
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- CS231n
- pytorch c++
- self-supervision
- libtorch
- 논문분석
- 데이터 전처리
- RCNN
- pytorch
- SVM hard margin
- EfficientNet
- SVM 이란
- svdd
- computervision
- fast r-cnn
- 서포트벡터머신이란
- darknet
- yolov3
- Deep Learning
- SVM margin
- pytorch project
- yolo
- CNN
- Object Detection
- cs231n lecture5
- Computer Vision
- DeepLearning
- support vector machine 리뷰
- TCP
- Faster R-CNN
- cnn 역사
- Today
- Total
아롱이 탐험대
Lecture 11: CNNs in Practice 본문

이번 강의에서는 Covolution nueral network가 실전에서는 어떻게 사용이 되는지 알아보자
시작하기 앞서 lecture10은 cnn이 아닌 rnn에 대한 내용을 담고 있기 때문에 pass 하겠다.

오늘 배울 내용들이다. 크게 3가지 chapter로 구성이 되는데 첫 번 재는 data, 두 번째는 convolution, 마지막으로는 hardware 측면에서 알아보겠다.

자 그럼 Data Augmentation에 대해 알아보자

일반적인 CNN에서는 모델에 image와 label이 들어가고, forward, backward path를 통해 loss를 구하고 줄인다. Data augmentation에서는 아래와 같이 image의 원본을 변형하는 과정이 쓰인다.
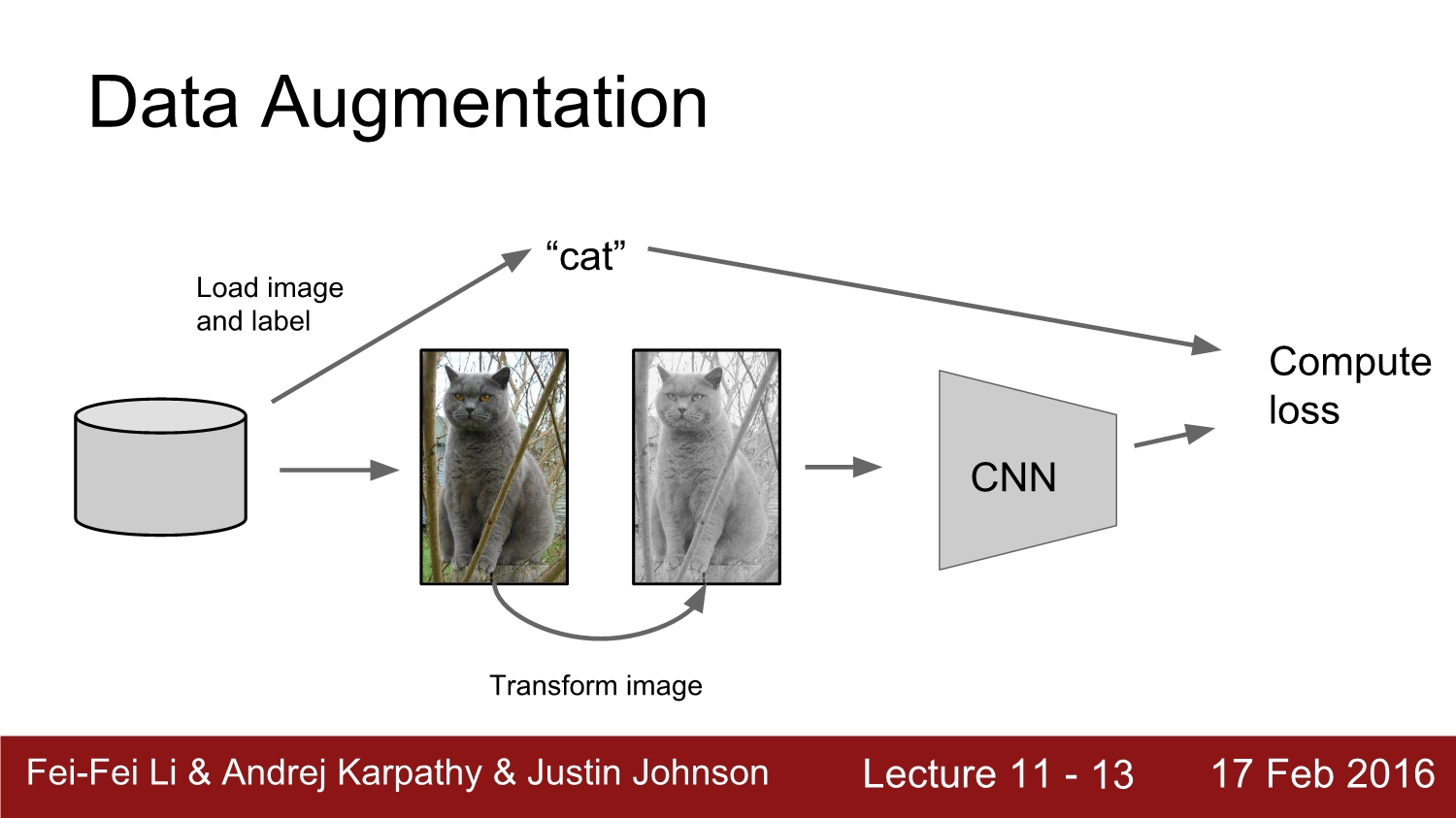

Data augmentation은 이미지에 해당하는 label값을 변경하지 않고 단순이 픽셀을 변경한다. 이는 매우 폭넓게 활용된다고 한다.

가장 간단한 방법은 이미지를 뒤집어 주는 것이다. 이는 단순히 코드 1줄로도 구현할 수 있다. 이를 또한 mirror imaging이라고 한다.

