
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- support vector machine 리뷰
- CS231n
- yolo
- computervision
- cnn 역사
- DeepLearning
- CNN
- 서포트벡터머신이란
- Object Detection
- SVM 이란
- darknet
- SVM hard margin
- fast r-cnn
- pytorch
- RCNN
- self-supervision
- Deep Learning
- SVM margin
- TCP
- libtorch
- 논문분석
- cs231n lecture5
- yolov3
- 데이터 전처리
- pytorch project
- Computer Vision
- EfficientNet
- Faster R-CNN
- pytorch c++
- svdd
- Today
- Total
아롱이 탐험대
Lecture 9: Understanding and Visualizing Convolutional Neural Networks 본문
Lecture 9: Understanding and Visualizing Convolutional Neural Networks
ys_cs17 2020. 4. 21. 11:20
Lecture 9에서는 cnn을 보다 더 시각적인 자료와 함께 이해하는 시간이다.

우선 CNN이 무엇을 하는지 알아보는 방법은 여러 가지지만 우선은 Activation map을 보며 이해해보자.

우선 오른쪽에 있는 alex net에 존재하는 pool 5 layer에서 임의의 뉴런을 취한 후 train을 돌린다. 해당 layer에서 추출한 임의의 뉴런들 중 어떤 뉴런이 가장 활발하게 활성화되는지 실험을 하는 과정이다. 실험의 결과는 왼쪽의 그림과 같이 특정 객체가 있는 local에서 뉴런들이 활발히 activation 되는 것을 볼 수 있다.

2번째 방법은 kernel을 visualize하는 방법이다. 이는 garber filter를 이용한 결과이다. garber filter는 edge와 같은 feature들을 filtering 한 것이다. 이런 식으로 filter를 사용하여 visualize 하는 방법은 conv1 layer에서만 가능하다. 그 이유는 첫 번째 conv layer만이 실질적인 image input에 대해 filtering 된 것이기 때문이다.

conv1 layer 이후의 또 다른 conv layer들은 전 단계의 activation map을 기준으로 convolution을 적용하는 layer이기 때문에 의미가 크지 않다고 한다.

garber filter 같은 형태의 visual을 보게 된다면 이는 cnn에서만 만들 수 있는 것이아니라 다른 오래된 알고리즘에 의해도 생성할 수 있다고 한다. 왜냐하면 garber filter는 나온 지 오래된 알고리즘이기 때문이다.
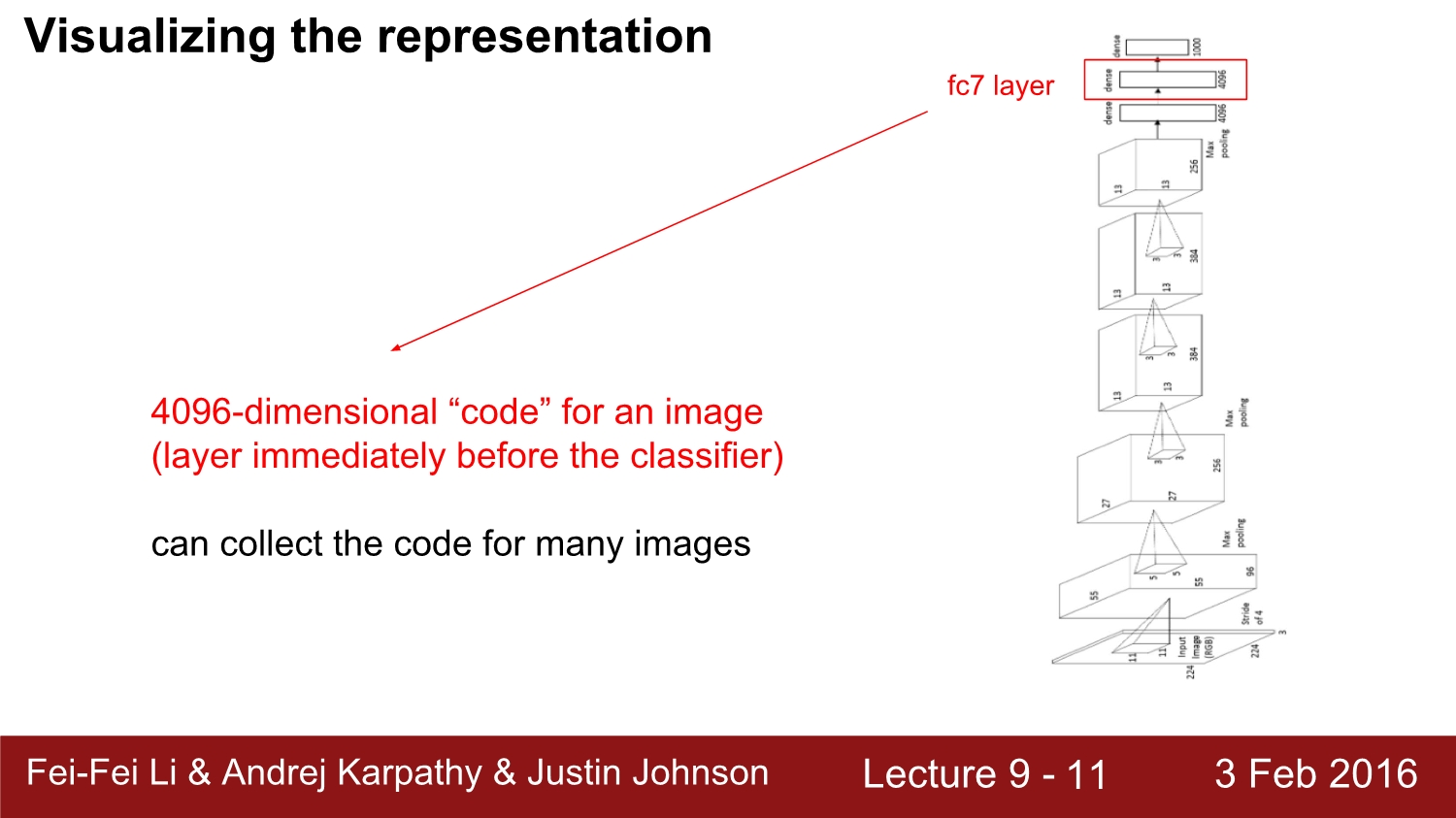
3번째 방법은 representation 자체를 visualize하는 방법이다. 모델을 살펴보면 맨 마지막 직전의 layer인 FC7 layer에서 4096차원의 code가 존재한다. 여기에서 여개의 image에 대한 전체 코드를 모아서 visualize 한다.

