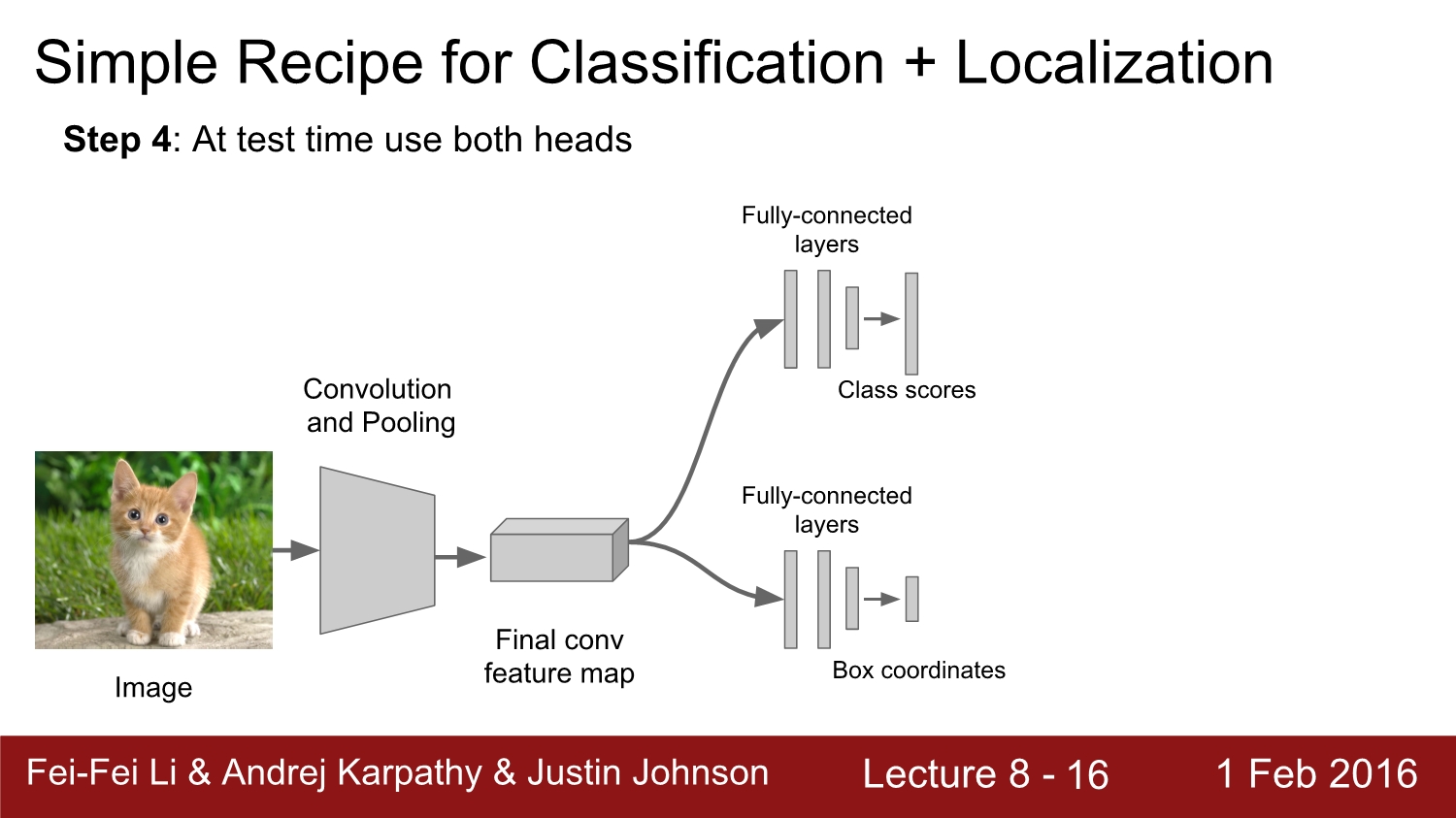
test시에는 위아래를 둘 다 사용하여 결괏값을 산출한다.

regression head는 아까 설명한 바와 같이 2가지가 있다. Classification head에서는 해당 객체를 분류하는데 특화되어있고, Class agnostic은 box에 해당하는 좌표에 대해 특화되어 있다. class agnostic은 1개의 box만 결과 값으로 나오게 된다. Class specific은 4개의 box 좌표가 각각의 class별로 나타난다. class agnostic과 class specific의 차이점은 loss 계산만 차이가 난다.

regression head는 마지막 conv layer 뒤에만 붙어주면 된다. fully connected layer에도 붙이는 경우가 있다. 둘 다 정상적으로 작동한다고 한다.

고정되어있는 k의 개수의 대한 object detection은 굳이 detection을 사용하지 않고 regression 방법을 사용한다고 한다.

예를 들어 이렇게 사람의 관절을 파악하는 problem도 regression을 통해 잘 구해진다고 한다. 굳이 무거운 detection을 사용하지 않아도 된다.

정리하자면 Localization as regression은 매우 간단하고, 여러 프로젝트에서 활용된다.

다음은 2번째 방법인 sliding window이다. 기본적으로 regression 방법과 동일하게 2개의 head로 구성되어 있고, image의 여러 부분에 위치한 window를 여러 번 돌려서 합쳐준다. 그리고 편의성을 위해 맨 마지막 layer인 fc layer를 conv layer로 변형시켜서 진행한다.

2013년 우승 모델인 overfeat에 대해 알아보자. 해당 network는 alexnet과 유사하다. 이 경우에는 크기가 더 큰 image가 더욱 정확도가 높다고 한다. 아래 그림을 보면 검은색 box가 sliding window이고, 둘 다 겹치는 부분에서 score를 구한다. 그다음에는 window를 sliding 하여 다음 영역에 대한 score를 구한다. 이를 모든 이미지에 대해서 진행한다.