두 번째 방법은 random crops/scales이다. 말 그대로 랜덤 하게 자르고, 랜덤하게 크기를 갖게 한다. 그 후 해당 이미지들을 가지고 학습을 진행한다.

training시 image 전체가 아니라 이미지에 해당하는 부분 부분에 대한 학습이 이루어짐으로 test 할 때도 정해진 수의 crop을 가지고 진행한다. 그 후 이에 대한 평균을 output으로 주면 된다.

res net에서는 한걸음 더 나아가 image를 5개의 크기로 하여 총 10개의 crop을 사용한다.

3번째 방법은 Color jittering이다. 대조를 사용하여 이미지의 색을 변화시킨다.
복잡하지만 많이 사용하는 방법은 우선 이미지의 rgb에 대해 주성분 분석을 진행한다. 그러면 principal component direction을 얻게 되는데 이를 가지고 색이 변화해가는 방향성을 알 수 있다. 그러고 나서 offset을 이미지의 모든 픽셀에 대해 더하게 된다.

이 외에도 다양한 방법들이 존재한다. 가장 중요한 점은 나의 data set이 무엇이 필요한지 생각하고 결정해야 한다.

더욱 general 하게 보자. training은 random noise를 더해주는 과정이고, testing은 noise를 평균화하는 과정이라고 생각하면 된다. 넓은 의미에서 data augmentation은 dropout, drop connect와 비슷하다. batch normalization과 모델 앙상블과도 비슷하다.

정리하자면 구현하기 간단하기 때문에 무조건 적용하라는 의미이다. 데이터가 적으면 더욱 유리하다.

다음으로 살펴볼 것은 transfer learning이다. 우리는 CNN을 사용하려면 굉장히 많은 data를 가지고 있어야 된다는 사실은 잘못된 믿음이다.

transfer learning의 진행 방식에 대해 알아보자. 우선은 image net을 가지고 우리의 모델을 학습시킨다. pre trained 모델을 미리 다운로드하여도 된다.
그 후 이때 만약 가지고 있는 data set이 적으면 fc 1000 layer와 softmax만 내버려두고 나머지를 모두 freeze 한다. 이전까지의 가중치는 변화하지 않다는 것을 의미하고, feature를 추출해주는 것을 의미한다.
만약 data set의 양이 애매하다면 fine tuning을 사용하면 된다. 이대 freeze 영역을 잘 조절해야 한다.
여기서 팁은 화살표 빨간 상자에서 초록색 부분은 learning rate를 0.1로 설정하고, 주황색 부분은 0.01을 사용하면 좋다고 한다. 일반적으로 full train보다는 transfer train이 성능이 더 좋다. 그리고 전혀 무관한 data를 넣어도 성능이 좋아진다. 그 이유는 무엇일까?
해답은 다양하고 많은 데이터를 가지고 가버필터와 같이 위쪽 layer에서는 edge와 같은 크게 인식하는 것을 잘 학습하고, 아래로 갈수록 구체적인 부분만 인식하기 때문에 적은 데이터를 가지고 학습을 시킨 경우보다는 성능이 훨씬 더 좋다고 한다.

이는 다양한 것들을 실험해본 결과이다.
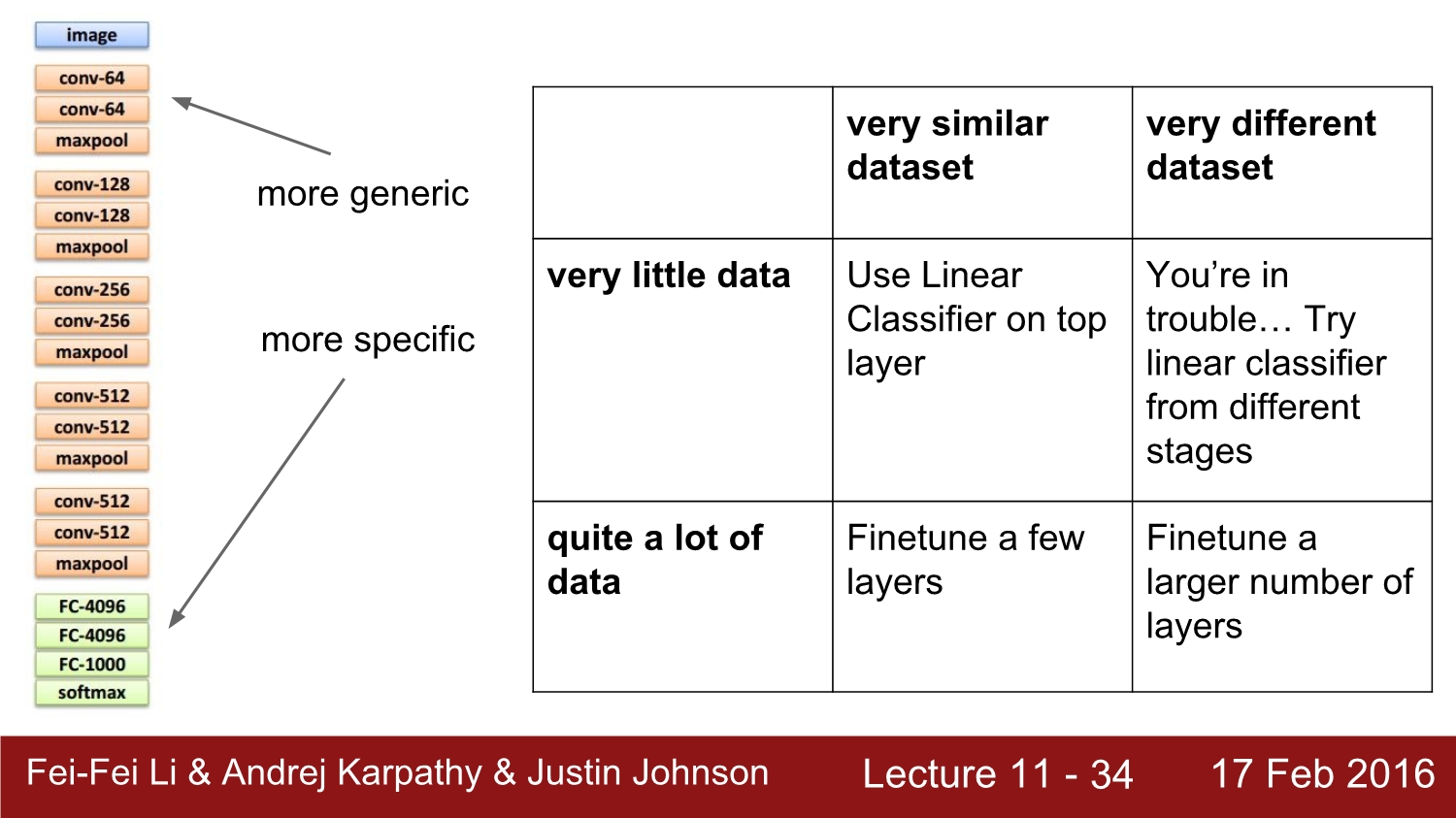
x축은 data의 유사성, y축은 data의 양이다. 당연히 초기 layer는 generic 하고, deep 해질수록 specific 해진다. data의 종류에 따라 이런 식으로 진행하면 된다.