representation 방법 중 대표적인 것은 t-SNE이다. 이는 유사한 것들을 가까운 곳으로 모아 군집화시킨다. 위의 예시는 mnist dataset으로 표현하였다.

이는 imagenet을 활용하여 테스트한 것이다.

4번째 방법은 은닉을 통해 실험을 하는 방법이다. 여기서 회색 부분들을 0으로 채워진 정사각형 행렬을 만들어서 1개의 함수로 만든다. 이 정사각형을 통해 얼마나 더 잘 분류를 할 수 있는지 sliding을 통해 객체에 대한 확률이 어떻게 변화하는지 측정하는 방법이다.

이는 파란 부분이 확률이 떨어지는 부분이라고 한다. (강의에서는 그랬는데 내 생각에는 파란색으로 갈수록 더욱 확률이 증가하는 것 같다.)

이는 실제로 웹사이트를 통해 하는 예제 링크이다. Activation을 visualizing 하는 방법에는 2가지 접근 방법이 있다. 첫 번째는 deconvolution-based approach, 두 번째는 optimization-based approach이다.

우선은 deconv approach에 대해 알아보기 앞써, 만약 이미지가 input일 때 특정 layer에서 특정 뉴런의 gradient를 계산하려면 어떻게 해야 할까?

정답은 임의의 뉴런이 존재하는 곳까지 forward path를 진행하고, 해당 layer에 있는 뉴런 외에는 모두 gradient를 0으로 만들고, 해당 뉴런에만 1.0의 값을 주면 된다. 그다음 여기서부터 backward path를 진행하면 된다.

그렇게 진행하면 이런 흑백의 이미지가 나오게 된다.

이를 좀 더 선명하게 만들려면, guided backpropagation을 진행하면 되는데 이는 positive 값만 얻게 됨으로 더욱 이미지가 선명하게 된다.
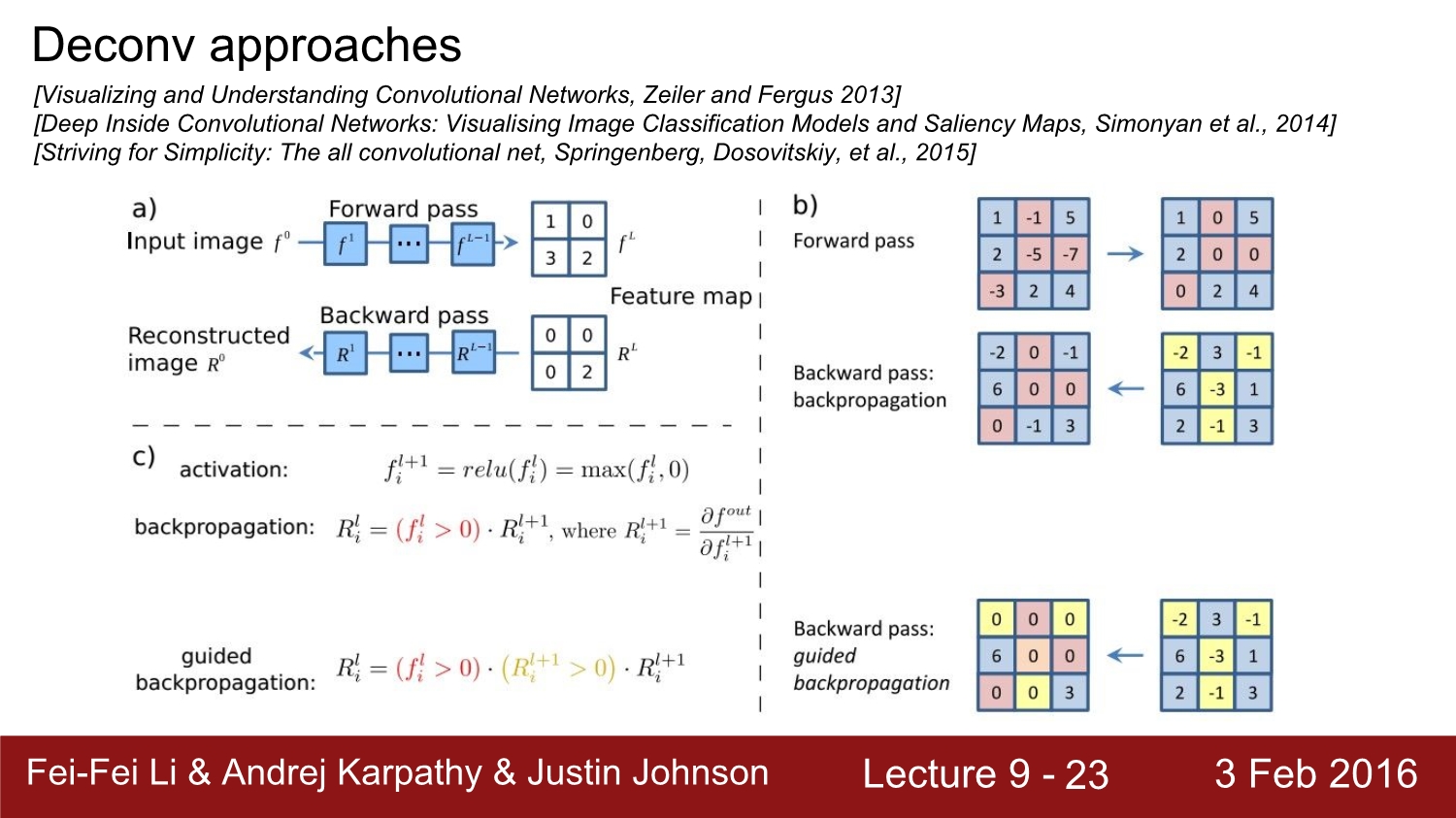
화면에 a부분을 살펴보자. 우선 결괏값이 forward path에서 이렇게 나왔다고 가정하자. 우리가 여기서 관심 있는 값은 2라고 하자. 그러면 backward path에서는 2를 제외하고 나머지를 다 0으로 둔다.
b부분은 activation function이 relu인 경우이다. 이와 같은 경우에는 0인 부분만 빼고 모두 그대로 전달되어 있는 모습을 볼 수 있다. guided 같은 경우에는 gradient의 음수인 부분도 모두 0으로 두고 positive만 그대로 통과시키는 모습을 볼 수 있다.
c는 relu와 guided의 backpropagation 수식이다.

