
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 서포트벡터머신이란
- TCP
- SVM 이란
- EfficientNet
- cs231n lecture5
- Deep Learning
- 데이터 전처리
- Object Detection
- DeepLearning
- Computer Vision
- SVM margin
- SVM hard margin
- 논문분석
- libtorch
- pytorch c++
- Faster R-CNN
- fast r-cnn
- CS231n
- RCNN
- pytorch
- svdd
- darknet
- cnn 역사
- support vector machine 리뷰
- self-supervision
- pytorch project
- CNN
- computervision
- yolov3
- yolo
- Today
- Total
아롱이 탐험대
Lecture 13: Segmentation 본문

드디어 cs231n의 마지막 chapter인 lecture13: segmentation and attention이다. lecture12는 각종 딥러닝 framework를 다루는 내용이라 스킵하겠다. 이번 시간에는 segmentation에 대해서 알아보자

기본적으로 segmentation은 크게 2가지 방식이 있다. 첫번째는 semantic segmentation이고 두 번째는 instance segmentation이다. semantic은 전통적인 방식을 가지고 있다. 기본적으로 one label per pixel이다. 모든 pixel은 class label을 가진다. 그래서 맨 왼쪽 소 그림처럼 각각의 object를 구분하지 못한다. 또한 class의 수는 fix 되어 있고 해당 class의 속하지 않으면 background로 둔다.

2번째 방법은 instance segmentation이다. 이는 우선 instance를 탐색한다. 그리고 instace pixel들을 labeling한다. 이를 통해 instance 간의 구분을 해준다. 이게 semantic과 instace의 근본적인 차이이다. instace는 또한 SDS라고도 불린다.

그럼 본격적으로 segmentation 기법들을 자세히 알아보자. 우선 semantic segmentation부터 알아보자

semantic의 기본적은 pipeline은 image가 들어 오면 특정 부분의 patch를 추출한 후 이를 CNN으로 학습시킨다. 그러고 나서 가운데에 있는 픽셀 (위에서는 가운데 동그라미 부분)이 어떤 class에 속하는지 classification 한다. 그 후 모든 patch에 대해 repeat 한다. 이런 방식은 모든 픽셀의 영역을 비교해야 되기 때문에 계산 비용이 많이 든다.

비용이 많은 것을 피하는 방법은 전체 pixel을 Fully-connected layer로 돌리는 것이다. 여기서는 image 자체를 CNN에 넣는다. 따라서 한 번에 계산을 진행할 수 있다. 하지만 문제점은 Conv의 pooling과 같은 것들 때문에 down sampling에 있어 output image가 작아지게 된다. 다음은 Semantic segmentation의 확장 version인 Multi-Scale에 대해 알아보자

우선 image를 다양한 scale로 resize 해준다. 여기서는 3개의 다른 scale로 resize 해주었다. 이를 image를 pyramid 쌓았다고 부른다.

다음은 각 scale별로 CNN학습을 진행한다.

그다음에는 이것들을 모두 원본과 같은 크기로 upsampling을 해주고, concatenate 해준다.

이외에는 별도로 offline processing이 필요한데 superpixel이나 tree를 사용한다. super pixel은 픽셀의 크기를 보고 크게 변화가 없으면 연관된 region으로 간주한다. Tree는 어떤 pixel들이 같이 merge 될지 결정해주는 tree이다. Bottom-up에서는 cnn에서 줄 수 없는 것들을 offline을 통해서 전달한다

최종적으로는 위와 아래를 combine 해준다. 결과적으로는 오른쪽과 같은 output이 나오게 된다.

두 번째 확장 버전은 refinement이다. 우선은 image를 rgb 분리를 해서 cnn을 돌린다.

그리고 나면 downsampling 된 결과가 나오게 된다. 이 과정을 계속 반복을 하고, 반복하는 동안 CNN이 우리의 parameter들을 sharing 하게 된다. rnn과 비슷하게 recurrent 한 방법이라고 할 수 있다. 논문에 의하면 이 반복이 많아질수록 결과가 좋아진다고 한다.