CNN에 있어서 앞에서 말한 바와 같이 항상 transfer learning을 사용해야 한다. cnn+rnn에서도 활용이 가능하다.

우리가 프로젝트에 임하는 데 있어 데이터가 작으면 큰 데이터 셋을 만들거나 아니면 transfer learning을 활용하는 방법이 있다. 또한 pre trained model들은 대부분의 framework에서 제공한다.

이제부터는 convolution의 모든 것에 대해 알아보자.
그중 part 1은 convolution layer를 쌓는 방법이다.

small filter가 얼마나 강력한지에 대해 앞으로 알아보자. 우선 2개의 3*3 convolution layer를 쌓는다고 가정하자. 그림과 같이 first conv는 input의 3*3을 보게 되고, sencond는 first conv의 3*3을 보게 된다.
여기서 그러면 second conv는 input의 무엇을 보게 될까? 정답은 5*5이다. 그 이유는 first에서 3*3을 보고 first는 3*3 input을 보기 때문이다.

이번에는 3개를 쌓는다고 가정하자. 3번째 convolution layer의 1개의 뉴런은 input에 대해 어느 정도 영향을 받을까? 정답은 7*7이다. 우리가 3*3을 3개 쌓는 것이 결과적으로 7*7과 동일한 representation의 power를 갖게 된다.

input이 h*w*c이고 c 개의 filter를 이용하고 depth을 보존한다고 가정하자
7*7을 가지는 conv와 3개의 3*3을 가지는 conv를 비교해보자. 결과적으로 weight의 개수는 각각 49c^2, 27c^2가 나오게 된다. 결국 7*7로 연산을 진행하는 것보다는 3개의 3*3을 가지는 것이 parameter가 훨씬 적고, nonlinearity에 대해서도 더 좋다고 한다. 이것이 바로 작은 filter의 강력함이다.

다음은 곱셈 연산이 어떻게 발생하는지 보자. 결과적으로 보았을 때도 작은 필터가 더 유리하다는 사실을 알 수 있다.

그러면 1*1 필터를 쓰면 어떻게 될까? 위 이미지와 같이 1*1을 사용하는 부분을 bottleneck이라고 부른다. 1*1 conv를 이용하여 dimension을 줄이거나 복원하게 된다. 이런 구조들은 유용성이 입증되어있어 여러 모델에서도 활용된다.

bottlenect을 이용한 conv와 오른쪽에 바로 3*3 연산을 한 것을 비교하게 되면 결과적으로는 둘 다 같게 된다.

하지만 결과적인 측면으로 보았을 때 사용되는 parameter의 수는 왼쪽이 훨씬 작게 된다. 하지만 여전히 여기에서 3*3 conv을 이용하는데 parameter의 수를 더 줄일 수 있을까?

bottleneck을 사용하지 않고 3*3 conv 연산을 하면 왼쪽과 같이 1*3, 3*1로 쪼개어서 더욱 효율적인 연산을 진행할 수 있다.

최근 network들은 이런 형식을 가지면서 conv 연산을 진행한다.

정리를 하자면 큰 filter를 가지는 conv를 사용하지 말고, 작은 걸로 대체하는 게 매우 좋다. 또한 bottleneck을 사용하면 매우 효율적으로 작동하게 된다. 그리고 n*n 연산을 1*n, n*1로 대체하면 더 좋아진다.