앞서 설명한 guided backpropagation을 사용하여 이미지에 대한 결과가 더욱 선명하게 나온 모습을 확인할 수 있다.
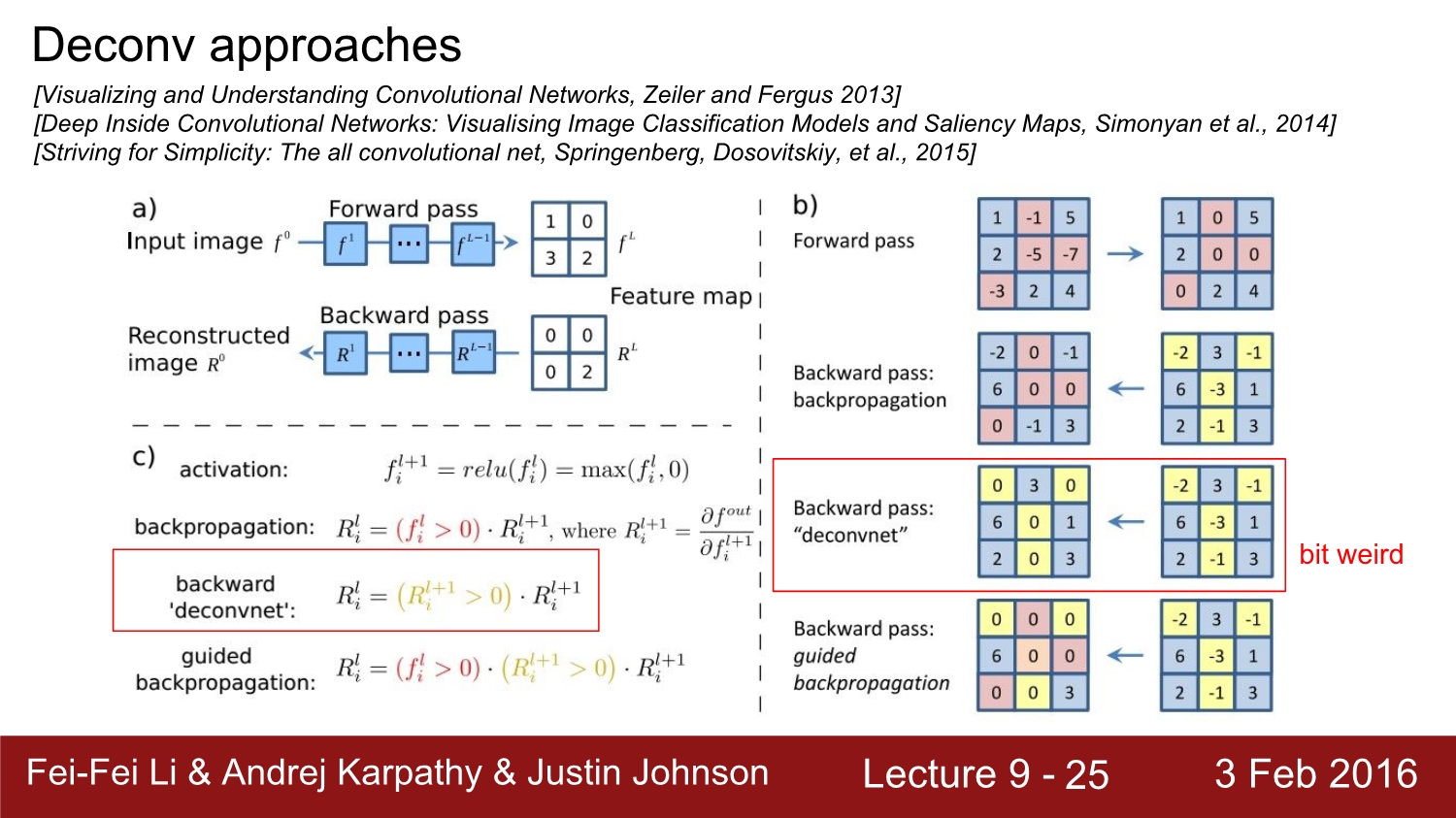