마지막으로는 score를 모두 합침으로써 이렇게 image에 대한 score인 0.8을 구하였다.

실제로는 매우 많은 window를 이용하여 score를 구하게 되고, 이를 통해 score map을 작성하게 된다. 위 예시 같은 경우에는 곰 쪽에서 큰 score의 분포를 볼 수 있다. 하지만 수많은 window를 사용하게 된다면 연산에 대한 속도는 매우 커지게 된다.


따라서 계산을 더욱 효율적으로 하기 위해 fc 대신 conv layer를 사용한다. (위에서 아래 이미지로 바꿈)
마지막으로 나오는 output인 4096을 단순한 vector로 생각하지 말고, 또 다른 conv feature map으로 생각하면 된다. 이 feature map을 transpose 연산을 해주고, 차원을 추가함으로써 conv layer로 전환해준다.

이런 과정을 통해 fc layer를 conv layer로 변경해줌으로써 연산을 진행한다.

accuracy 측면으로 보게 되면 VGG는 localization에서 1등을 차지하였다. Res net은 깊어지긴 하였지만 localization 과정을 아예 변경하였다.

다음은 object detection에 대해 알아보자

앞에서 regression이 매우 잘된 것이 확인되었다. 그래서 이 regression은 object detection에서 활용을 해보는 것은 어떨까? 만약에 image에 object가 4개 존재하면 output 좌표는 총 16개가 나오게 된다.

object가 2개인 경우에는 총 8개가 나온다.

하지만 object가 매우 많은 경우에는 4n개의 output이 나오게 된다. 이러한 이유 때문에 많은 object를 detection 하는 problem에서는 regression이 적당하지는 않다. 하지만 나중에 배우게 되는 YOLO에서는 regression을 사용하여 object detection을 진행하였다.



이런 방법으로 각각의 다른 영역의 window를 shift 하면서 classification을 통해 detection을 진행한다.

이러한 방법으로 classification으로 접근하였을 때 문제점은 가급적 다양한 size의 많은 window를 활용하기 때문에 너무 많은 test case가 나오게 된다. 이에 대한 해결책은 그냥 진행해도 된다. 왜냐하면 이 방법은 그렇게 무겁지 않기 때문이다.

전통적인 방법인 HOG를 보게 되면 image에 대해 linear classification을 하게 된다. 이를 다양한 영역에 대해 진행하게 되고 결과는 매우 잘 동작한다.

HOG에 대한 후속 연구 중 1개가 DPM이다. 여전히 HOG를 기반으로 진행하였고, 특징은 부분 부분에 대한 template을 가지고 진행한다. 이뿐만 아니라 다양한 변형된 형태도 가지고 있다.

이건 2015년에 나온 논문이다. 논문에 대한 이야기는 DPM이 알고 보니 cnn의 기법 중 1개인 것을 설명하고 있다. Edge에 같은 경우에는 conv를 사용하고, hist는 pooling을 이용하였다고 한다.

classification 기법의 문제점은 무거운 모델을 사용하는 것이다. 이런 경우에는 모든 영역이나 모든 scale를 보기에는 너무 무겁다. 이에 대한 해결책은 전체 지역을 보지 말고, object가 있는 의심되는 지역만 보고 계산하는 것이다. 이를 region proposal이라고 한다.

위 이미지를 보게 되면 object를 포함할 것 같은 이미지의 영역을 찾은 것을 볼 수 있다. 이 것들을 blob이라고 하는데 유사한 색이나 texture를 갖는다. blob 한 region을 찾는 과정에서는 정확도를 신경 쓰지 않는다. 따라서 매우 빠르게 동작하고, 결과적으로 보았을 때는 오른쪽 이미지처럼 된다.

위 방법은 region proposal 방법 중하나인 selective search이다. 픽셀에서 진행하고 비슷한 픽셀끼리 클러스터링 한다. 그 후 알고리즘을 사용하여 더 큰 blob을 만들게 된다. 최종적으로는 맨 왼쪽 아래와 같은 box가 나오게 된다. 장점은 모든 영역을 계산하지 말고 박스 영역에 대해서만 계산하면 된다.

이외에도 region proposal에 대한 알고리즘은 많다. 교수님은 edge box 알고리즘을 추천한다고 한다.

이제부터는 우리가 앞서 배웠던 Region proposal과 cnn이 합쳐진 R-CNN에 대해 알아보자. R-CNN의 단점을 보완한 fast R-CNN, faster R-CNN도 있다. 지금부터 lecture8의 끝까지의 내용들은 전에 리뷰하였던 내용과 같아 링크로 대체한다.
R-CNN: https://ys-cs17.tistory.com/4
Fast R-CNN: https://ys-cs17.tistory.com/5
Faster R-CNN: https://ys-cs17.tistory.com/7
referance
http://cs231n.stanford.edu/2016/
https://www.youtube.com/watch?v=KT4iD6yiqwo
'study > cs231n' 카테고리의 다른 글
| Lecture 11: CNNs in Practice (0) | 2020.04.22 |
|---|---|
| Lecture 9: Understanding and Visualizing Convolutional Neural Networks (0) | 2020.04.21 |
| Lecture 7: Convolutional Neural Networks (0) | 2020.04.16 |
| Lecture 6: Training Neural Networks, Part 2 (0) | 2020.04.13 |
| Lecture 5-2: Training NN part 1 (~Data preprocessing) (0) | 2020.04.13 |