2번째는 conv들을 어떻게 계산하는지 확인해보자

compute를 진행할 때에는 im2 col이라고 불리는 연산을 많이 사용한다. 그 이유는 matrix 곱 연산은 매우 빠른 연산이다.
여기서 알아낸 사실은 우리는 conv를 matrix 곱으로 표현할 수 있지 않냐?이다. 이를 반영하여 연산하는 방법이 바로 im2 col이다.
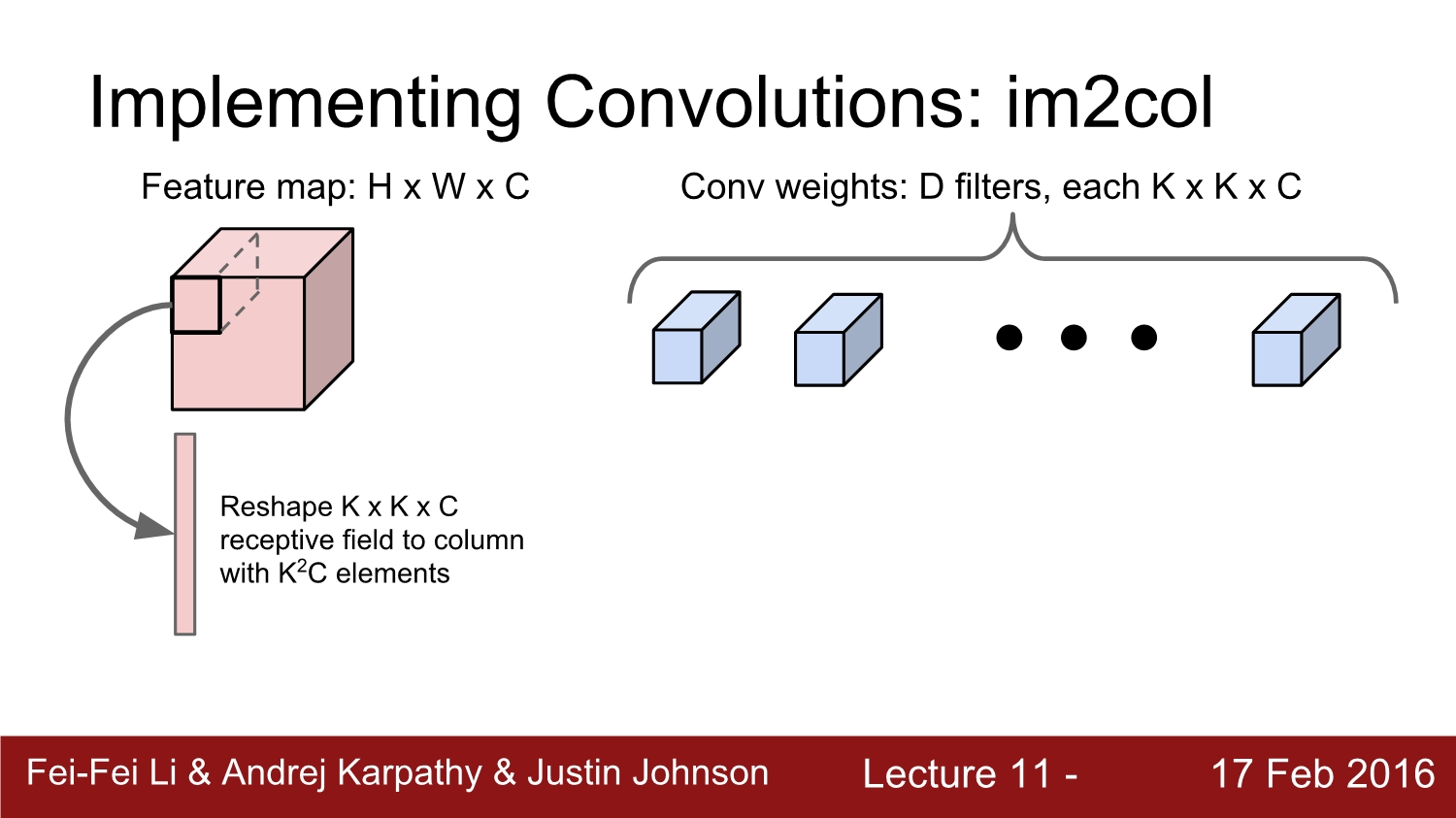
우선 feature map이 h*w*c로 되어 있고, filter가 k*k*c로 되어있다고 가정하자. 우리는 해당 feature amp을 연산하기 위해 k*k*c column으로 reshape 해준다.