deconvnet부분을 보면 relu의 영향을 받지 않는 것을 볼 수 있다. relu와는 상관없이 모든 음수의 값들을 다 0으로 처리한다.
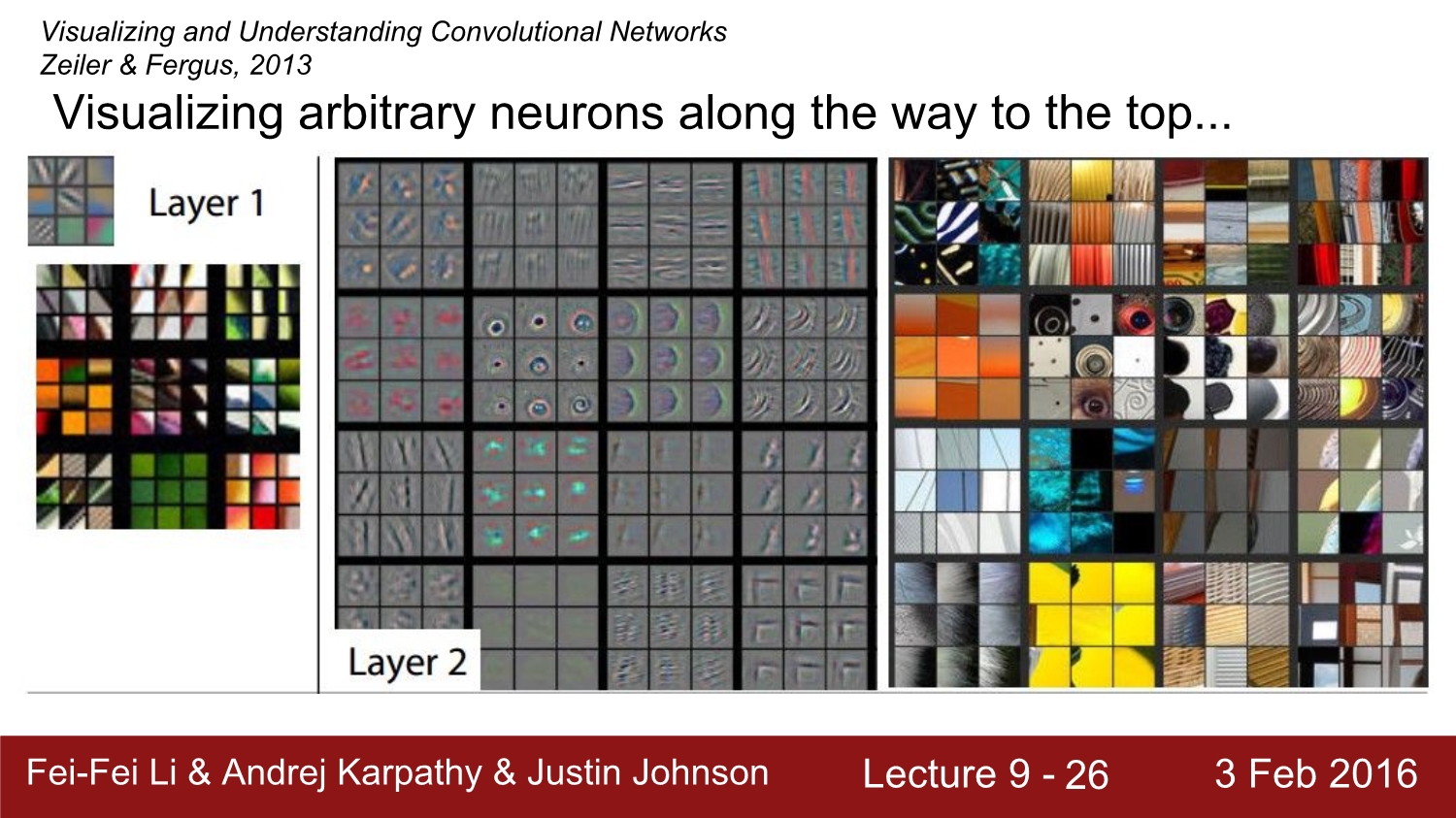