3번째 방법은 upsampling 방법이다. 2015년에 발표된 fully convolutional networks for semantic segmentation에 기재되어 있다. 이 방법은 feature 추출까지는 기존과 동일하다. 하지만 작아진 map을 복원해주는 upsampling에 있어서 이 부분도 network의 일부분으로 편입을 시켰다. 요약하자면 즉 마지막 layer도 학습이 가능해진다.

Fully connected layer는 2가지 특징을 가진다. 첫 번째는 upsampling이다. 이 방법은 뒤에서 알아보자. 두 번째는 skip connection이다. 추가적으로 conv 과정에서 초기일수록 feature map이 크다. 하지만 receptive field는 작아지게 된다. 이를 이용해서 초기의 pooling 과정에서 또 다른 conv feature map을 추출하는 것이다. 이렇게 추출된 3개를 뽑아서 combine 해준다. 이런 식으로 점점 명확해지는 모습을 볼 수 있다.

학습이 가능한 upsampling을 deconvolution이라고 부른다.

deconvolution은 convolution과정의 역 버전이라고 생각을 하면 된다. 예시로 3*3 stride:2, pad:1을 보자. input에서 output으로 가는 과정을 볼 때 겹치는 부분은 sum을 해준다. 앞서 말한 것처럼 deconv는 conv의 backward path라고 보아도 된다. 하지만 deconvolution이라는 이름은 부적절하다고 한다. 그 이유는 signal processing에서 미리 정의된 이름이기 때문이라고 한다.

보통의 segmentation model은 왼쪽에서는 일반적인 network를 사용하고, 오른쪽 부분은 반대로 된 network를 사용한다.

이제는 instance segmentation에 대해 알아보자. 이것은 비교적 최근에 연구가 되고 있는 방식이다.
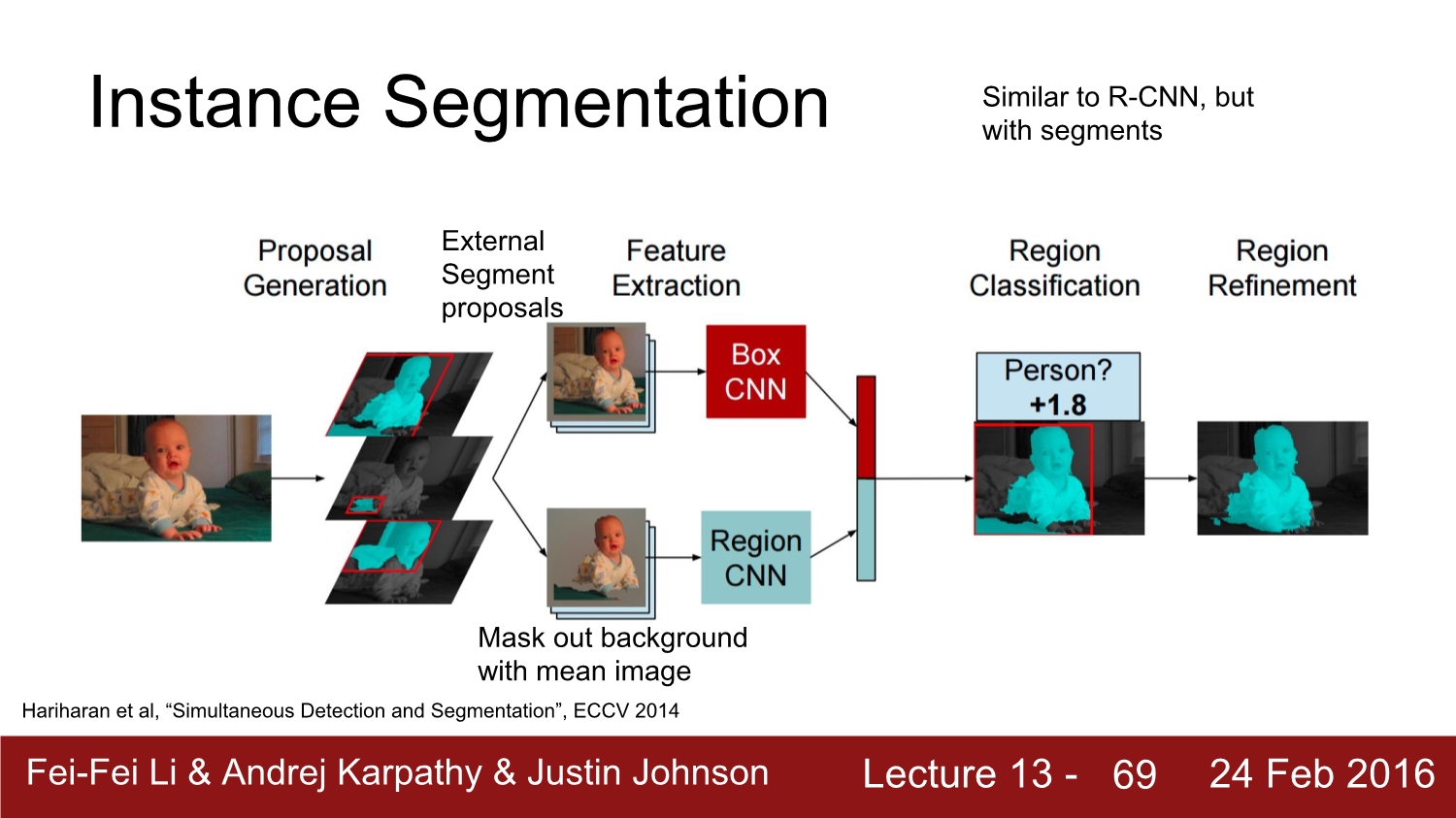
instance segmentation의 과정은 앞에서 배웠던 r-cnn과정과 유사하다. input을 받아서 offline으로 segmetation proposal을 진행한다. 이를 통해 각각의 feature를 뽑고 이를 box cnn을 통해 학습시킨다. 또 하나의 과정은 region cnn인데 둘 다 cropping하는 것은 동일하다. region에서는 mean color를 이용해 background를 제거한다. 그 후 둘다 combine 하여 region classification을 진행한다. 그리고 마지막으로는 region을 refine 하면서 다듬어준다.