그리고 나면 n개의 column이 생성이 되는데 이는 총 (k^2c)*n이다. 여기서 1가지 문제점은 receptive field의 원소들이 서로 중복이 돼서 메모리가 낭비된다. 하지만 이것은 큰 문제가 아니다.
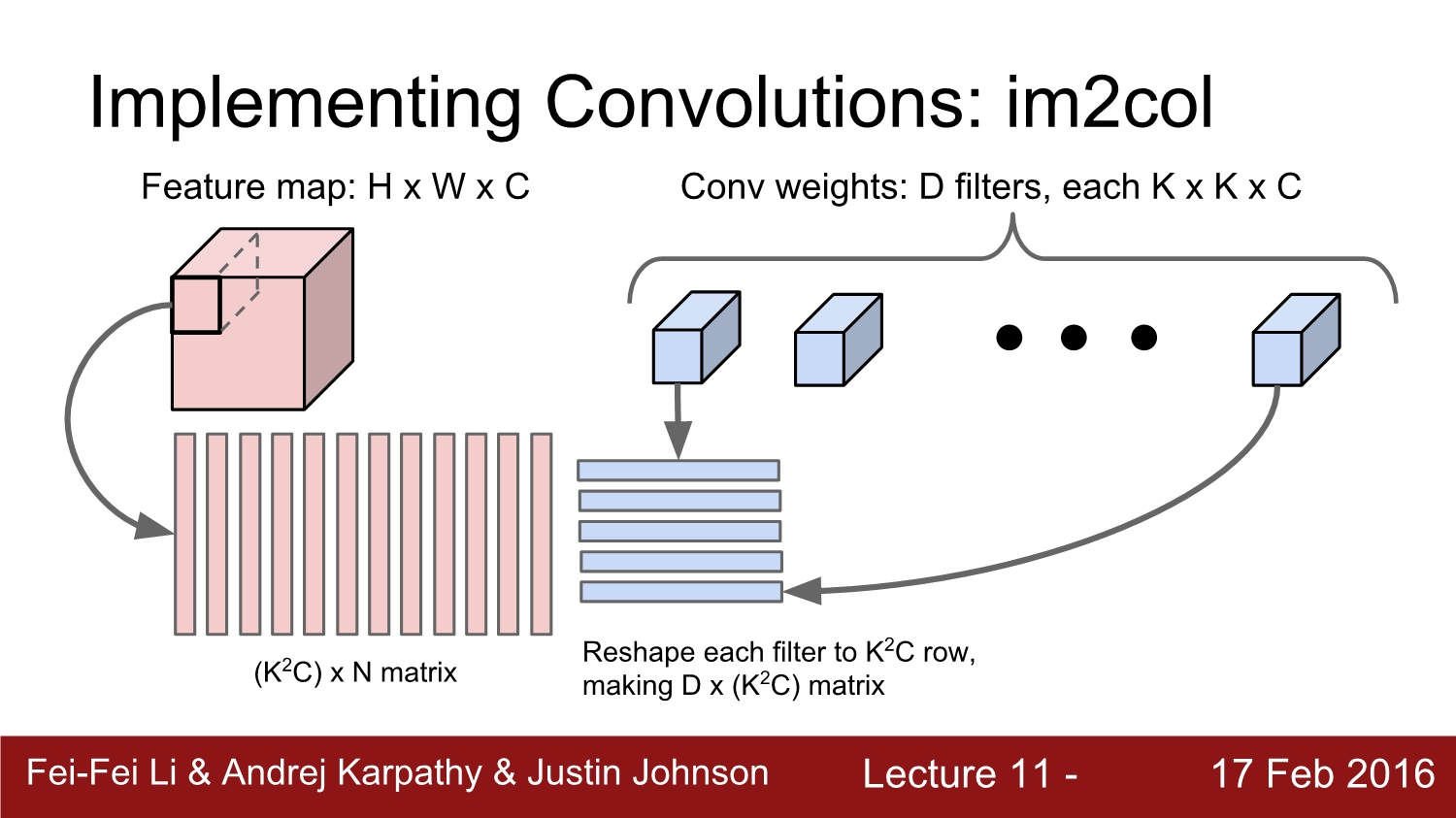
다음 단계에서는 filter에 해당하는 부분을 row 벡터로 reshape 해준다. 그러면 d*(k^2*c)가 나오게 된다.
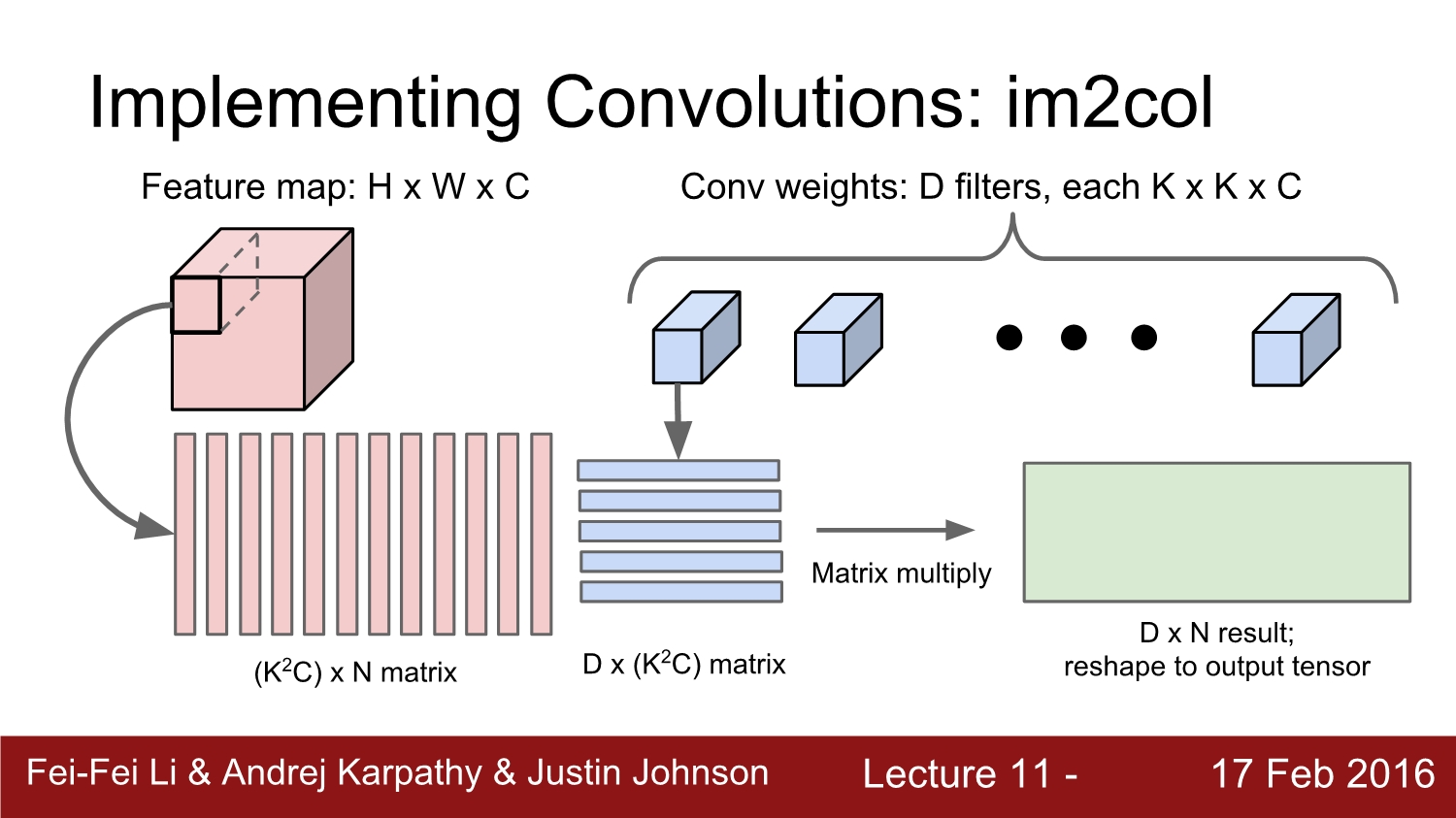
그다음에는 앞에서 구한 2개의 matrix인 n*(k^2c)와 d*(k^2c)를 곱하여 d*n의 결괏값을 얻는다.