각 layer의 따른 output을 볼 수 있다.

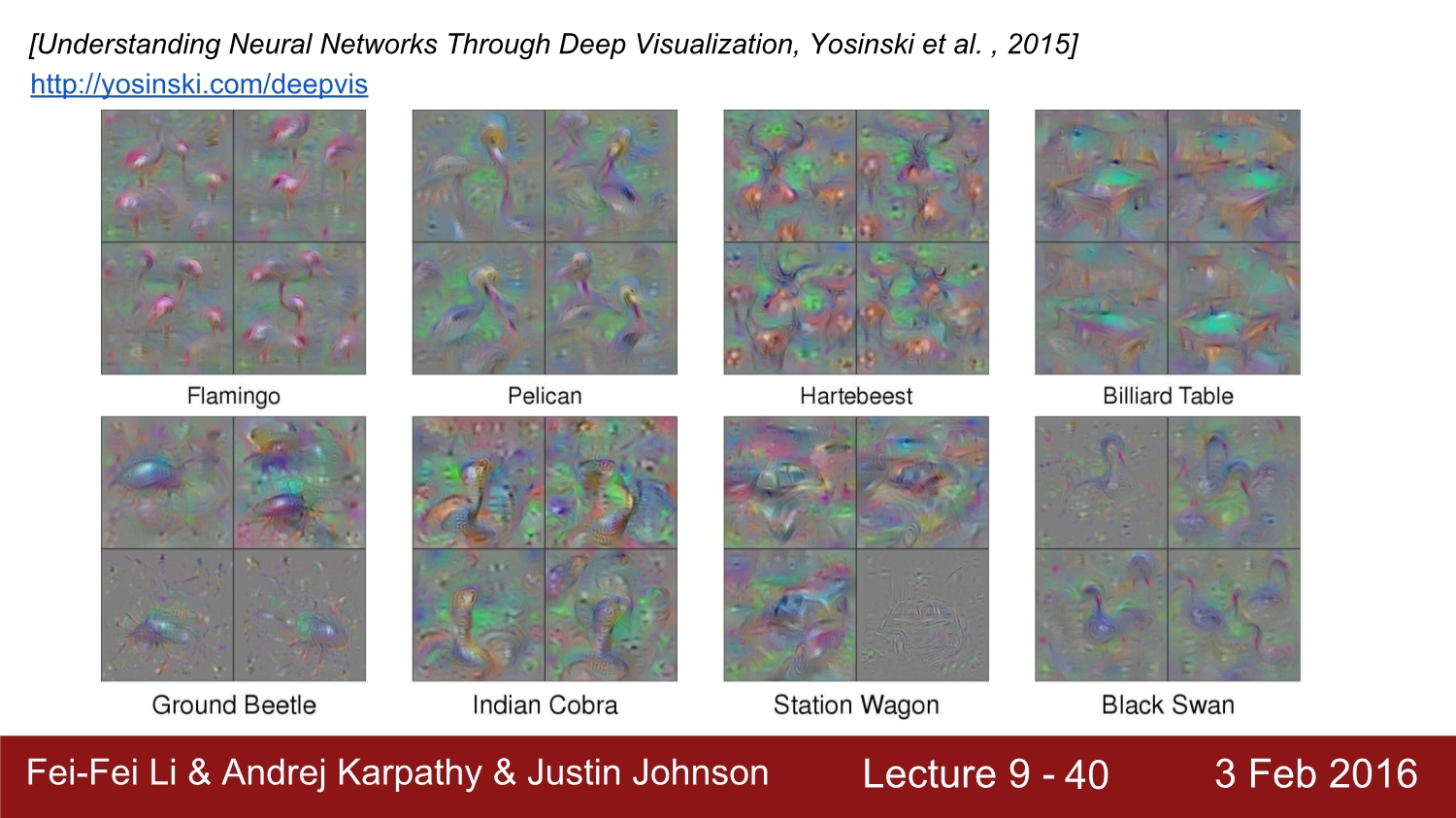
다음으로 살펴볼 방법은 optimization to image 방법이다. 이 방법은 다른 방법들보다는 조금 더 복잡하다. 전체적인 과정을 요약하면 image가 optimize 되는 대상이라고 생각하면 된다. weight는 fix 시켜두고 image를 update 한다고 생각하면 된다. 이는 특정 score의 class를 최적화시키는 방법이다.

왼쪽 위 수식에서 c가 최대화되는 인자를 찾으면 된다.

전체적인 방법은 우선 zero image를 network에 넣고 forward path를 진행한다. 중요한 것은 score vector에서 관심 있는 class만 1로 두고, 나머지는 모두 0으로 둔다. 그 후 backward path를 진행한다.


이에 따른 zero-image의 update 결과이다.

그다음은 data gradient의 시각화에 대해 알아보자. 우선 3개의 channel에 대해 squeeze를 해줌으로써 어떤 결과가 나오는지 확인할 수 있다. 예시로 설명하자면 강아지 이미지를 cnn model에 input으로 넣고, 강아지에 대한 값만 1로 설정한다. 그리고 backpropagation에 도달을 하는 순간에 rgb를 squeeze 해준다.

그러면 픽셀을 통해 각각의 영향력에 대한 척도를 확인할 수 있다.

또한 이를 활용하여 graph cut이라는 알고리즘을 적용하여 이미지를 segmentation화 시킬 수 있다. 하지만 실제로 결과는 제대로 나오지 않는다고 한다.

conv net에 과정에서 임의의 뉴런에 대해서도 실행을 할 수 있다. 관심이 있는 뉴런만 1.0으로 설정을 하면 된다.

이미지 자체를 blur를 하게 된다면 더욱 성능이 향상된다고 한다.


이에 대한 결과에서 조금 더 선명해진 것을 볼 수 있다.