이에 대한 많은 변형도 존재한다. Hypercolumns는 기존의 확장판이다.
원복 이미지를 crop 하고 alexnet으로 돌린다. 그리고 단계마다 upsampling을 진행한다. 이를 모아서 combine 해 이렇게 결과를 낸다. 각 독립된 픽셀에 대해 logistic을 진행하고 이 과정에서 각 픽셀이 물체인지 배경인지 구분한다.

또 다른 방법은 cascade이다. 이건 faster r-cnn과 유사하다. 이는 microsoft에서 낸 모델이다. coco에서 2015년 우승을 하였고, res net기반이다. 이미지 자체를 conv 시켜서 거대한 conv feature map을 생성 후에 region proposal을 그대로 이용한다. 또한 anchor box도 그대로 이용한다. 뽑은 크기가 서로 다르기 때문에 동일한 사이즈로 조절한 다음에 이를 fc layer로 보낸다. 그리고 logistic을 이용해서 mask를 생성한 다음 forground 값에 해당하는 값들만 건네준 다음 fc를 통해 background를 제거하며 결괏값을 낸다. 이는 end-to-end 방법이어서 모든 면에서 매우 좋다.

cascade 방법에 대한 결과이다.
referance
http://cs231n.stanford.edu/2016/
https://www.youtube.com/watch?v=KT4iD6yiqwo
'study > cs231n' 카테고리의 다른 글
| Lecture 11: CNNs in Practice (0) | 2020.04.22 |
|---|---|
| Lecture 9: Understanding and Visualizing Convolutional Neural Networks (0) | 2020.04.21 |
| Lecture 8: Spatial Localization and Detection (0) | 2020.04.17 |
| Lecture 7: Convolutional Neural Networks (0) | 2020.04.16 |
| Lecture 6: Training Neural Networks, Part 2 (0) | 2020.04.13 |