im2 col은 실제로도 매우 많이 사용되는 연산 방법이다. 빨간 영역이 im2 col을 호출하는 부분이다. 파란색 부분에서는 행렬 곱을 해준다. 이에 대한 자세한 코드 분석은 나중에 따로 포스팅하겠다.

conv를 활용하는 다른 계산은 FFT(Fast Fourier Transform)가 있다. 이건 sigmoid processing과 관련이 있다.
위 식과 같이 convolution f와 convolution g를 곱하면 이렇게 된다고 한다. 이는 퓨리에 변환과 역행렬을 빠르게 계산하는 방법이다.

방법은 우선 weight와 input image의 FFT를 계산한다. 그 후 이 둘을 점곱을 해준다. 그다음 FFT의 역행렬을 곱해주면 된다.

FFT를 적용시킨 결과이고, 초록색 부분이 빠르다는 의미이다. 이는 즉 filter가 작으면 효과가 별로 없다는 의미이다.

다른 방법은 Fast Algorithm이 있다. 원래 n*n 행렬 연산을 하면 big O는 매우 커지게 된다. 하지만 위와 같은 식으로 big O를 많이 줄였다고 한다.

결과적으로 속도 향상이 굉장히 컸다. 단점은 size가 다르면 변환을 시켜줘야 한다. 하지만 속도가 매우 빠르기 때문에 앞으로 이 방향으로 연구가 계속될 것이라고 한다.

정리를 하자면 im2 col은 메모리가 많이 소요되는 대신 구현이 쉽다. FFT는 큰 커널에 대해 속도가 빠르다. Fast Algorithm은 빠르지만 아직은 연구가 많이 진행되지는 않았다.

이제는 conv에 대한 직접적인 구현에 대해 자세히 알아보자

GPU는 대표적으로 2가지 종류로 나뉘게 되는데 일반적으로는 NVIDIA의 GPU를 사용한다.

cpu는 코어가 적지만 매우 빠르다. 또한 순차적인 접근의 속도가 빠르다. gpu는 느린 코어들이 매우 많다. 보통 수천 개가 있다. 하지만 병렬 연산에서 강력하다. 그래서 딥러닝에서 많이 쓰인다.