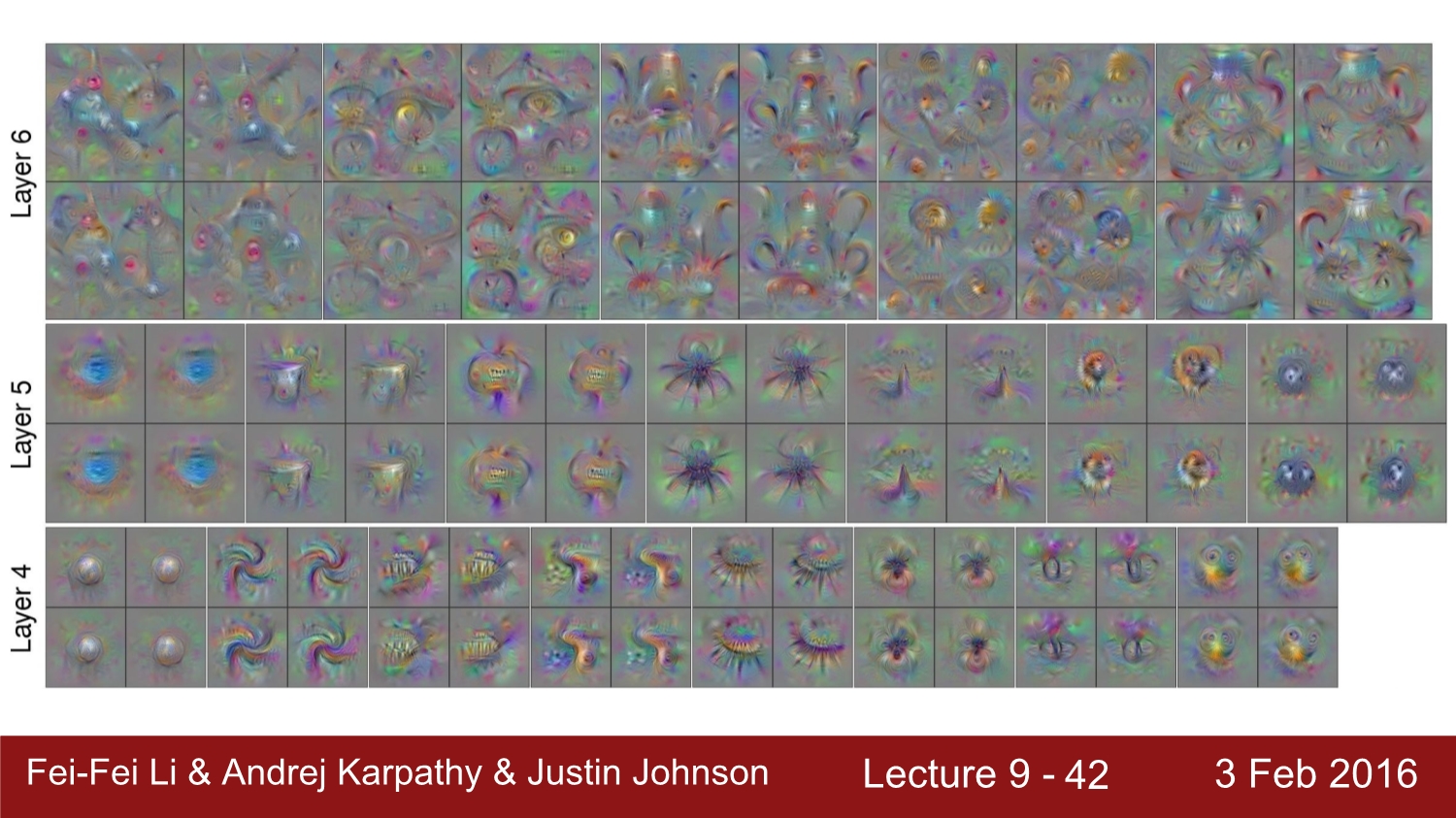
여기서 질문. CNN에서 코드가 주어졌을 때 원래 이미지를 복원할 수 있을까? (FC 4096차원 layer에서)

우선 해당 코드가 주어진 코드와 유사해야 되고, 아래와 같이 차이를 최소화시키는 함수를 사용하면 된다. 이 과정에서 code에 대한 feature를 최대화해야 한다.


이는 원본 이미지와 비슷하게 복원을 시도한 image이다.

이는 또한 어떠한 conv layer에 관해서도 가능하다고 한다. 다만 더 앞단에 존재할수록 정확도가 더욱 커지는 것을 볼 수 있다.

다음은 goolge의 DeepDream에 대해 살펴보자

딥드림은 몇 줄 안 되는 코드로 구현이 된다. make_step이라는 함수의 호출을 통해 layer를 지정하게 된다.
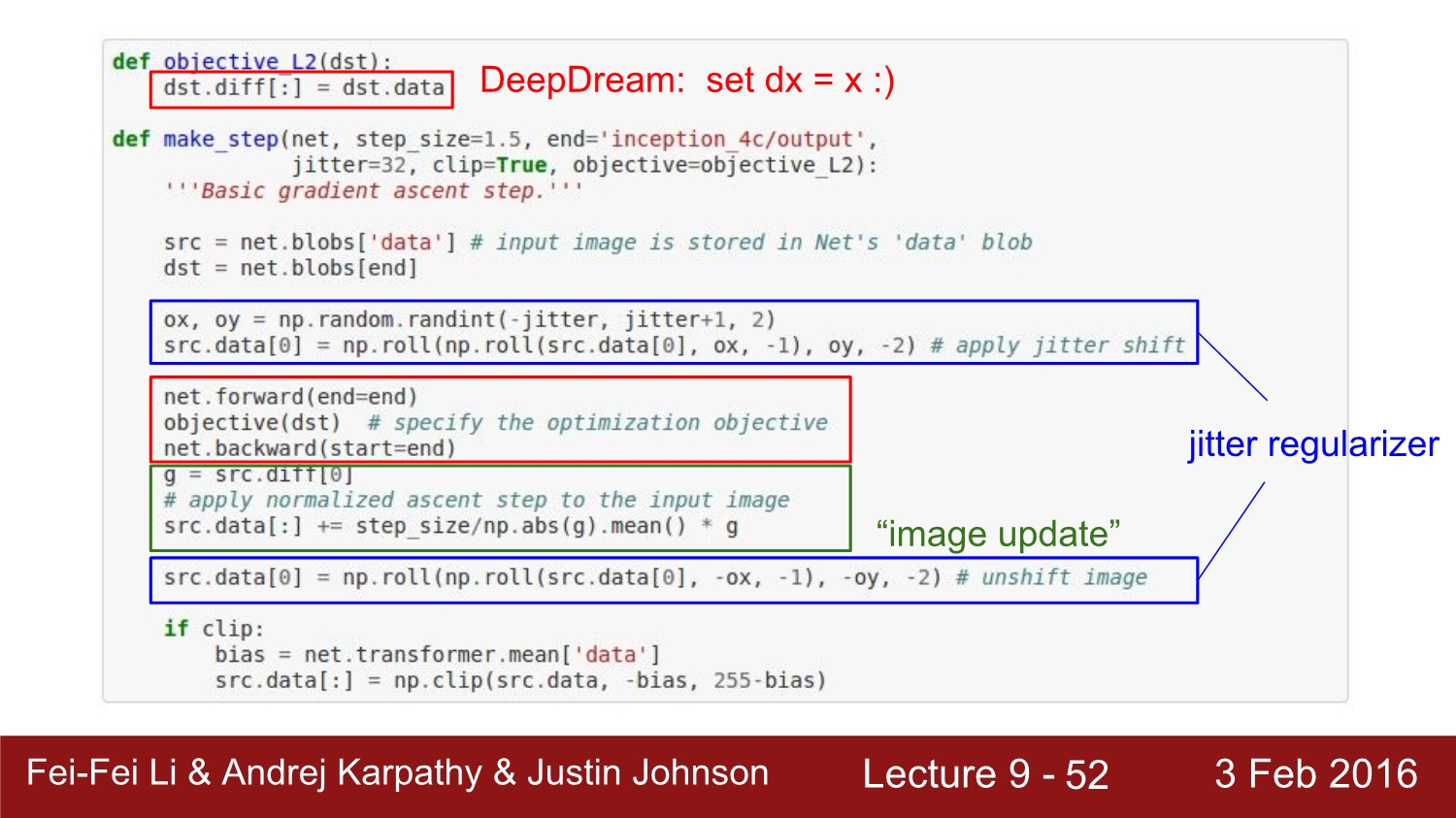
여기서 핵심은 빨간색 부분이다. 이 부분에서는 forward path를 제한하고, object를 호출하게 된다. caffe에서는 blob을 사용하는데 blob을 통해 diff field와 data에 대해 알 수 있다. diff는 기울기에 관한 정보를 담고 있고, data는 raw activation 정보를 담고 있다.
이 2개를 사용하여 가지고 있는 정보를 넘겨주고, dx를 x로 두는 것이 핵심이다. 그러고 나서 backward를 진행하고 이를 normalize 해서 cripping을 진행한다. 여기서 activation은 relu를 사용하는데 모든 activation에 있어서 연산을 하게 된다.

결괏값은 이와 같이 나오게 된다. 이미지에 강아지 사진이 많은 이유는 image net의 1000개의 class 중 200개가 강아지에 관련된 class이기 때문이다.

확대한 사진

다음은 뉴럴 스타일에 대해 알아보자. 보이는 것처럼 이미지가 마치 피카소의 그림처럼 합성되어 나온다.

예시 사진

이는 과연 어떤 방식으로 동작할까? 우선 image를 cnn에 넣고, 각각의 layer에서 raw activation을 저장한다.

다음에는 style image도 cnn에 넣게 되는데 여기서는 pair wise statics에서 gram matrics를 사용한다.
244*244 배열로 묶어주고 outer product와 sum up을 해주면 64*64의 gram matrix를 생성하게 된다.
이후 왼쪽에 있는 수식과 같이 activation transpose와 activation을 곱해주면 우리는 64*64의 행렬을 얻게 된다. 이 행렬은 공분산 행렬의 특징을 가지고 있다.

다음 step에서는 여기서 나온 loss를 가지고 위 수식과 같이 optimization을 해주면 된다.

만약에 우리가 이것을 사용하면 CNN을 속일 수 있을까? 정답은 속일 수 있다. 이걸 adversarial example이라고 부른다.

위 예시에서 버스에서는 타조 class만 1로 설정한다. 그리고 backpropagation을 진행하면 cnn은 이 버스를 타조로 분류하게 된다. 이처럼 어떤 사진이라도 이 방식으로 속일 수 있다. 다른 random noise도 가능하다.

더 나아가 패턴과 이러한 텍스쳐도 이상하게 인식을 할 수 있다.


이전에 사용된 알고리즘인 HOG를 사용해도 동일하게 인식한다고 한다.

2014년에 나온 논문에서는 뉴런 네트워크가 adversarial attack에 취약한 이유가 linear nature이기 때문이라고 한다.
이미지가 너무 고차원이고, 기울기는 최적화를 진행하면서 어떤 일이라도 진행해야 되기 때문에 저 차원 구조에서는 문제가 생길 수밖에 없다고 한다.

x와 w를 곱해서 모두 더하게 되면 결괏값은 0.0474가 나오게 된다. 이를 sigmoid에 넣으면 약 5%가 나오고, 0일 확률이 95%가 된다.

이제 adversial 즉 적대적인 x를 만들어 보자. 가중치가 양수인 경우에는 크게 만들고, 음수일 때에는 적게 만들면서 class를 1로 만들 수 있다.