gpu는 많은 병렬 계산 최적화 api가 존재하는데 cuda는 nvidia에서만 돌아가고 opencl은 모두 돌아간다. cuda는 c로 바로 돌릴 수 있다는 장점이 잇다.
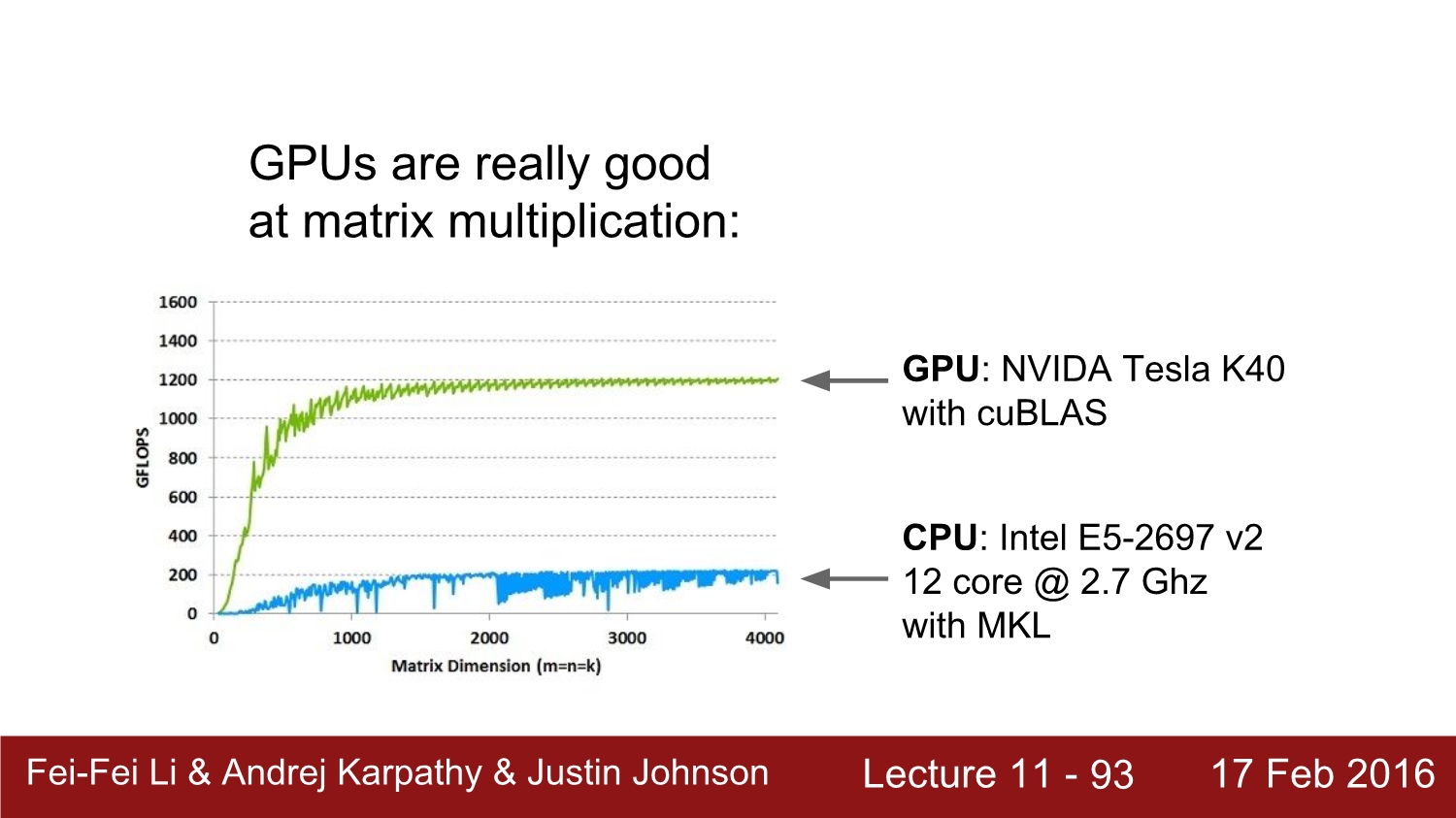
cpu와 gpu의 속도 비교이다.
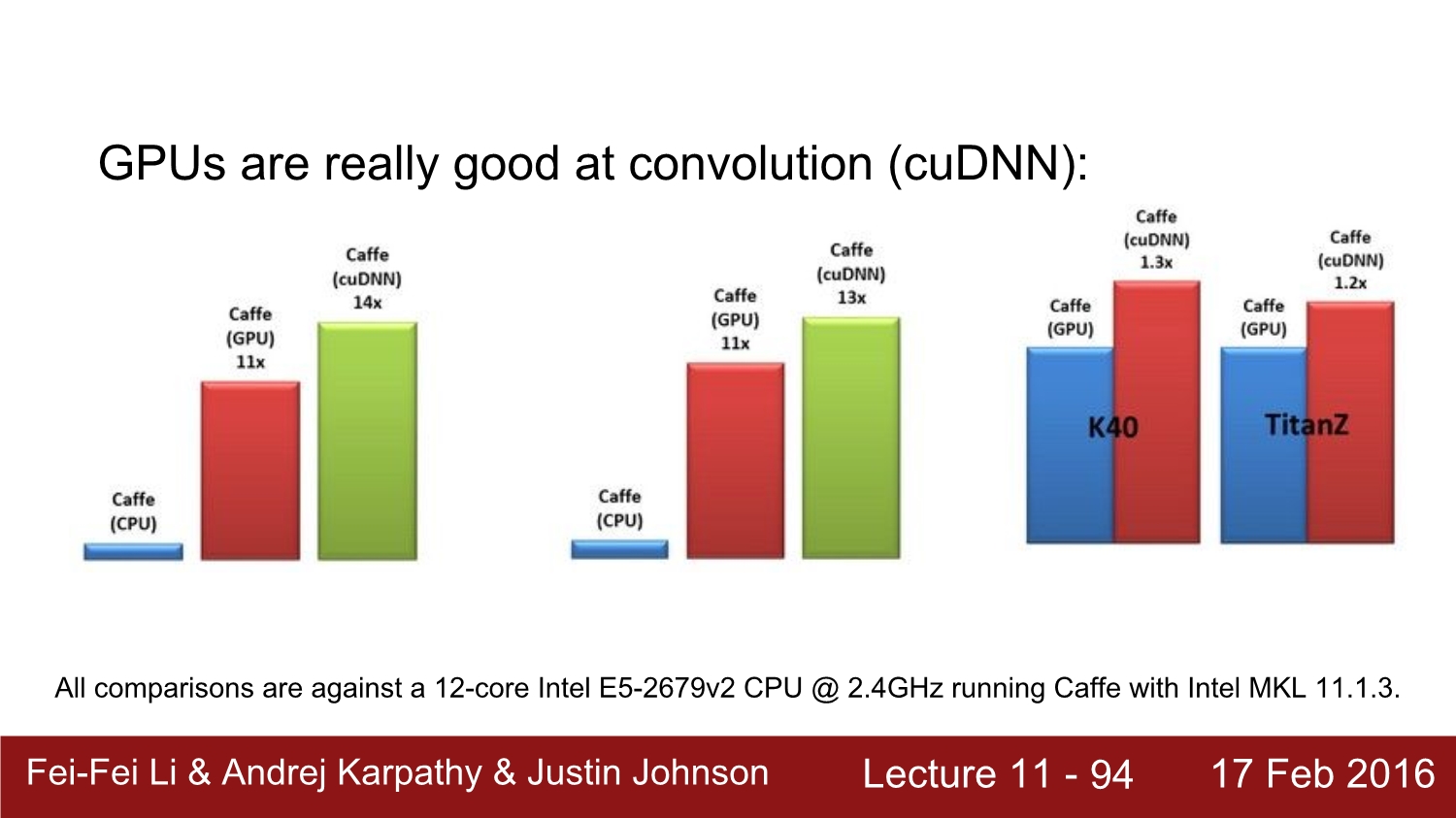
속도 차이가 많이 크다. 그리고 cuDNN을 쓰면 더욱 속도가 올라간다.

하지만 gpu를 사용해도 시간은 오래 걸린다. VGG와 ResNet을 학습시킬 때는 4개 기준 약 2~3주가 걸린다고 한다.

멀티 gpu 계산은 더욱 복잡하다. fc에서는 함께 진행을 하고, conv layer에서는 각 gpu별로 계산하는 게 효율적이라고 한다.
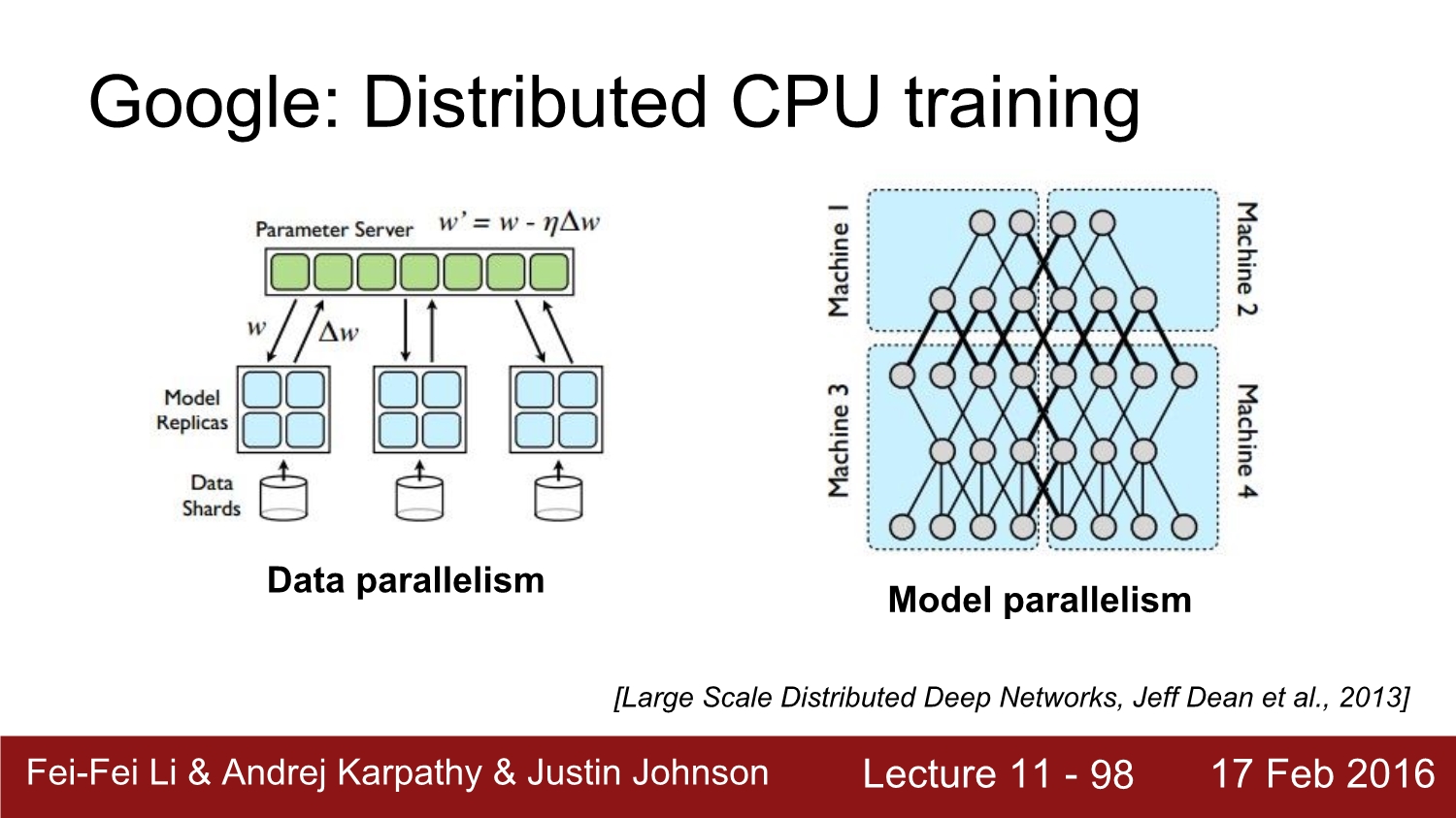
구글이 tensor flow 이전에 가지고 있던 프레임 워크가 distributed인데 이는 cpu로 연산을 한다. 각 파라미터를 서버에 저장을 해놓고 communication을 하면서 진행하였다. 모델은 병렬적 구조로 이렇게 생겼다.

이제는 bottleneck에 대해 알아보자

cpu, gpu의 의사소통이 bottleneck이 될 수 있다. 복사하는 과정이 매우 오래 걸려 gpu에서 forward path와 backward path를 진행해야 한다.

다음은 hdd 대신 ssd를 사용해야 한다. 그리고 이미지들을 바로 전 처리해서 바로 읽을 수 있도록 하면 된다.

알렉스 넷만 보더라도 batch를 256으로 하면 3기가 바이트가 돼버린다. 메모리가 충분해야 한다.

소수점 관련 이슈에 대해 알아보자

일반적으로는 64비트를 사용하지만 성능의 향상을 위해 conv net에서 32비트를 사용할 수 있다. 실제로 32비트를 더 많이 사용한다.

32비트도 커서 16비트가 새로운 표준이 되지 않을까? 이미 cuDNN에서 지원을 하고 있다. 너바나라는 빠른 네트워크도 16비트로 처리한다. 하지만 2의 16승은 큰 수가 아니다. 그래서 정확도에서 문제가 있을 수도 있다. 이를 고려해야 한다.

stochastic은 16비트로 연산 도중 곱셈을 할 때 비트수를 잠깐 올리는 것이다. 이러면서 에러가 줄어든다. 앞으로는 더 성능을 좋게 하려고 1비트로 계산을 할 수 있다.
referance
http://cs231n.stanford.edu/2016/
https://www.youtube.com/watch?v=KT4iD6yiqwo
'study > cs231n' 카테고리의 다른 글
| Lecture 13: Segmentation (0) | 2020.04.27 |
|---|---|
| Lecture 9: Understanding and Visualizing Convolutional Neural Networks (0) | 2020.04.21 |
| Lecture 8: Spatial Localization and Detection (0) | 2020.04.17 |
| Lecture 7: Convolutional Neural Networks (0) | 2020.04.16 |
| Lecture 6: Training Neural Networks, Part 2 (0) | 2020.04.13 |