이 경우에는 10개의 dimension인 경우인데 이미지 같은 경우에는 차원의 크기가 크다. 그래서 약간의 변화만 주더라도 속이기 훨씬 쉽니다. 그래서 linear regression은 아주 작은 변화만으로도 크게 변화시킬 수 있다. 이건 linear classifier 자체의 문제다.
아래를 통해서 관련된 예시를 보자

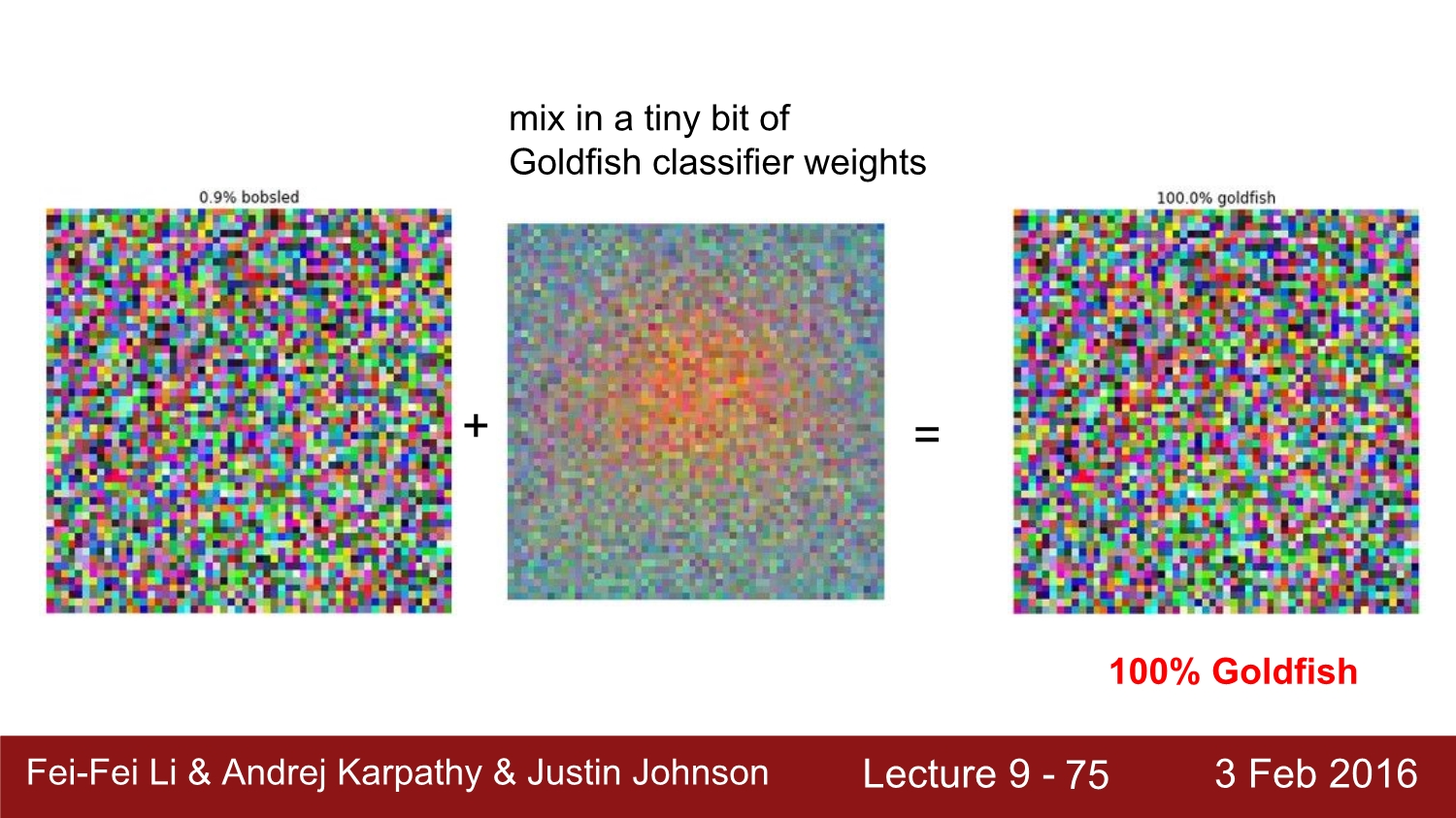


이처럼 조금의 noise만 주어도 cnn의 정확도는 매우 낮아진다.

방금 전에 말한 것처럼 이러한 문제점들의 주요 요인은 linear regression은 사용해서 발생하였다. 더 나아가서 이는 이미지에 국한되는 문제가 아니다. 모든 분야에서 발생할 수 있는 문제이고, 이를 막을 수 있는 정답은 아직까지는 존재하지 않는다. 대책으로는 class의 수가 많아지거나, adversial example을 의도적으로 넣어주고, negative로 넣어주면 된다. 하지만 근본적인 해결책이 아니다.
현재로써는 linear function을 빼면 공격에는 강해지지만 정확도 측면에서는 떨어지게 된다.
referance
http://cs231n.stanford.edu/2016/
https://www.youtube.com/watch?v=KT4iD6yiqwo
'study > cs231n' 카테고리의 다른 글
| Lecture 13: Segmentation (0) | 2020.04.27 |
|---|---|
| Lecture 11: CNNs in Practice (0) | 2020.04.22 |
| Lecture 8: Spatial Localization and Detection (0) | 2020.04.17 |
| Lecture 7: Convolutional Neural Networks (0) | 2020.04.16 |
| Lecture 6: Training Neural Networks, Part 2 (0) | 2020.04.13 |



